 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Tracking via Mamba-based Context-aware Token Learning
Dec 18, 2024



How to make a good trade-off between performance and computational cost is crucial for a tracker. However, current famous methods typically focus on complicated and time-consuming learning that combining temporal and appearance information by input more and more images (or features). Consequently, these methods not only increase the model's computational source and learning burden but also introduce much useless and potentially interfering information. To alleviate the above issues, we propose a simple yet robust tracker that separates temporal information learning from appearance modeling and extracts temporal relations from a set of representative tokens rather than several images (or features). Specifically, we introduce one track token for each frame to collect the target's appearance information in the backbone. Then, we design a mamba-based Temporal Module for track tokens to be aware of context by interacting with other track tokens within a sliding window. This module consists of a mamba layer with autoregressive characteristic and a cross-attention layer with strong global perception ability, ensuring sufficient interaction for track tokens to perceive the appearance changes and movement trends of the target. Finally, track tokens serve as a guidance to adjust the appearance feature for the final prediction in the head. Experiments show our method is effective and achieves competitive performance on multiple benchmarks at a real-time speed. Code and trained models will be available at https://github.com/GXNU-ZhongLab/TemTrack.
ClarQ-LLM: A Benchmark for Models Clarifying and Requesting Information in Task-Oriented Dialog
Sep 09, 2024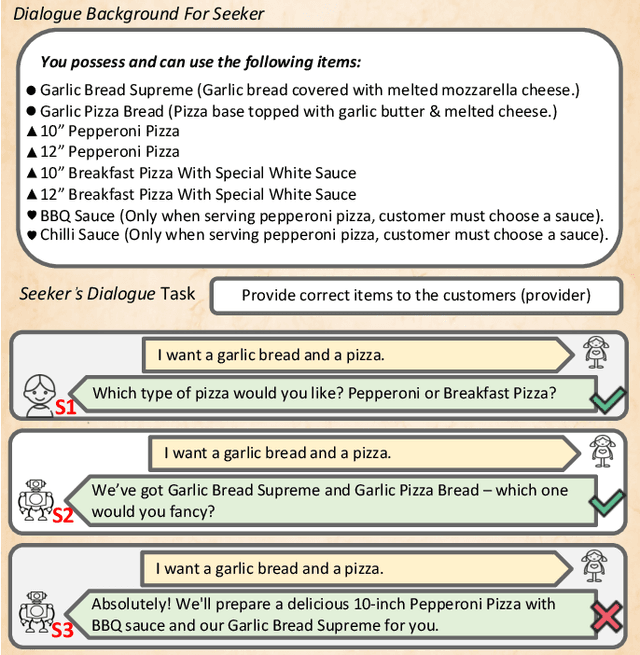



We introduce ClarQ-LLM, an evaluation framework consisting of bilingual English-Chinese conversation tasks, conversational agents and evaluation metrics, designed to serve as a strong benchmark for assessing agents' ability to ask clarification questions in task-oriented dialogues. The benchmark includes 31 different task types, each with 10 unique dialogue scenarios between information seeker and provider agents. The scenarios require the seeker to ask questions to resolve uncertainty and gather necessary information to complete tasks. Unlike traditional benchmarks that evaluate agents based on fixed dialogue content, ClarQ-LLM includes a provider conversational agent to replicate the original human provider in the benchmark. This allows both current and future seeker agents to test their ability to complete information gathering tasks through dialogue by directly interacting with our provider agent. In tests, LLAMA3.1 405B seeker agent managed a maximum success rate of only 60.05\%, showing that ClarQ-LLM presents a strong challenge for future research.
Autoregressive Queries for Adaptive Tracking with Spatio-TemporalTransformers
Mar 15, 2024The rich spatio-temporal information is crucial to capture the complicated target appearance variations in visual tracking. However, most top-performing tracking algorithms rely on many hand-crafted components for spatio-temporal information aggregation. Consequently, the spatio-temporal information is far away from being fully explored. To alleviate this issue, we propose an adaptive tracker with spatio-temporal transformers (named AQATrack), which adopts simple autoregressive queries to effectively learn spatio-temporal information without many hand-designed components. Firstly, we introduce a set of learnable and autoregressive queries to capture the instantaneous target appearance changes in a sliding window fashion. Then, we design a novel attention mechanism for the interaction of existing queries to generate a new query in current frame. Finally, based on the initial target template and learnt autoregressive queries, a spatio-temporal information fusion module (STM) is designed for spatiotemporal formation aggregation to locate a target object. Benefiting from the STM, we can effectively combine the static appearance and instantaneous changes to guide robust tracking. Extensive experiments show that our method significantly improves the tracker's performance on six popular tracking benchmarks: LaSOT, LaSOText, TrackingNet, GOT-10k, TNL2K, and UAV123.
Natural SQL: Making SQL Easier to Infer from Natural Language Specifications
Sep 11, 2021



