 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecompose to Understand, Fuse to Detect: Frequency-Decoupled Anomaly Detection for Encrypted Network Traffic
May 03, 2026Network traffic anomaly detection represents a critical cybersecurity task, yet widespread encryption makes this task increasingly challenging. In response, image-based methods that model traffic as visual patterns have emerged as the dominant approach. However, this work pioneers the identification of a pervasive ``full-frequency'' characteristic and an associated limitation termed ``spectral mismatch'' within this paradigm. Specifically, while encrypted traffic exhibits prominent high-frequency components, mainstream reconstruction methods demonstrate an inherent bias toward learning low-frequency information. This fundamental mismatch results in incomplete representations that consequently degrade anomaly detection performance. To address this challenge, we propose FreeUp, a novel frequency-decoupled framework designed explicitly for encrypted traffic analysis. FreeUp decomposes traffic data into distinct low- and high-frequency bands, processing them through separate, dedicated branches along with a customized training strategy that ensures stable and independent frequency-specific learning. Furthermore, recognizing that simple reconstruction error proves inadequate for evaluating dual-branch architectures, we introduce an uncertainty-inspired fusion scoring mechanism. This mechanism quantifies the reconstruction uncertainty of the frequency-specific branches and dynamically integrates their outputs, yielding a more comprehensive and reliable anomaly score. Extensive experiments across multiple benchmarks demonstrate that FreeUp consistently outperforms state-of-the-art baselines. The code is available at https://github.com/ikun0124/FreeUp.
Continuous Vision-Language-Action Co-Learning with Semantic-Physical Alignment for Behavioral Cloning
Nov 18, 2025
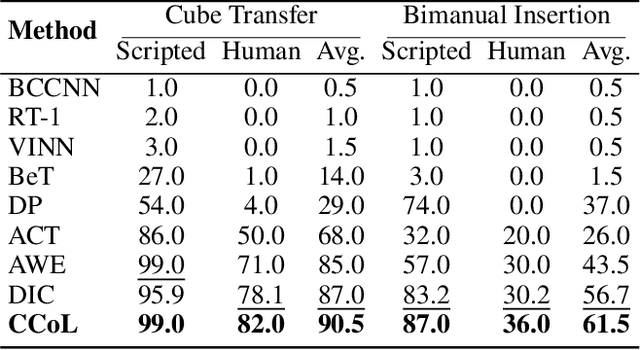


Language-conditioned manipulation facilitates human-robot interaction via behavioral cloning (BC), which learns control policies from human demonstrations and serves as a cornerstone of embodied AI. Overcoming compounding errors in sequential action decisions remains a central challenge to improving BC performance. Existing approaches mitigate compounding errors through data augmentation, expressive representation, or temporal abstraction. However, they suffer from physical discontinuities and semantic-physical misalignment, leading to inaccurate action cloning and intermittent execution. In this paper, we present Continuous vision-language-action Co-Learning with Semantic-Physical Alignment (CCoL), a novel BC framework that ensures temporally consistent execution and fine-grained semantic grounding. It generates robust and smooth action execution trajectories through continuous co-learning across vision, language, and proprioceptive inputs (e.g., robot internal states). Meanwhile, we anchor language semantics to visuomotor representations by a bidirectional cross-attention to learn contextual information for action generation, successfully overcoming the problem of semantic-physical misalignment. Extensive experiments show that CCoL achieves an average 8.0% relative improvement across three simulation suites, with up to 19.2% relative gain in human-demonstrated bimanual insertion tasks. Real-world tests on a 7-DoF robot further confirm CCoL's generalization under unseen and noisy object states.
