 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducible Synthetic Clinical Letters for Seizure Frequency Information Extraction
Mar 12, 2026Seizure-frequency information is important for epilepsy research and clinical care, but it is usually recorded in variable free-text clinic letters that are hard to annotate and share. We developed a reproducible, privacy-preserving framework for extracting seizure frequency using fully synthetic yet task-faithful epilepsy letters. We defined a structured label scheme covering common descriptions of seizure burden, including explicit rates, ranges, clusters, seizure-free intervals, unknown frequency, and explicit no-seizure statements. A teacher language model generated NHS-style synthetic letters paired with normalized labels, rationales, and evidence spans. We fine-tuned several open-weight language models (4B-14B parameters) on these synthetic letters to extract seizure frequency from full documents, comparing direct numeric prediction with structured label prediction and testing evidence-grounded outputs. On a clinician-checked held-out set of real clinic letters, models trained only on synthetic data generalized well, and structured labels consistently outperformed direct numeric regression. With 15,000 synthetic training letters, models achieved micro-F1 scores up to 0.788 for fine-grained categories and 0.847 for pragmatic categories; a medically oriented 4B model achieved 0.787 and 0.858, respectively. Evidence-grounded outputs also supported rapid clinical verification and error analysis. These results show that synthetic, structured, evidence-grounded supervision can enable robust seizure-frequency extraction without sharing sensitive patient text and may generalize to other temporally complex clinical information extraction tasks.
Fine-Refine: Iterative Fine-grained Refinement for Mitigating Dialogue Hallucination
Feb 17, 2026The tendency for hallucination in current large language models (LLMs) negatively impacts dialogue systems. Such hallucinations produce factually incorrect responses that may mislead users and undermine system trust. Existing refinement methods for dialogue systems typically operate at the response level, overlooking the fact that a single response may contain multiple verifiable or unverifiable facts. To address this gap, we propose Fine-Refine, a fine-grained refinement framework that decomposes responses into atomic units, verifies each unit using external knowledge, assesses fluency via perplexity, and iteratively corrects granular errors. We evaluate factuality across the HybriDialogue and OpendialKG datasets in terms of factual accuracy (fact score) and coverage (Not Enough Information Proportion), and experiments show that Fine-Refine substantially improves factuality, achieving up to a 7.63-point gain in dialogue fact score, with a small trade-off in dialogue quality.
Seeing the Forest and the Trees: Query-Aware Tokenizer for Long-Video Multimodal Language Models
Nov 14, 2025Despite the recent advances in the video understanding ability of multimodal large language models (MLLMs), long video understanding remains a challenge. One of the main issues is that the number of vision tokens grows linearly with video length, which causes an explosion in attention cost, memory, and latency. To solve this challenge, we present Query-aware Token Selector (\textbf{QTSplus}), a lightweight yet powerful visual token selection module that serves as an information gate between the vision encoder and LLMs. Given a text query and video tokens, QTSplus dynamically selects the most important visual evidence for the input text query by (i) scoring visual tokens via cross-attention, (ii) \emph{predicting} an instance-specific retention budget based on the complexity of the query, and (iii) \emph{selecting} Top-$n$ tokens with a differentiable straight-through estimator during training and a hard gate at inference. Furthermore, a small re-encoder preserves temporal order using absolute time information, enabling second-level localization while maintaining global coverage. Integrated into Qwen2.5-VL, QTSplus compresses the vision stream by up to \textbf{89\%} and reduces end-to-end latency by \textbf{28\%} on long videos. The evaluation on eight long video understanding benchmarks shows near-parity accuracy overall when compared with the original Qwen models and outperforms the original model by \textbf{+20.5} and \textbf{+5.6} points respectively on TempCompass direction and order accuracies. These results show that QTSplus is an effective, general mechanism for scaling MLLMs to real-world long-video scenarios while preserving task-relevant evidence. We will make all code, data, and trained models' weights publicly available.
Improving Factuality for Dialogue Response Generation via Graph-Based Knowledge Augmentation
Jun 14, 2025



