 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Framework For Deep Learning based CSI Feedback
Oct 18, 2022



Deep learning (DL) based channel state information (CSI) feedback in multiple-input multiple-output (MIMO) systems recently has attracted lots of attention from both academia and industrial. From a practical point of views, it is huge burden to train, transfer and deploy a DL model for each parameter configuration of the base station (BS). In this paper, we propose a scalable and flexible framework for DL based CSI feedback referred as scalable CsiNet (SCsiNet) to adapt a family of configured parameters such as feedback payloads, MIMO channel ranks, antenna numbers. To reduce model size and training complexity, the core block with pre-processing and post-processing in SCsiNet is reused among different parameter configurations as much as possible which is totally different from configuration-orienting design. The preprocessing and post-processing are trainable neural network layers introduced for matching input/output dimensions and probability distributions. The proposed SCsiNet is evaluated by metrics of squared generalized cosine similarity (SGCS) and user throughput (UPT) in system level simulations. Compared to existing schemes (configuration-orienting DL schemes and 3GPP Rel-16 Type-II codebook based schemes), the proposed scheme can significantly reduce mode size and achieve 2%-10% UPT improvement for all parameter configurations.
Measuring and Improving Compositional Generalization in Text-to-SQL via Component Alignment
May 04, 2022



In text-to-SQL tasks -- as in much of NLP -- compositional generalization is a major challenge: neural networks struggle with compositional generalization where training and test distributions differ. However, most recent attempts to improve this are based on word-level synthetic data or specific dataset splits to generate compositional biases. In this work, we propose a clause-level compositional example generation method. We first split the sentences in the Spider text-to-SQL dataset into sub-sentences, annotating each sub-sentence with its corresponding SQL clause, resulting in a new dataset Spider-SS. We then construct a further dataset, Spider-CG, by composing Spider-SS sub-sentences in different combinations, to test the ability of models to generalize compositionally. Experiments show that existing models suffer significant performance degradation when evaluated on Spider-CG, even though every sub-sentence is seen during training. To deal with this problem, we modify a number of state-of-the-art models to train on the segmented data of Spider-SS, and we show that this method improves the generalization performance.
Towards Robustness of Text-to-SQL Models against Synonym Substitution
Jun 19, 2021
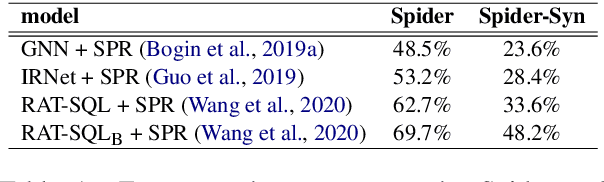
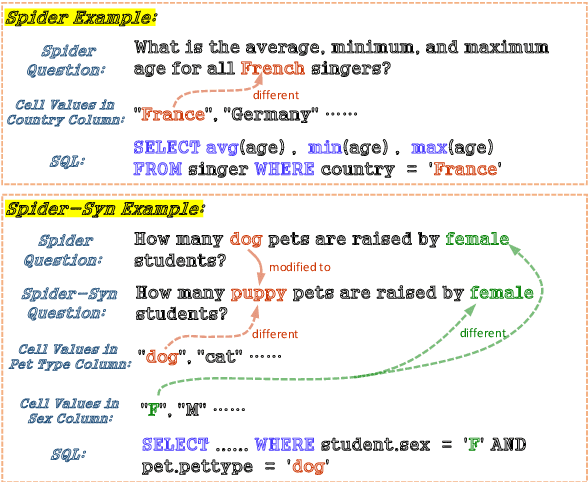
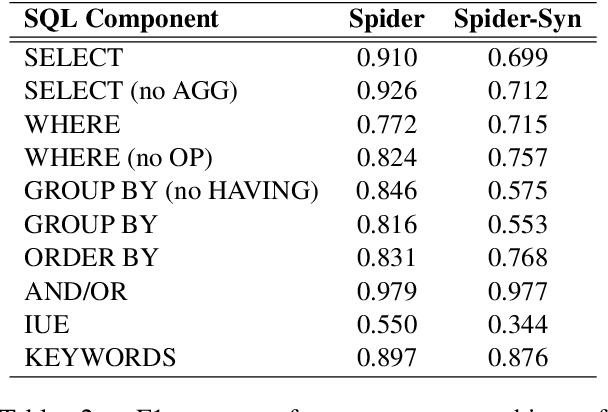
Recently, there has been significant progress in studying neural networks to translate text descriptions into SQL queries. Despite achieving good performance on some public benchmarks, existing text-to-SQL models typically rely on the lexical matching between words in natural language (NL) questions and tokens in table schemas, which may render the models vulnerable to attacks that break the schema linking mechanism. In this work, we investigate the robustness of text-to-SQL models to synonym substitution. In particular, we introduce Spider-Syn, a human-curated dataset based on the Spider benchmark for text-to-SQL translation. NL questions in Spider-Syn are modified from Spider, by replacing their schema-related words with manually selected synonyms that reflect real-world question paraphrases. We observe that the accuracy dramatically drops by eliminating such explicit correspondence between NL questions and table schemas, even if the synonyms are not adversarially selected to conduct worst-case adversarial attacks. Finally, we present two categories of approaches to improve the model robustness. The first category of approaches utilizes additional synonym annotations for table schemas by modifying the model input, while the second category is based on adversarial training. We demonstrate that both categories of approaches significantly outperform their counterparts without the defense, and the first category of approaches are more effective.