 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Referring Expression Comprehension Evaluation in the Era of Large Multimodal Models
Jun 24, 2024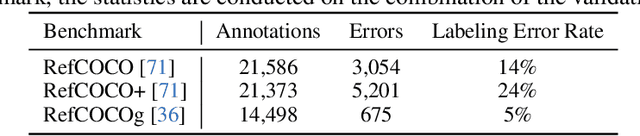
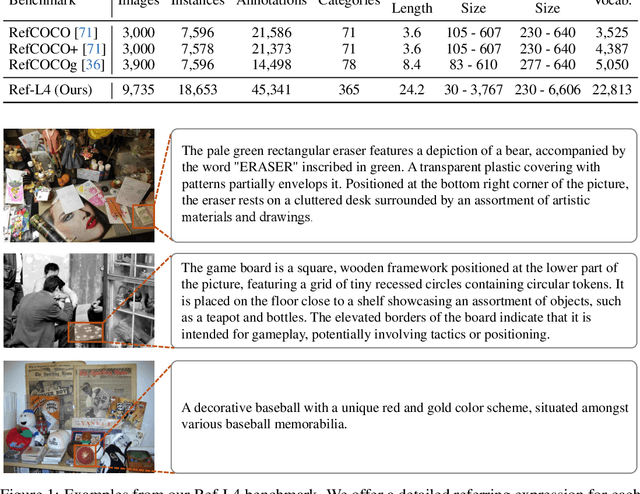
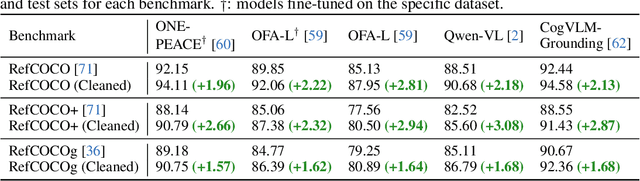
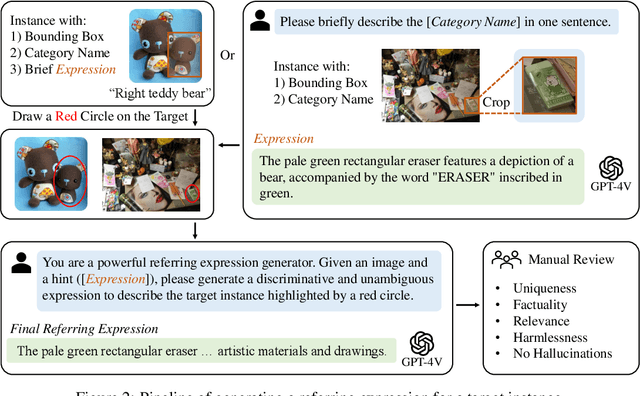
Referring expression comprehension (REC) involves localizing a target instance based on a textual description. Recent advancements in REC have been driven by large multimodal models (LMMs) like CogVLM, which achieved 92.44% accuracy on RefCOCO. However, this study questions whether existing benchmarks such as RefCOCO, RefCOCO+, and RefCOCOg, capture LMMs' comprehensive capabilities. We begin with a manual examination of these benchmarks, revealing high labeling error rates: 14% in RefCOCO, 24% in RefCOCO+, and 5% in RefCOCOg, which undermines the authenticity of evaluations. We address this by excluding problematic instances and reevaluating several LMMs capable of handling the REC task, showing significant accuracy improvements, thus highlighting the impact of benchmark noise. In response, we introduce Ref-L4, a comprehensive REC benchmark, specifically designed to evaluate modern REC models. Ref-L4 is distinguished by four key features: 1) a substantial sample size with 45,341 annotations; 2) a diverse range of object categories with 365 distinct types and varying instance scales from 30 to 3,767; 3) lengthy referring expressions averaging 24.2 words; and 4) an extensive vocabulary comprising 22,813 unique words. We evaluate a total of 24 large models on Ref-L4 and provide valuable insights. The cleaned versions of RefCOCO, RefCOCO+, and RefCOCOg, as well as our Ref-L4 benchmark and evaluation code, are available at https://github.com/JierunChen/Ref-L4.