Addressing the mismatch between natural language descriptions and the corresponding SQL queries is a key challenge for text-to-SQL translation. To bridge this gap, we propose an SQL intermediate representation (IR) called Natural SQL (NatSQL). Specifically, NatSQL preserves the core functionalities of SQL, while it simplifies the queries as follows: (1) dispensing with operators and keywords such as GROUP BY, HAVING, FROM, JOIN ON, which are usually hard to find counterparts for in the text descriptions; (2) removing the need for nested subqueries and set operators; and (3) making schema linking easier by reducing the required number of schema items. On Spider, a challenging text-to-SQL benchmark that contains complex and nested SQL queries, we demonstrate that NatSQL outperforms other IRs, and significantly improves the performance of several previous SOTA models. Furthermore, for existing models that do not support executable SQL generation, NatSQL easily enables them to generate executable SQL queries, and achieves the new state-of-the-art execution accuracy.
Towards Robustness of Text-to-SQL Models against Synonym Substitution
Jun 19, 2021
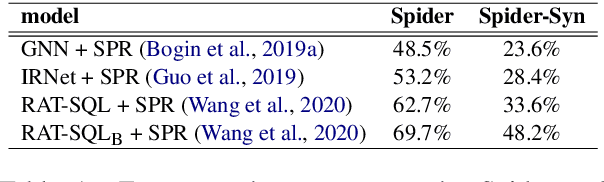
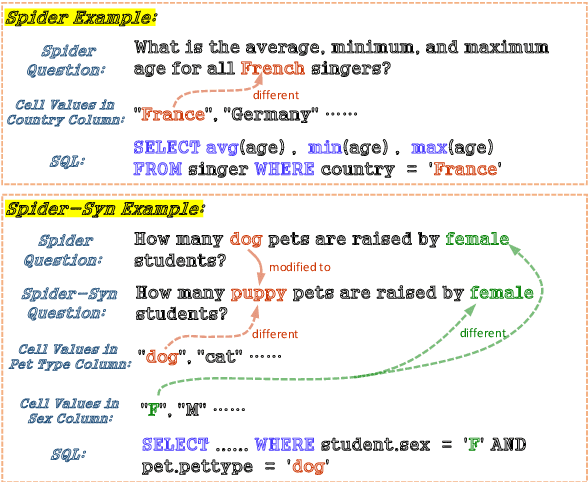
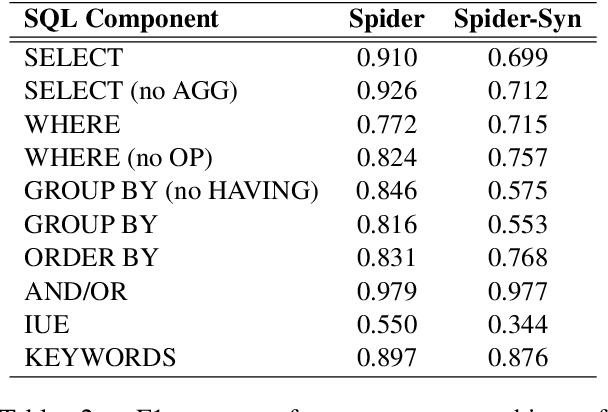
Recently, there has been significant progress in studying neural networks to translate text descriptions into SQL queries. Despite achieving good performance on some public benchmarks, existing text-to-SQL models typically rely on the lexical matching between words in natural language (NL) questions and tokens in table schemas, which may render the models vulnerable to attacks that break the schema linking mechanism. In this work, we investigate the robustness of text-to-SQL models to synonym substitution. In particular, we introduce Spider-Syn, a human-curated dataset based on the Spider benchmark for text-to-SQL translation. NL questions in Spider-Syn are modified from Spider, by replacing their schema-related words with manually selected synonyms that reflect real-world question paraphrases. We observe that the accuracy dramatically drops by eliminating such explicit correspondence between NL questions and table schemas, even if the synonyms are not adversarially selected to conduct worst-case adversarial attacks. Finally, we present two categories of approaches to improve the model robustness. The first category of approaches utilizes additional synonym annotations for table schemas by modifying the model input, while the second category is based on adversarial training. We demonstrate that both categories of approaches significantly outperform their counterparts without the defense, and the first category of approaches are more effective.