 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClarQ-LLM: A Benchmark for Models Clarifying and Requesting Information in Task-Oriented Dialog
Sep 09, 2024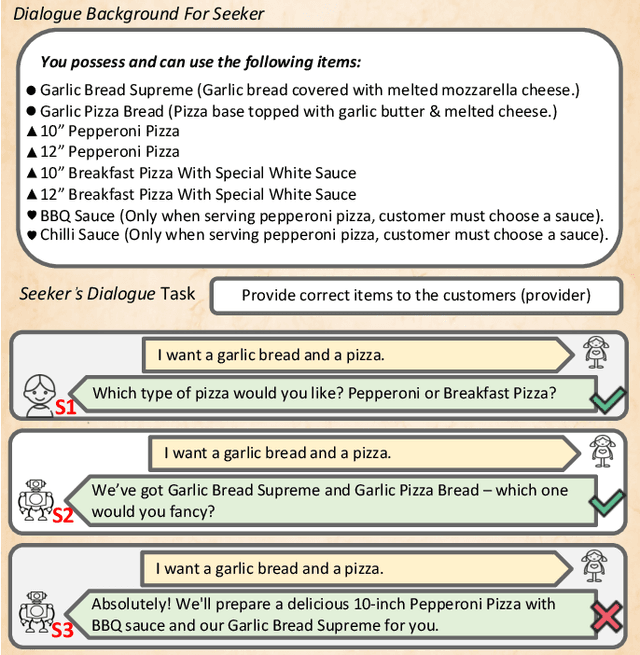



We introduce ClarQ-LLM, an evaluation framework consisting of bilingual English-Chinese conversation tasks, conversational agents and evaluation metrics, designed to serve as a strong benchmark for assessing agents' ability to ask clarification questions in task-oriented dialogues. The benchmark includes 31 different task types, each with 10 unique dialogue scenarios between information seeker and provider agents. The scenarios require the seeker to ask questions to resolve uncertainty and gather necessary information to complete tasks. Unlike traditional benchmarks that evaluate agents based on fixed dialogue content, ClarQ-LLM includes a provider conversational agent to replicate the original human provider in the benchmark. This allows both current and future seeker agents to test their ability to complete information gathering tasks through dialogue by directly interacting with our provider agent. In tests, LLAMA3.1 405B seeker agent managed a maximum success rate of only 60.05\%, showing that ClarQ-LLM presents a strong challenge for future research.
Underreporting of errors in NLG output, and what to do about it
Aug 08, 2021
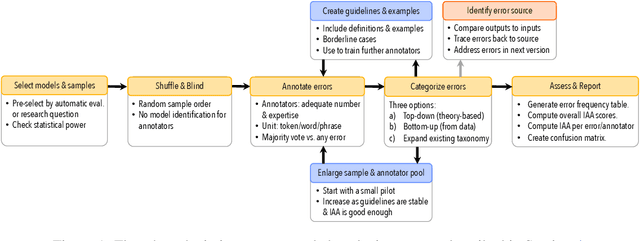
We observe a severe under-reporting of the different kinds of errors that Natural Language Generation systems make. This is a problem, because mistakes are an important indicator of where systems should still be improved. If authors only report overall performance metrics, the research community is left in the dark about the specific weaknesses that are exhibited by `state-of-the-art' research. Next to quantifying the extent of error under-reporting, this position paper provides recommendations for error identification, analysis and reporting.