A Multi-Scale Decomposition MLP-Mixer for Time Series Analysis
Oct 18, 2023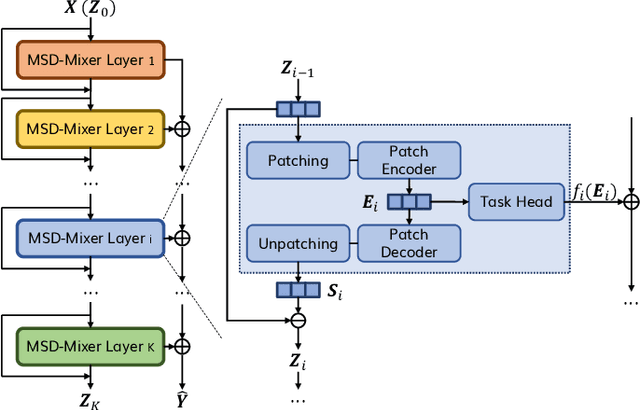
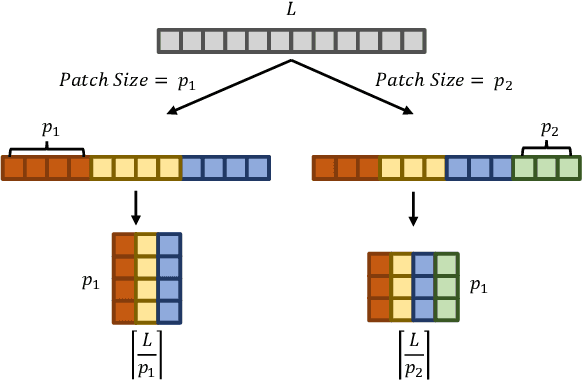
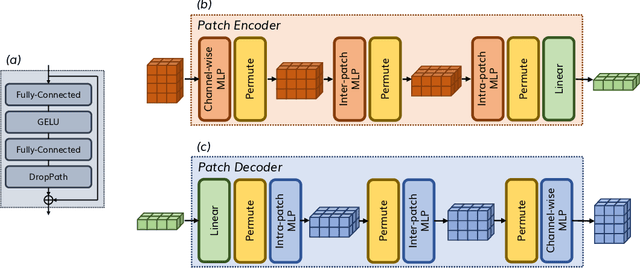
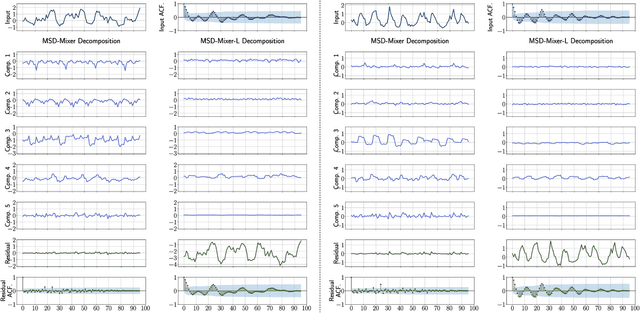
Time series data, often characterized by unique composition and complex multi-scale temporal variations, requires special consideration of decomposition and multi-scale modeling in its analysis. Existing deep learning methods on this best fit to only univariate time series, and have not sufficiently accounted for sub-series level modeling and decomposition completeness. To address this, we propose MSD-Mixer, a Multi-Scale Decomposition MLP-Mixer which learns to explicitly decompose the input time series into different components, and represents the components in different layers. To handle multi-scale temporal patterns and inter-channel dependencies, we propose a novel temporal patching approach to model the time series as multi-scale sub-series, i.e., patches, and employ MLPs to mix intra- and inter-patch variations and channel-wise correlations. In addition, we propose a loss function to constrain both the magnitude and autocorrelation of the decomposition residual for decomposition completeness. Through extensive experiments on various real-world datasets for five common time series analysis tasks (long- and short-term forecasting, imputation, anomaly detection, and classification), we demonstrate that MSD-Mixer consistently achieves significantly better performance in comparison with other state-of-the-art task-general and task-specific approaches.
Semi-Supervised Few-Shot Atomic Action Recognition
Nov 17, 2020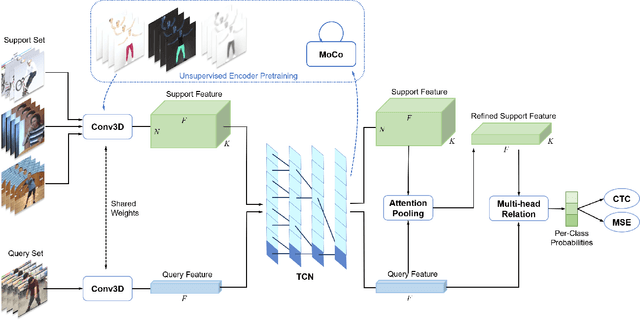
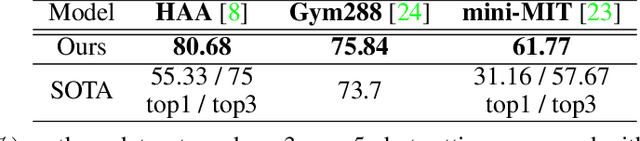
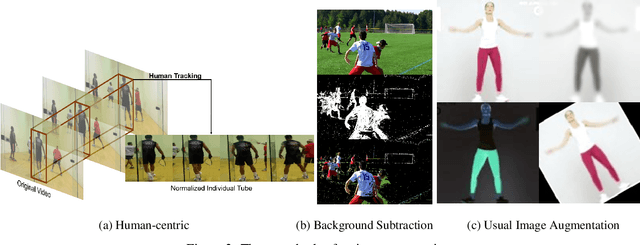
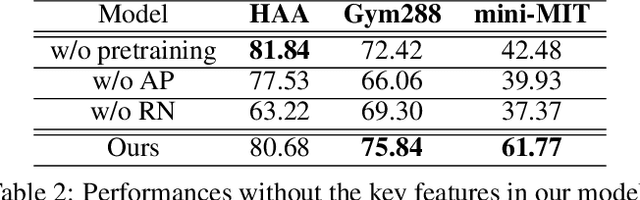
Despite excellent progress has been made, the performance on action recognition still heavily relies on specific datasets, which are difficult to extend new action classes due to labor-intensive labeling. Moreover, the high diversity in Spatio-temporal appearance requires robust and representative action feature aggregation and attention. To address the above issues, we focus on atomic actions and propose a novel model for semi-supervised few-shot atomic action recognition. Our model features unsupervised and contrastive video embedding, loose action alignment, multi-head feature comparison, and attention-based aggregation, together of which enables action recognition with only a few training examples through extracting more representative features and allowing flexibility in spatial and temporal alignment and variations in the action. Experiments show that our model can attain high accuracy on representative atomic action datasets outperforming their respective state-of-the-art classification accuracy in full supervision setting.