 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-View Dynamic Fusion Framework: How to Improve the Multimodal Brain Tumor Segmentation from Multi-Views?
Dec 21, 2020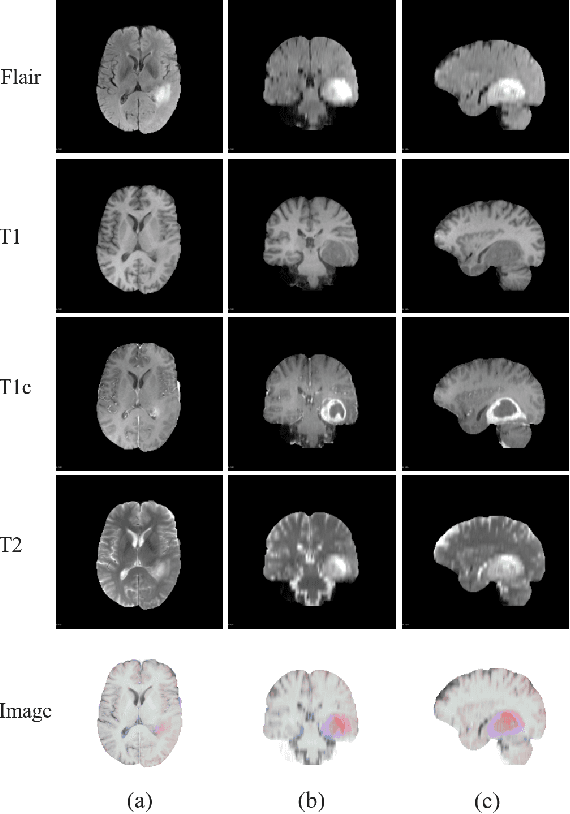



When diagnosing the brain tumor, doctors usually make a diagnosis by observing multimodal brain images from the axial view, the coronal view and the sagittal view, respectively. And then they make a comprehensive decision to confirm the brain tumor based on the information obtained from multi-views. Inspired by this diagnosing process and in order to further utilize the 3D information hidden in the dataset, this paper proposes a multi-view dynamic fusion framework to improve the performance of brain tumor segmentation. The proposed framework consists of 1) a multi-view deep neural network architecture, which represents multi learning networks for segmenting the brain tumor from different views and each deep neural network corresponds to multi-modal brain images from one single view and 2) the dynamic decision fusion method, which is mainly used to fuse segmentation results from multi-views as an integrate one and two different fusion methods, the voting method and the weighted averaging method, have been adopted to evaluate the fusing process. Moreover, the multi-view fusion loss, which consists of the segmentation loss, the transition loss and the decision loss, is proposed to facilitate the training process of multi-view learning networks so as to keep the consistency of appearance and space, not only in the process of fusing segmentation results, but also in the process of training the learning network. \par By evaluating the proposed framework on BRATS 2015 and BRATS 2018, it can be found that the fusion results from multi-views achieve a better performance than the segmentation result from the single view and the effectiveness of proposed multi-view fusion loss has also been proved. Moreover, the proposed framework achieves a better segmentation performance and a higher efficiency compared to other counterpart methods.
Continual Graph Learning
Mar 22, 2020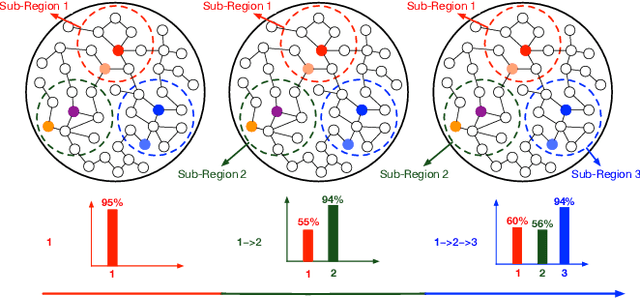
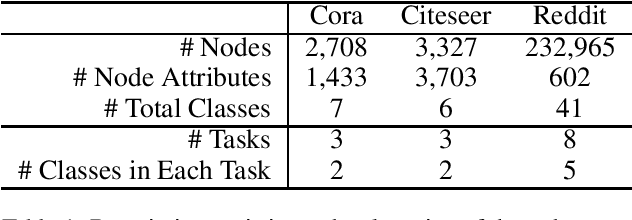
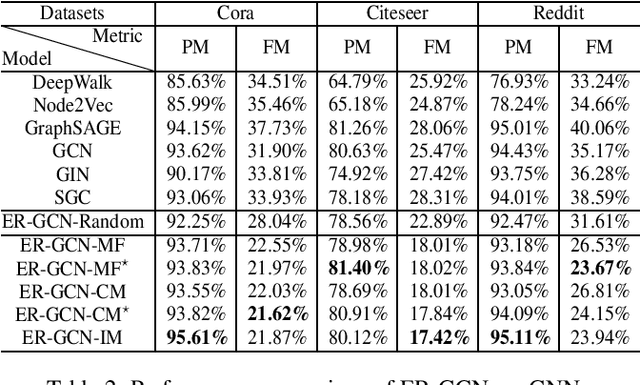
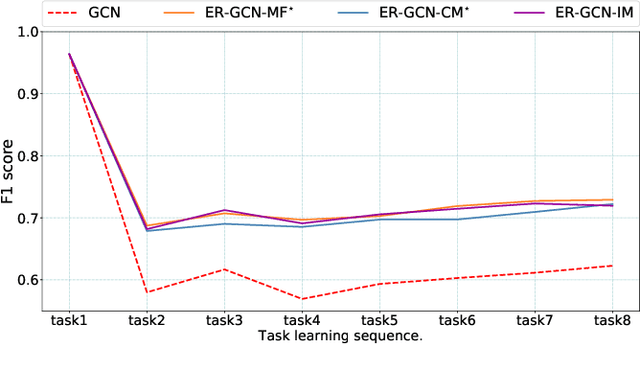