A Survey of Mix-based Data Augmentation: Taxonomy, Methods, Applications, and Explainability
Dec 21, 2022Data augmentation (DA) is indispensable in modern machine learning and deep neural networks. The basic idea of DA is to construct new training data to improve the model's generalization by adding slightly disturbed versions of existing data or synthesizing new data. In this work, we review a small but essential subset of DA -- Mix-based Data Augmentation (MixDA) that generates novel samples by mixing multiple examples. Unlike conventional DA approaches based on a single-sample operation or requiring domain knowledge, MixDA is more general in creating a broad spectrum of new data and has received increasing attention in the community. We begin with proposing a new taxonomy classifying MixDA into, Mixup-based, Cutmix-based, and hybrid approaches according to a hierarchical view of the data mix. Various MixDA techniques are then comprehensively reviewed in a more fine-grained way. Owing to its generalization, MixDA has penetrated a variety of applications which are also completely reviewed in this work. We also examine why MixDA works from different aspects of improving model performance, generalization, and calibration while explaining the model behavior based on the properties of MixDA. Finally, we recapitulate the critical findings and fundamental challenges of current MixDA studies, and outline the potential directions for future works. Different from previous related works that summarize the DA approaches in a specific domain (e.g., images or natural language processing) or only review a part of MixDA studies, we are the first to provide a systematical survey of MixDA in terms of its taxonomy, methodology, applications, and explainability. This work can serve as a roadmap to MixDA techniques and application reviews while providing promising directions for researchers interested in this exciting area.
Continual Graph Learning
Mar 22, 2020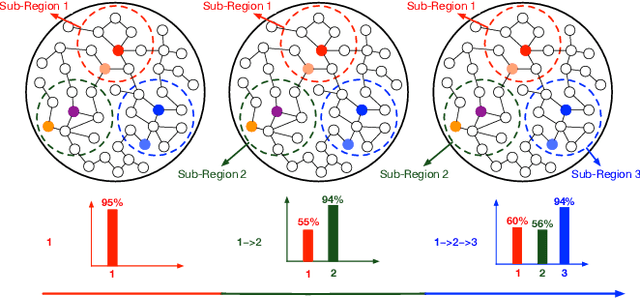
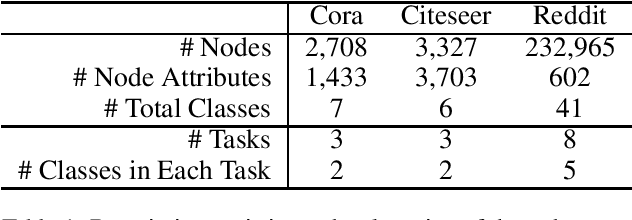
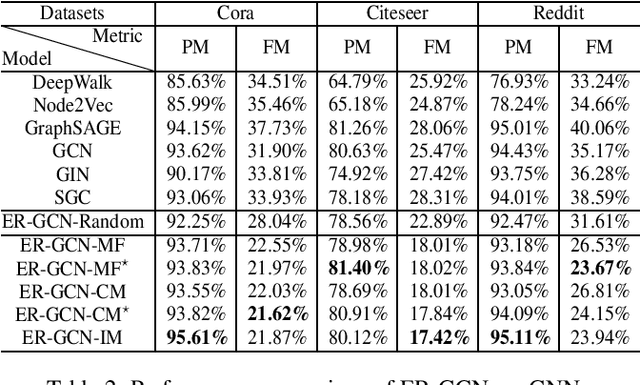
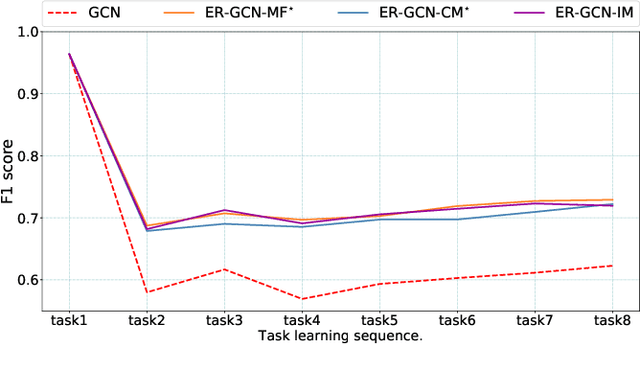
Graph Neural Networks (GNNs) have recently received significant research attention due to their prominent performance on a variety of graph-related learning tasks. Most of the existing works focus on either static or dynamic graph settings, addressing a particular task, e.g., node/graph classification, link prediction. In this work, we investigate the question: can GNNs be applied to continuously learning a sequence of tasks? Towards that, we explore the Continual Graph Learning (CGL) paradigm and we present the Experience Replay based framework ER-GNN for CGL to address the catastrophic forgetting problem in existing GNNs. ER-GNN stores knowledge from previous tasks as experiences and replays them when learning new tasks to mitigate the forgetting issue. We propose three experience node selection strategies: mean of features, coverage maximization and influence maximization, to guide the process of selecting experience nodes. Extensive experiments on three benchmark datasets demonstrate the effectiveness of ER-GNN and shed light on the incremental (non-Euclidean) graph structure learning.