Large Language Models (LLMs) succeed in many natural language processing tasks. However, their tendency to hallucinate - generate plausible but inconsistent or factually incorrect text - can cause problems in certain tasks, including response generation in dialogue. To mitigate this issue, knowledge-augmented methods have shown promise in reducing hallucinations. Here, we introduce a novel framework designed to enhance the factuality of dialogue response generation, as well as an approach to evaluate dialogue factual accuracy. Our framework combines a knowledge triple retriever, a dialogue rewrite, and knowledge-enhanced response generation to produce more accurate and grounded dialogue responses. To further evaluate generated responses, we propose a revised fact score that addresses the limitations of existing fact-score methods in dialogue settings, providing a more reliable assessment of factual consistency. We evaluate our methods using different baselines on the OpendialKG and HybriDialogue datasets. Our methods significantly improve factuality compared to other graph knowledge-augmentation baselines, including the state-of-the-art G-retriever. The code will be released on GitHub.
ClarQ-LLM: A Benchmark for Models Clarifying and Requesting Information in Task-Oriented Dialog
Sep 09, 2024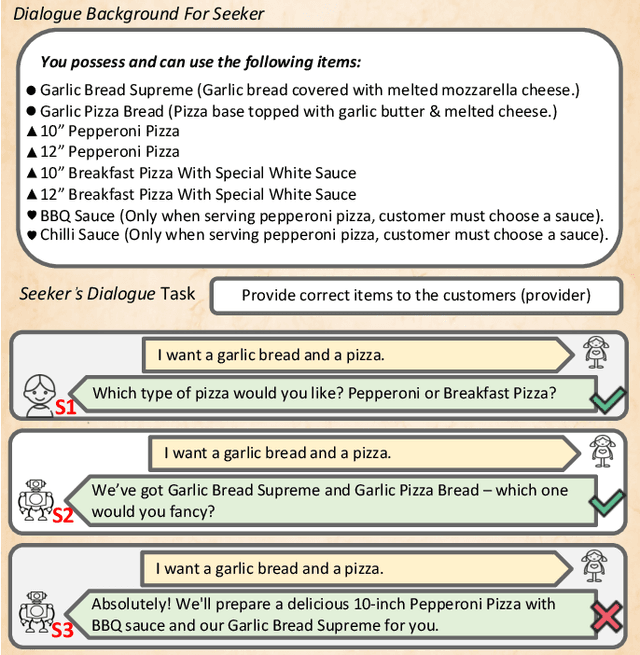



We introduce ClarQ-LLM, an evaluation framework consisting of bilingual English-Chinese conversation tasks, conversational agents and evaluation metrics, designed to serve as a strong benchmark for assessing agents' ability to ask clarification questions in task-oriented dialogues. The benchmark includes 31 different task types, each with 10 unique dialogue scenarios between information seeker and provider agents. The scenarios require the seeker to ask questions to resolve uncertainty and gather necessary information to complete tasks. Unlike traditional benchmarks that evaluate agents based on fixed dialogue content, ClarQ-LLM includes a provider conversational agent to replicate the original human provider in the benchmark. This allows both current and future seeker agents to test their ability to complete information gathering tasks through dialogue by directly interacting with our provider agent. In tests, LLAMA3.1 405B seeker agent managed a maximum success rate of only 60.05\%, showing that ClarQ-LLM presents a strong challenge for future research.
Measuring and Improving Compositional Generalization in Text-to-SQL via Component Alignment
May 04, 2022



In text-to-SQL tasks -- as in much of NLP -- compositional generalization is a major challenge: neural networks struggle with compositional generalization where training and test distributions differ. However, most recent attempts to improve this are based on word-level synthetic data or specific dataset splits to generate compositional biases. In this work, we propose a clause-level compositional example generation method. We first split the sentences in the Spider text-to-SQL dataset into sub-sentences, annotating each sub-sentence with its corresponding SQL clause, resulting in a new dataset Spider-SS. We then construct a further dataset, Spider-CG, by composing Spider-SS sub-sentences in different combinations, to test the ability of models to generalize compositionally. Experiments show that existing models suffer significant performance degradation when evaluated on Spider-CG, even though every sub-sentence is seen during training. To deal with this problem, we modify a number of state-of-the-art models to train on the segmented data of Spider-SS, and we show that this method improves the generalization performance.
Exploring Underexplored Limitations of Cross-Domain Text-to-SQL Generalization
Sep 11, 2021

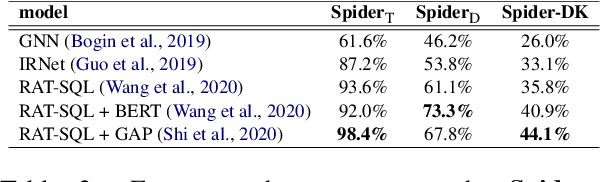
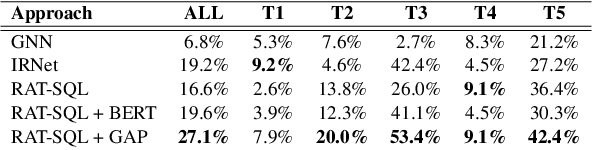
Recently, there has been significant progress in studying neural networks for translating text descriptions into SQL queries under the zero-shot cross-domain setting. Despite achieving good performance on some public benchmarks, we observe that existing text-to-SQL models do not generalize when facing domain knowledge that does not frequently appear in the training data, which may render the worse prediction performance for unseen domains. In this work, we investigate the robustness of text-to-SQL models when the questions require rarely observed domain knowledge. In particular, we define five types of domain knowledge and introduce Spider-DK (DK is the abbreviation of domain knowledge), a human-curated dataset based on the Spider benchmark for text-to-SQL translation. NL questions in Spider-DK are selected from Spider, and we modify some samples by adding domain knowledge that reflects real-world question paraphrases. We demonstrate that the prediction accuracy dramatically drops on samples that require such domain knowledge, even if the domain knowledge appears in the training set, and the model provides the correct predictions for related training samples.
Natural SQL: Making SQL Easier to Infer from Natural Language Specifications
Sep 11, 2021



