 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTipiano: Cascaded Piano Hand Motion Synthesis via Fingertip Priors
Apr 06, 2026Synthesizing realistic piano hand motions requires both precision and naturalness. Physics-based methods achieve precision but produce stiff motions; data-driven models learn natural dynamics but struggle with positional accuracy. Piano motion exhibits a natural hierarchy: fingertip positions are nearly deterministic given piano geometry and fingering, while wrist and intermediate joints offer stylistic freedom. We present [OURS], a four-stage framework exploiting this hierarchy: (1) statistics-based fingertip positioning, (2) FiLM-conditioned trajectory refinement, (3) wrist estimation, and (4) STGCN-based pose synthesis. We contribute expert-annotated fingerings for the FürElise dataset (153 pieces, ~10 hours). Experiments demonstrate F1 = 0.910, substantially outperforming diffusion baselines (F1 = 0.121), with user study (N=41) confirming quality approaching motion capture. Expert evaluation by professional pianists (N=5) identified anticipatory motion as the key remaining gap, providing concrete directions for future improvement.
CMI-Bench: A Comprehensive Benchmark for Evaluating Music Instruction Following
Jun 14, 2025Recent advances in audio-text large language models (LLMs) have opened new possibilities for music understanding and generation. However, existing benchmarks are limited in scope, often relying on simplified tasks or multi-choice evaluations that fail to reflect the complexity of real-world music analysis. We reinterpret a broad range of traditional MIR annotations as instruction-following formats and introduce CMI-Bench, a comprehensive music instruction following benchmark designed to evaluate audio-text LLMs on a diverse set of music information retrieval (MIR) tasks. These include genre classification, emotion regression, emotion tagging, instrument classification, pitch estimation, key detection, lyrics transcription, melody extraction, vocal technique recognition, instrument performance technique detection, music tagging, music captioning, and (down)beat tracking: reflecting core challenges in MIR research. Unlike previous benchmarks, CMI-Bench adopts standardized evaluation metrics consistent with previous state-of-the-art MIR models, ensuring direct comparability with supervised approaches. We provide an evaluation toolkit supporting all open-source audio-textual LLMs, including LTU, Qwen-audio, SALMONN, MusiLingo, etc. Experiment results reveal significant performance gaps between LLMs and supervised models, along with their culture, chronological and gender bias, highlighting the potential and limitations of current models in addressing MIR tasks. CMI-Bench establishes a unified foundation for evaluating music instruction following, driving progress in music-aware LLMs.
RenderBox: Expressive Performance Rendering with Text Control
Feb 11, 2025Expressive music performance rendering involves interpreting symbolic scores with variations in timing, dynamics, articulation, and instrument-specific techniques, resulting in performances that capture musical can emotional intent. We introduce RenderBox, a unified framework for text-and-score controlled audio performance generation across multiple instruments, applying coarse-level controls through natural language descriptions and granular-level controls using music scores. Based on a diffusion transformer architecture and cross-attention joint conditioning, we propose a curriculum-based paradigm that trains from plain synthesis to expressive performance, gradually incorporating controllable factors such as speed, mistakes, and style diversity. RenderBox achieves high performance compared to baseline models across key metrics such as FAD and CLAP, and also tempo and pitch accuracy under different prompting tasks. Subjective evaluation further demonstrates that RenderBox is able to generate controllable expressive performances that sound natural and musically engaging, aligning well with prompts and intent.
A Data-Driven Analysis of Robust Automatic Piano Transcription
Feb 02, 2024



Algorithms for automatic piano transcription have improved dramatically in recent years due to new datasets and modeling techniques. Recent developments have focused primarily on adapting new neural network architectures, such as the Transformer and Perceiver, in order to yield more accurate systems. In this work, we study transcription systems from the perspective of their training data. By measuring their performance on out-of-distribution annotated piano data, we show how these models can severely overfit to acoustic properties of the training data. We create a new set of audio for the MAESTRO dataset, captured automatically in a professional studio recording environment via Yamaha Disklavier playback. Using various data augmentation techniques when training with the original and re-performed versions of the MAESTRO dataset, we achieve state-of-the-art note-onset accuracy of 88.4 F1-score on the MAPS dataset, without seeing any of its training data. We subsequently analyze these data augmentation techniques in a series of ablation studies to better understand their influence on the resulting models.
Loop Copilot: Conducting AI Ensembles for Music Generation and Iterative Editing
Oct 19, 2023

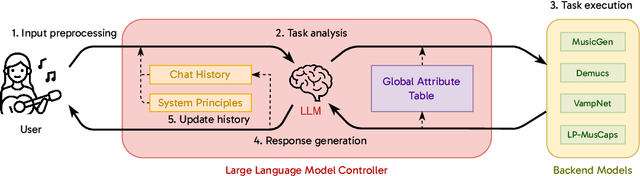

Creating music is iterative, requiring varied methods at each stage. However, existing AI music systems fall short in orchestrating multiple subsystems for diverse needs. To address this gap, we introduce Loop Copilot, a novel system that enables users to generate and iteratively refine music through an interactive, multi-round dialogue interface. The system uses a large language model to interpret user intentions and select appropriate AI models for task execution. Each backend model is specialized for a specific task, and their outputs are aggregated to meet the user's requirements. To ensure musical coherence, essential attributes are maintained in a centralized table. We evaluate the effectiveness of the proposed system through semi-structured interviews and questionnaires, highlighting its utility not only in facilitating music creation but also its potential for broader applications.