 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Framework For Deep Learning based CSI Feedback
Oct 18, 2022



Deep learning (DL) based channel state information (CSI) feedback in multiple-input multiple-output (MIMO) systems recently has attracted lots of attention from both academia and industrial. From a practical point of views, it is huge burden to train, transfer and deploy a DL model for each parameter configuration of the base station (BS). In this paper, we propose a scalable and flexible framework for DL based CSI feedback referred as scalable CsiNet (SCsiNet) to adapt a family of configured parameters such as feedback payloads, MIMO channel ranks, antenna numbers. To reduce model size and training complexity, the core block with pre-processing and post-processing in SCsiNet is reused among different parameter configurations as much as possible which is totally different from configuration-orienting design. The preprocessing and post-processing are trainable neural network layers introduced for matching input/output dimensions and probability distributions. The proposed SCsiNet is evaluated by metrics of squared generalized cosine similarity (SGCS) and user throughput (UPT) in system level simulations. Compared to existing schemes (configuration-orienting DL schemes and 3GPP Rel-16 Type-II codebook based schemes), the proposed scheme can significantly reduce mode size and achieve 2%-10% UPT improvement for all parameter configurations.
Accurate Deep Direct Geo-Localization from Ground Imagery and Phone-Grade GPS
Apr 20, 2018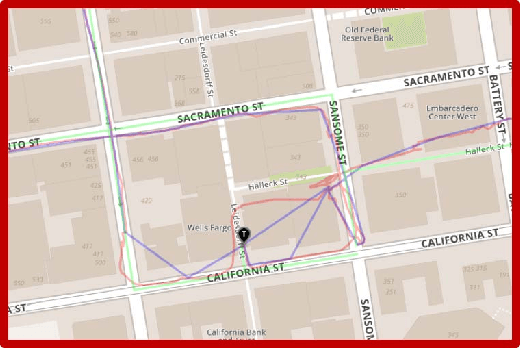

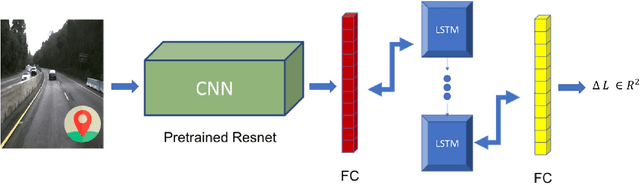

One of the most critical topics in autonomous driving or ride-sharing technology is to accurately localize vehicles in the world frame. In addition to common multi-view camera systems, it usually also relies on industrial grade sensors, such as LiDAR, differential GPS, high precision IMU, and etc. In this paper, we develop an approach to provide an effective solution to this problem. We propose a method to train a geo-spatial deep neural network (CNN+LSTM) to predict accurate geo-locations (latitude and longitude) using only ordinary ground imagery and low accuracy phone-grade GPS. We evaluate our approach on the open dataset released during ACM Multimedia 2017 Grand Challenge. Having ground truth locations for training, we are able to reach nearly lane-level accuracy. We also evaluate the proposed method on our own collected images in San Francisco downtown area often described as "downtown canyon" where consumer GPS signals are extremely inaccurate. The results show the model can predict quality locations that suffice in real business applications, such as ride-sharing, only using phone-grade GPS. Unlike classic visual localization or recent PoseNet-like methods that may work well in indoor environments or small-scale outdoor environments, we avoid using a map or an SFM (structure-from-motion) model at all. More importantly, the proposed method can be scaled up without concerns over the potential failure of 3D reconstruction.