Meta-GNN: On Few-shot Node Classification in Graph Meta-learning
May 23, 2019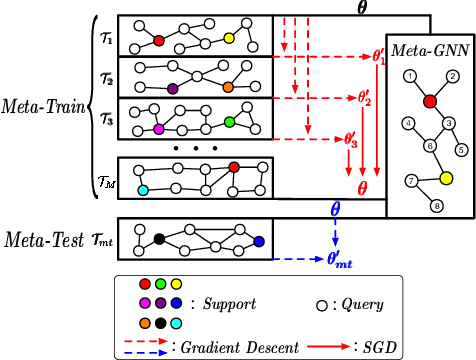
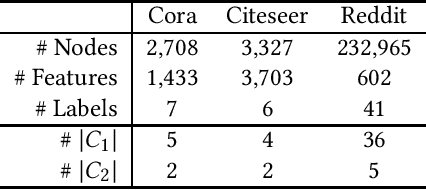
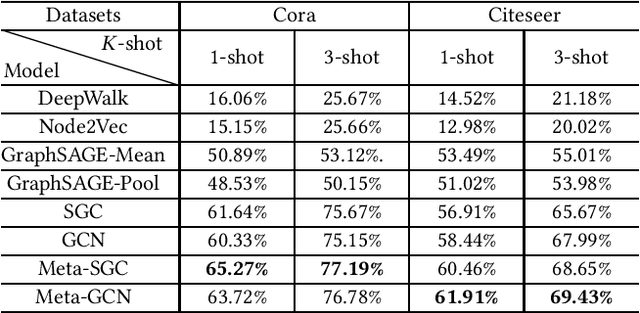
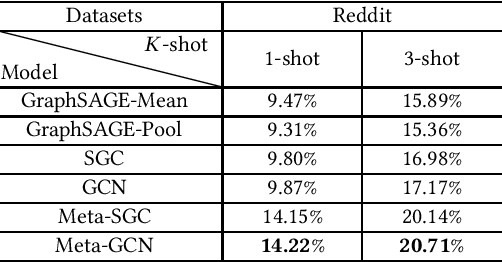
Meta-learning has received a tremendous recent attention as a possible approach for mimicking human intelligence, i.e., acquiring new knowledge and skills with little or even no demonstration. Most of the existing meta-learning methods are proposed to tackle few-shot learning problems such as image and text, in rather Euclidean domain. However, there are very few works applying meta-learning to non-Euclidean domains, and the recently proposed graph neural networks (GNNs) models do not perform effectively on graph few-shot learning problems. Towards this, we propose a novel graph meta-learning framework -- Meta-GNN -- to tackle the few-shot node classification problem in graph meta-learning settings. It obtains the prior knowledge of classifiers by training on many similar few-shot learning tasks and then classifies the nodes from new classes with only few labeled samples. Additionally, Meta-GNN is a general model that can be straightforwardly incorporated into any existing state-of-the-art GNN. Our experiments conducted on three benchmark datasets demonstrate that our proposed approach not only improves the node classification performance by a large margin on few-shot learning problems in meta-learning paradigm, but also learns a more general and flexible model for task adaption.