 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Few-Shot Atomic Action Recognition
Paper and Code
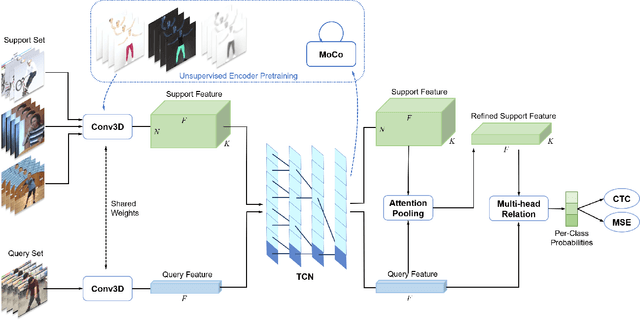
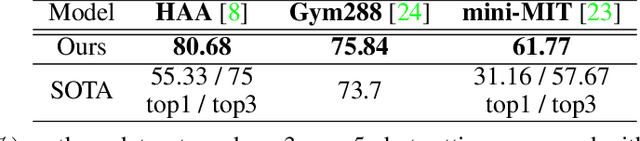
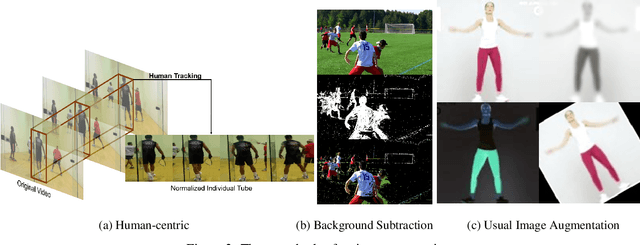
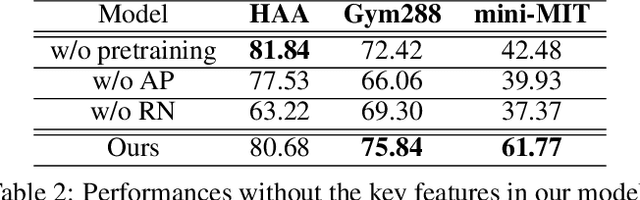
Despite excellent progress has been made, the performance on action recognition still heavily relies on specific datasets, which are difficult to extend new action classes due to labor-intensive labeling. Moreover, the high diversity in Spatio-temporal appearance requires robust and representative action feature aggregation and attention. To address the above issues, we focus on atomic actions and propose a novel model for semi-supervised few-shot atomic action recognition. Our model features unsupervised and contrastive video embedding, loose action alignment, multi-head feature comparison, and attention-based aggregation, together of which enables action recognition with only a few training examples through extracting more representative features and allowing flexibility in spatial and temporal alignment and variations in the action. Experiments show that our model can attain high accuracy on representative atomic action datasets outperforming their respective state-of-the-art classification accuracy in full supervision setting.