 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCooperative Policy Learning with Pre-trained Heterogeneous Observation Representations
Dec 24, 2020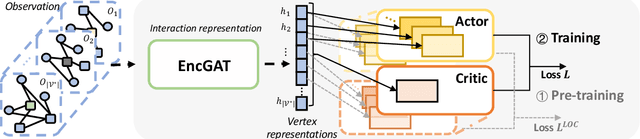
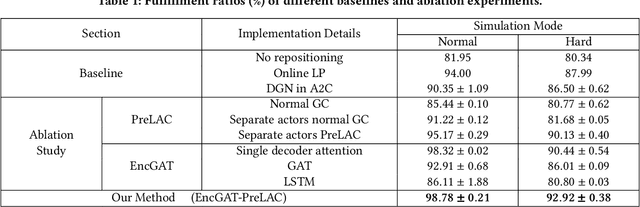
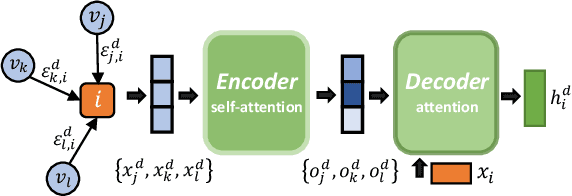

Multi-agent reinforcement learning (MARL) has been increasingly explored to learn the cooperative policy towards maximizing a certain global reward. Many existing studies take advantage of graph neural networks (GNN) in MARL to propagate critical collaborative information over the interaction graph, built upon inter-connected agents. Nevertheless, the vanilla GNN approach yields substantial defects in dealing with complex real-world scenarios since the generic message passing mechanism is ineffective between heterogeneous vertices and, moreover, simple message aggregation functions are incapable of accurately modeling the combinational interactions from multiple neighbors. While adopting complex GNN models with more informative message passing and aggregation mechanisms can obviously benefit heterogeneous vertex representations and cooperative policy learning, it could, on the other hand, increase the training difficulty of MARL and demand more intense and direct reward signals compared to the original global reward. To address these challenges, we propose a new cooperative learning framework with pre-trained heterogeneous observation representations. Particularly, we employ an encoder-decoder based graph attention to learn the intricate interactions and heterogeneous representations that can be more easily leveraged by MARL. Moreover, we design a pre-training with local actor-critic algorithm to ease the difficulty in cooperative policy learning. Extensive experiments over real-world scenarios demonstrate that our new approach can significantly outperform existing MARL baselines as well as operational research solutions that are widely-used in industry.
Semi-Supervised Few-Shot Atomic Action Recognition
Nov 17, 2020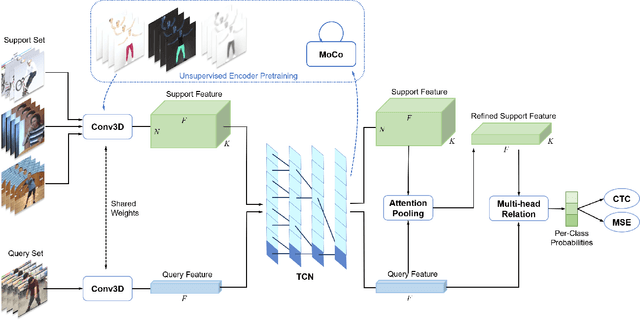
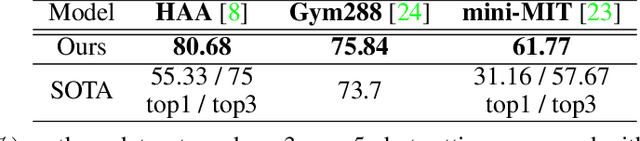
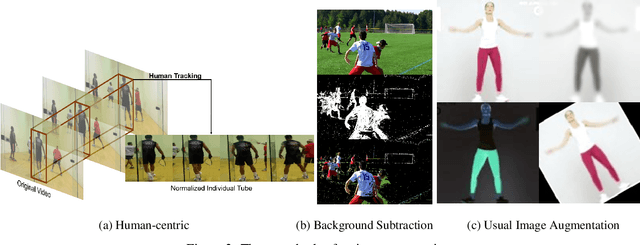
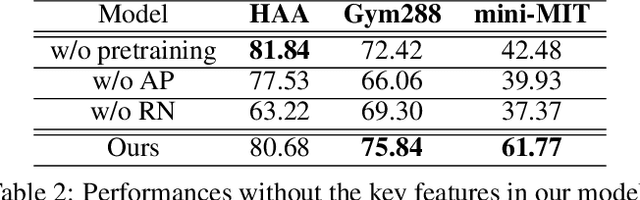
Despite excellent progress has been made, the performance on action recognition still heavily relies on specific datasets, which are difficult to extend new action classes due to labor-intensive labeling. Moreover, the high diversity in Spatio-temporal appearance requires robust and representative action feature aggregation and attention. To address the above issues, we focus on atomic actions and propose a novel model for semi-supervised few-shot atomic action recognition. Our model features unsupervised and contrastive video embedding, loose action alignment, multi-head feature comparison, and attention-based aggregation, together of which enables action recognition with only a few training examples through extracting more representative features and allowing flexibility in spatial and temporal alignment and variations in the action. Experiments show that our model can attain high accuracy on representative atomic action datasets outperforming their respective state-of-the-art classification accuracy in full supervision setting.