Graph Neural Networks (GNNs) have recently received significant research attention due to their prominent performance on a variety of graph-related learning tasks. Most of the existing works focus on either static or dynamic graph settings, addressing a particular task, e.g., node/graph classification, link prediction. In this work, we investigate the question: can GNNs be applied to continuously learning a sequence of tasks? Towards that, we explore the Continual Graph Learning (CGL) paradigm and we present the Experience Replay based framework ER-GNN for CGL to address the catastrophic forgetting problem in existing GNNs. ER-GNN stores knowledge from previous tasks as experiences and replays them when learning new tasks to mitigate the forgetting issue. We propose three experience node selection strategies: mean of features, coverage maximization and influence maximization, to guide the process of selecting experience nodes. Extensive experiments on three benchmark datasets demonstrate the effectiveness of ER-GNN and shed light on the incremental (non-Euclidean) graph structure learning.
Meta-GNN: On Few-shot Node Classification in Graph Meta-learning
May 23, 2019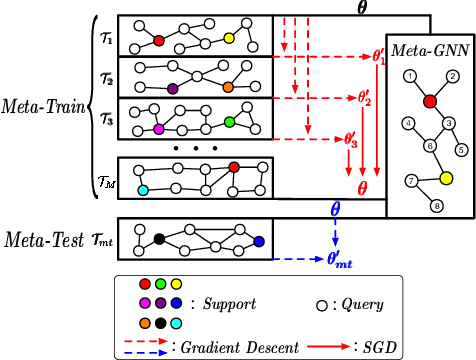
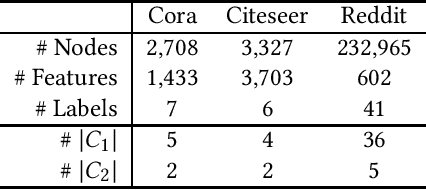
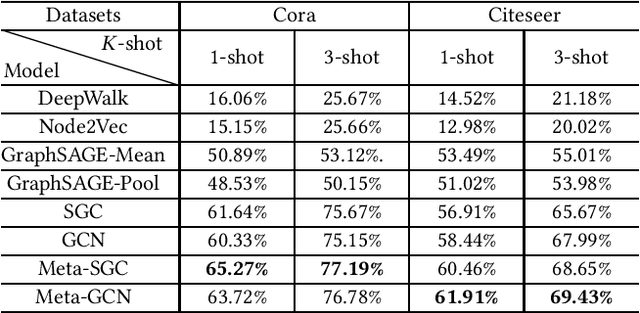
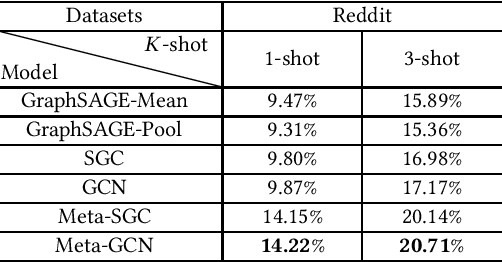
Meta-learning has received a tremendous recent attention as a possible approach for mimicking human intelligence, i.e., acquiring new knowledge and skills with little or even no demonstration. Most of the existing meta-learning methods are proposed to tackle few-shot learning problems such as image and text, in rather Euclidean domain. However, there are very few works applying meta-learning to non-Euclidean domains, and the recently proposed graph neural networks (GNNs) models do not perform effectively on graph few-shot learning problems. Towards this, we propose a novel graph meta-learning framework -- Meta-GNN -- to tackle the few-shot node classification problem in graph meta-learning settings. It obtains the prior knowledge of classifiers by training on many similar few-shot learning tasks and then classifies the nodes from new classes with only few labeled samples. Additionally, Meta-GNN is a general model that can be straightforwardly incorporated into any existing state-of-the-art GNN. Our experiments conducted on three benchmark datasets demonstrate that our proposed approach not only improves the node classification performance by a large margin on few-shot learning problems in meta-learning paradigm, but also learns a more general and flexible model for task adaption.