Addressing the mismatch between natural language descriptions and the corresponding SQL queries is a key challenge for text-to-SQL translation. To bridge this gap, we propose an SQL intermediate representation (IR) called Natural SQL (NatSQL). Specifically, NatSQL preserves the core functionalities of SQL, while it simplifies the queries as follows: (1) dispensing with operators and keywords such as GROUP BY, HAVING, FROM, JOIN ON, which are usually hard to find counterparts for in the text descriptions; (2) removing the need for nested subqueries and set operators; and (3) making schema linking easier by reducing the required number of schema items. On Spider, a challenging text-to-SQL benchmark that contains complex and nested SQL queries, we demonstrate that NatSQL outperforms other IRs, and significantly improves the performance of several previous SOTA models. Furthermore, for existing models that do not support executable SQL generation, NatSQL easily enables them to generate executable SQL queries, and achieves the new state-of-the-art execution accuracy.
Towards Robustness of Text-to-SQL Models against Synonym Substitution
Jun 19, 2021
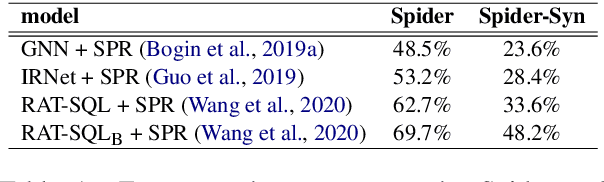
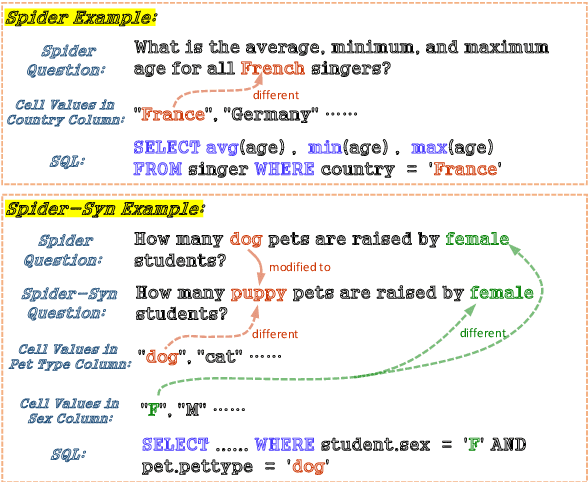
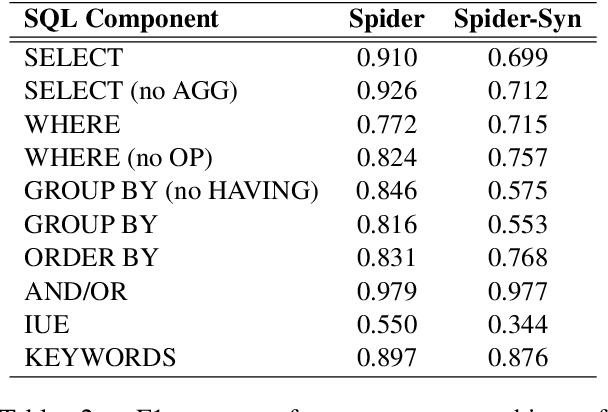
Recently, there has been significant progress in studying neural networks to translate text descriptions into SQL queries. Despite achieving good performance on some public benchmarks, existing text-to-SQL models typically rely on the lexical matching between words in natural language (NL) questions and tokens in table schemas, which may render the models vulnerable to attacks that break the schema linking mechanism. In this work, we investigate the robustness of text-to-SQL models to synonym substitution. In particular, we introduce Spider-Syn, a human-curated dataset based on the Spider benchmark for text-to-SQL translation. NL questions in Spider-Syn are modified from Spider, by replacing their schema-related words with manually selected synonyms that reflect real-world question paraphrases. We observe that the accuracy dramatically drops by eliminating such explicit correspondence between NL questions and table schemas, even if the synonyms are not adversarially selected to conduct worst-case adversarial attacks. Finally, we present two categories of approaches to improve the model robustness. The first category of approaches utilizes additional synonym annotations for table schemas by modifying the model input, while the second category is based on adversarial training. We demonstrate that both categories of approaches significantly outperform their counterparts without the defense, and the first category of approaches are more effective.