 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural SQL: Making SQL Easier to Infer from Natural Language Specifications
Sep 11, 2021



Addressing the mismatch between natural language descriptions and the corresponding SQL queries is a key challenge for text-to-SQL translation. To bridge this gap, we propose an SQL intermediate representation (IR) called Natural SQL (NatSQL). Specifically, NatSQL preserves the core functionalities of SQL, while it simplifies the queries as follows: (1) dispensing with operators and keywords such as GROUP BY, HAVING, FROM, JOIN ON, which are usually hard to find counterparts for in the text descriptions; (2) removing the need for nested subqueries and set operators; and (3) making schema linking easier by reducing the required number of schema items. On Spider, a challenging text-to-SQL benchmark that contains complex and nested SQL queries, we demonstrate that NatSQL outperforms other IRs, and significantly improves the performance of several previous SOTA models. Furthermore, for existing models that do not support executable SQL generation, NatSQL easily enables them to generate executable SQL queries, and achieves the new state-of-the-art execution accuracy.
Towards Robustness of Text-to-SQL Models against Synonym Substitution
Jun 19, 2021
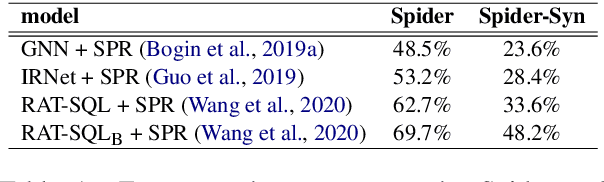
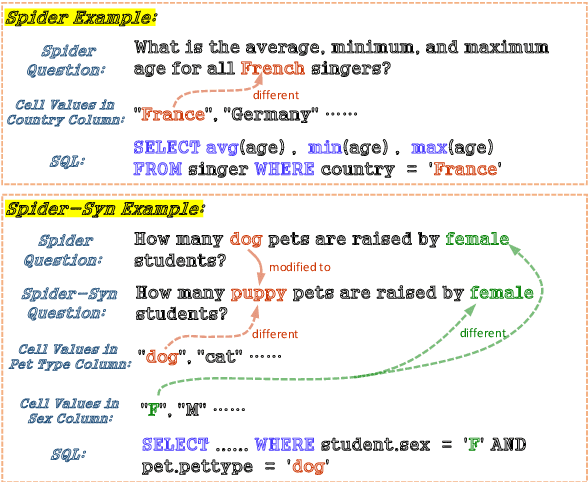
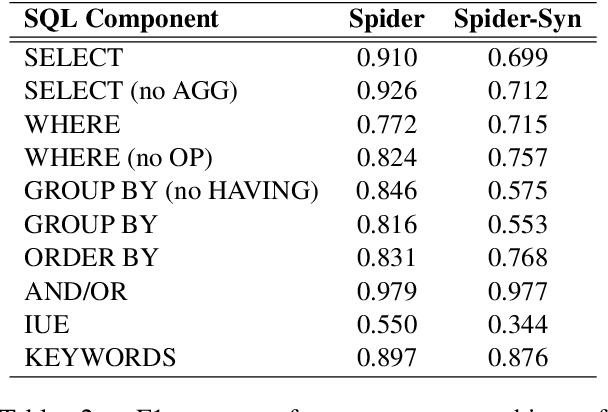
Recently, there has been significant progress in studying neural networks to translate text descriptions into SQL queries. Despite achieving good performance on some public benchmarks, existing text-to-SQL models typically rely on the lexical matching between words in natural language (NL) questions and tokens in table schemas, which may render the models vulnerable to attacks that break the schema linking mechanism. In this work, we investigate the robustness of text-to-SQL models to synonym substitution. In particular, we introduce Spider-Syn, a human-curated dataset based on the Spider benchmark for text-to-SQL translation. NL questions in Spider-Syn are modified from Spider, by replacing their schema-related words with manually selected synonyms that reflect real-world question paraphrases. We observe that the accuracy dramatically drops by eliminating such explicit correspondence between NL questions and table schemas, even if the synonyms are not adversarially selected to conduct worst-case adversarial attacks. Finally, we present two categories of approaches to improve the model robustness. The first category of approaches utilizes additional synonym annotations for table schemas by modifying the model input, while the second category is based on adversarial training. We demonstrate that both categories of approaches significantly outperform their counterparts without the defense, and the first category of approaches are more effective.
Evolution of Group-Theoretic Cryptology Attacks using Hyper-heuristics
Jun 15, 2020
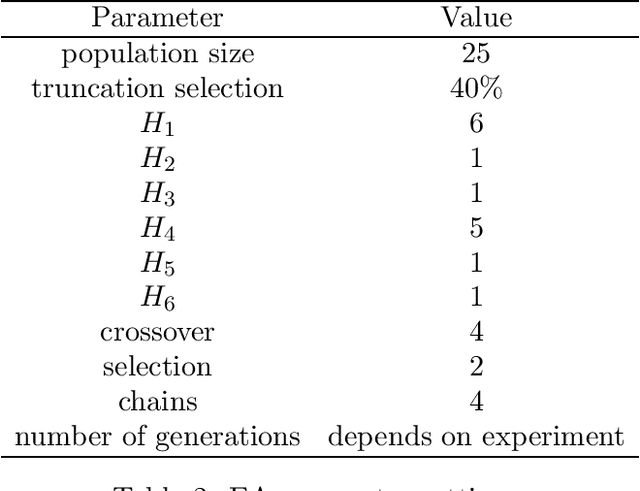
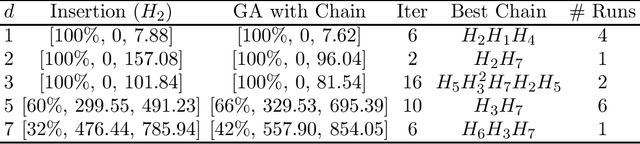
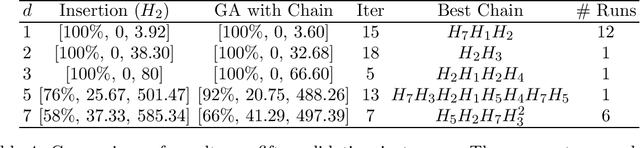
In previous work, we developed a single Evolutionary Algorithm (EA) to solve random instances of the Anshel-Anshel-Goldfeld (AAG) key exchange protocol over polycyclic groups. The EA consisted of six simple heuristics which manipulated strings. The present work extends this by exploring the use of hyper-heuristics in group-theoretic cryptology for the first time. Hyper-heuristics are a way to generate new algorithms from existing algorithm components (in this case the simple heuristics), with the EAs being one example of the type of algorithm which can be generated by our hyper-heuristic framework. We take as a starting point the above EA and allow hyper-heuristics to build on it by making small tweaks to it. This adaptation is through a process of taking the EA and injecting chains of heuristics built from the simple heuristics. We demonstrate we can create novel heuristic chains, which when placed in the EA create algorithms which out-perform the existing EA. The new algorithms solve a markedly greater number of random AAG instances than the EA for harder instances. This suggests the approach could be applied to many of the same kinds of problems, providing a framework for the solution of cryptology problems over groups. The contribution of this paper is thus a framework to automatically build algorithms to attack cryptology problems.