 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Validation Tool for Designing Reinforcement Learning Environments
Paper and Code
Dec 10, 2021
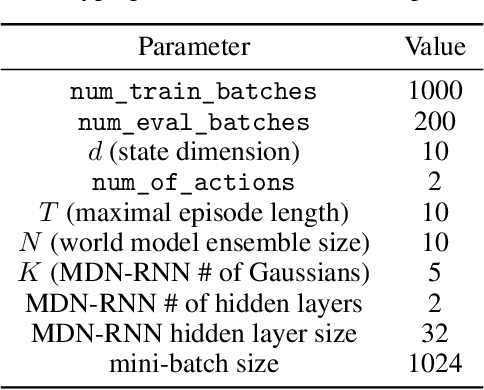
Reinforcement learning (RL) has gained increasing attraction in the academia and tech industry with launches to a variety of impactful applications and products. Although research is being actively conducted on many fronts (e.g., offline RL, performance, etc.), many RL practitioners face a challenge that has been largely ignored: determine whether a designed Markov Decision Process (MDP) is valid and meaningful. This study proposes a heuristic-based feature analysis method to validate whether an MDP is well formulated. We believe an MDP suitable for applying RL should contain a set of state features that are both sensitive to actions and predictive in rewards. We tested our method in constructed environments showing that our approach can identify certain invalid environment formulations. As far as we know, performing validity analysis for RL problem formulation is a novel direction. We envision that our tool will serve as a motivational example to help practitioners apply RL in real-world problems more easily.