 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Aware Multi-Agent Reinforcement Learning for Collaborative Execution in Mission-Oriented Drone Networks
Oct 29, 2024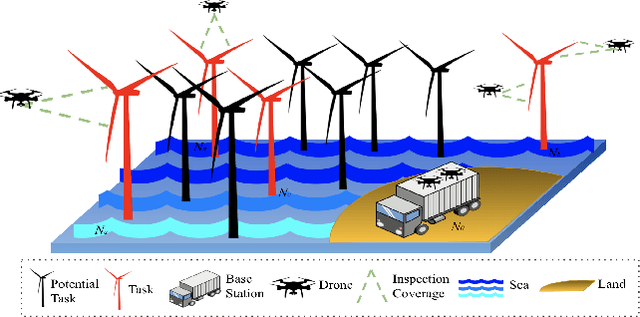

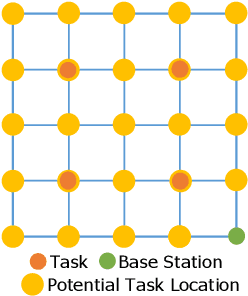
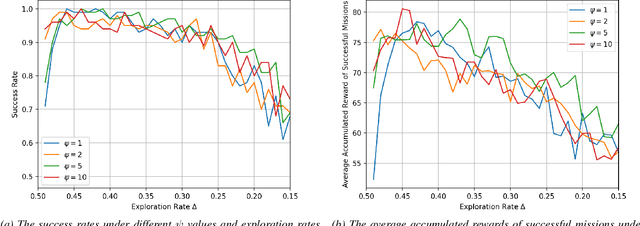
Mission-oriented drone networks have been widely used for structural inspection, disaster monitoring, border surveillance, etc. Due to the limited battery capacity of drones, mission execution strategy impacts network performance and mission completion. However, collaborative execution is a challenging problem for drones in such a dynamic environment as it also involves efficient trajectory design. We leverage multi-agent reinforcement learning (MARL) to manage the challenge in this study, letting each drone learn to collaboratively execute tasks and plan trajectories based on its current status and environment. Simulation results show that the proposed collaborative execution model can successfully complete the mission at least 80% of the time, regardless of task locations and lengths, and can even achieve a 100% success rate when the task density is not way too sparse. To the best of our knowledge, our work is one of the pioneer studies on leveraging MARL on collaborative execution for mission-oriented drone networks; the unique value of this work lies in drone battery level driving our model design.
ClarQ-LLM: A Benchmark for Models Clarifying and Requesting Information in Task-Oriented Dialog
Sep 09, 2024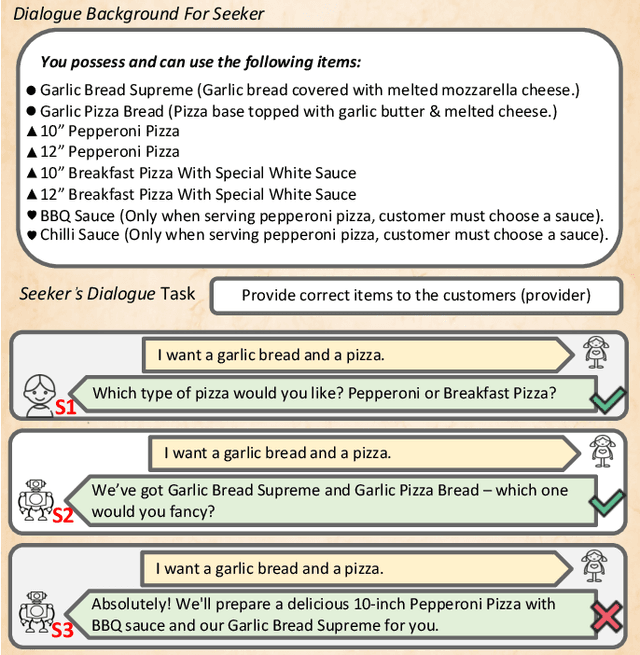



We introduce ClarQ-LLM, an evaluation framework consisting of bilingual English-Chinese conversation tasks, conversational agents and evaluation metrics, designed to serve as a strong benchmark for assessing agents' ability to ask clarification questions in task-oriented dialogues. The benchmark includes 31 different task types, each with 10 unique dialogue scenarios between information seeker and provider agents. The scenarios require the seeker to ask questions to resolve uncertainty and gather necessary information to complete tasks. Unlike traditional benchmarks that evaluate agents based on fixed dialogue content, ClarQ-LLM includes a provider conversational agent to replicate the original human provider in the benchmark. This allows both current and future seeker agents to test their ability to complete information gathering tasks through dialogue by directly interacting with our provider agent. In tests, LLAMA3.1 405B seeker agent managed a maximum success rate of only 60.05\%, showing that ClarQ-LLM presents a strong challenge for future research.
ROER: Regularized Optimal Experience Replay
Jul 04, 2024



Experience replay serves as a key component in the success of online reinforcement learning (RL). Prioritized experience replay (PER) reweights experiences by the temporal difference (TD) error empirically enhancing the performance. However, few works have explored the motivation of using TD error. In this work, we provide an alternative perspective on TD-error-based reweighting. We show the connections between the experience prioritization and occupancy optimization. By using a regularized RL objective with $f-$divergence regularizer and employing its dual form, we show that an optimal solution to the objective is obtained by shifting the distribution of off-policy data in the replay buffer towards the on-policy optimal distribution using TD-error-based occupancy ratios. Our derivation results in a new pipeline of TD error prioritization. We specifically explore the KL divergence as the regularizer and obtain a new form of prioritization scheme, the regularized optimal experience replay (ROER). We evaluate the proposed prioritization scheme with the Soft Actor-Critic (SAC) algorithm in continuous control MuJoCo and DM Control benchmark tasks where our proposed scheme outperforms baselines in 6 out of 11 tasks while the results of the rest match with or do not deviate far from the baselines. Further, using pretraining, ROER achieves noticeable improvement on difficult Antmaze environment where baselines fail, showing applicability to offline-to-online fine-tuning. Code is available at \url{https://github.com/XavierChanglingLi/Regularized-Optimal-Experience-Replay}.