 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPIQ: Residual-Projected Multi-Collaboration Closed-Loop and Single Instance Quantization for Visually Impaired Assistance
Jan 06, 2026Visually impaired users face significant challenges in daily information access and real-time environmental perception, and there is an urgent need for intelligent assistive systems with accurate recognition capabilities. Although large-scale models provide effective solutions for perception and reasoning, their practical deployment on assistive devices is severely constrained by excessive memory consumption and high inference costs. Moreover, existing quantization strategies often ignore inter-block error accumulation, leading to degraded model stability. To address these challenges, this study proposes a novel quantization framework -- Residual-Projected Multi-Collaboration Closed-Loop and Single Instance Quantization(RPIQ), whose quantization process adopts a multi-collaborative closed-loop compensation scheme based on Single Instance Calibration and Gauss-Seidel Iterative Quantization. Experiments on various types of large-scale models, including language models such as OPT, Qwen, and LLaMA, as well as vision-language models such as CogVLM2, demonstrate that RPIQ can compress models to 4-bit representation while significantly reducing peak memory consumption (approximately 60%-75% reduction compared to original full-precision models). The method maintains performance highly close to full-precision models across multiple language and visual tasks, and exhibits excellent recognition and reasoning capabilities in key applications such as text understanding and visual question answering in complex scenarios. While verifying the effectiveness of RPIQ for deployment in real assistive systems, this study also advances the computational efficiency and reliability of large models, enabling them to provide visually impaired users with the required information accurately and rapidly.
An Efficient Privacy-aware Split Learning Framework for Satellite Communications
Sep 13, 2024



In the rapidly evolving domain of satellite communications, integrating advanced machine learning techniques, particularly split learning, is crucial for enhancing data processing and model training efficiency across satellites, space stations, and ground stations. Traditional ML approaches often face significant challenges within satellite networks due to constraints such as limited bandwidth and computational resources. To address this gap, we propose a novel framework for more efficient SL in satellite communications. Our approach, Dynamic Topology Informed Pruning, namely DTIP, combines differential privacy with graph and model pruning to optimize graph neural networks for distributed learning. DTIP strategically applies differential privacy to raw graph data and prunes GNNs, thereby optimizing both model size and communication load across network tiers. Extensive experiments across diverse datasets demonstrate DTIP's efficacy in enhancing privacy, accuracy, and computational efficiency. Specifically, on Amazon2M dataset, DTIP maintains an accuracy of 0.82 while achieving a 50% reduction in floating-point operations per second. Similarly, on ArXiv dataset, DTIP achieves an accuracy of 0.85 under comparable conditions. Our framework not only significantly improves the operational efficiency of satellite communications but also establishes a new benchmark in privacy-aware distributed learning, potentially revolutionizing data handling in space-based networks.
A Multi-View Dynamic Fusion Framework: How to Improve the Multimodal Brain Tumor Segmentation from Multi-Views?
Dec 21, 2020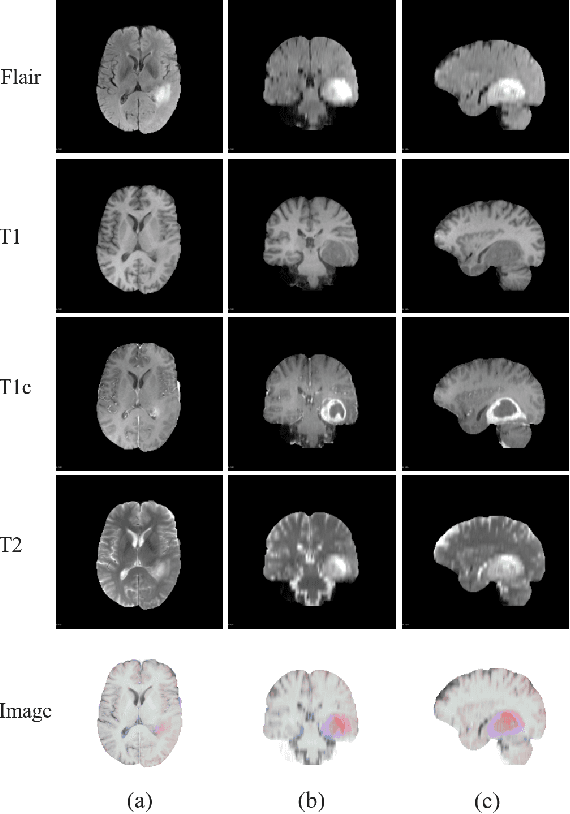



When diagnosing the brain tumor, doctors usually make a diagnosis by observing multimodal brain images from the axial view, the coronal view and the sagittal view, respectively. And then they make a comprehensive decision to confirm the brain tumor based on the information obtained from multi-views. Inspired by this diagnosing process and in order to further utilize the 3D information hidden in the dataset, this paper proposes a multi-view dynamic fusion framework to improve the performance of brain tumor segmentation. The proposed framework consists of 1) a multi-view deep neural network architecture, which represents multi learning networks for segmenting the brain tumor from different views and each deep neural network corresponds to multi-modal brain images from one single view and 2) the dynamic decision fusion method, which is mainly used to fuse segmentation results from multi-views as an integrate one and two different fusion methods, the voting method and the weighted averaging method, have been adopted to evaluate the fusing process. Moreover, the multi-view fusion loss, which consists of the segmentation loss, the transition loss and the decision loss, is proposed to facilitate the training process of multi-view learning networks so as to keep the consistency of appearance and space, not only in the process of fusing segmentation results, but also in the process of training the learning network. \par By evaluating the proposed framework on BRATS 2015 and BRATS 2018, it can be found that the fusion results from multi-views achieve a better performance than the segmentation result from the single view and the effectiveness of proposed multi-view fusion loss has also been proved. Moreover, the proposed framework achieves a better segmentation performance and a higher efficiency compared to other counterpart methods.
DeepKeyGen: A Deep Learning-based Stream Cipher Generator for Medical Image Encryption and Decryption
Dec 21, 2020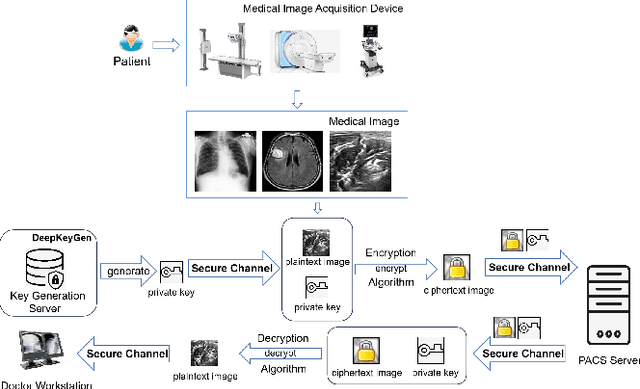

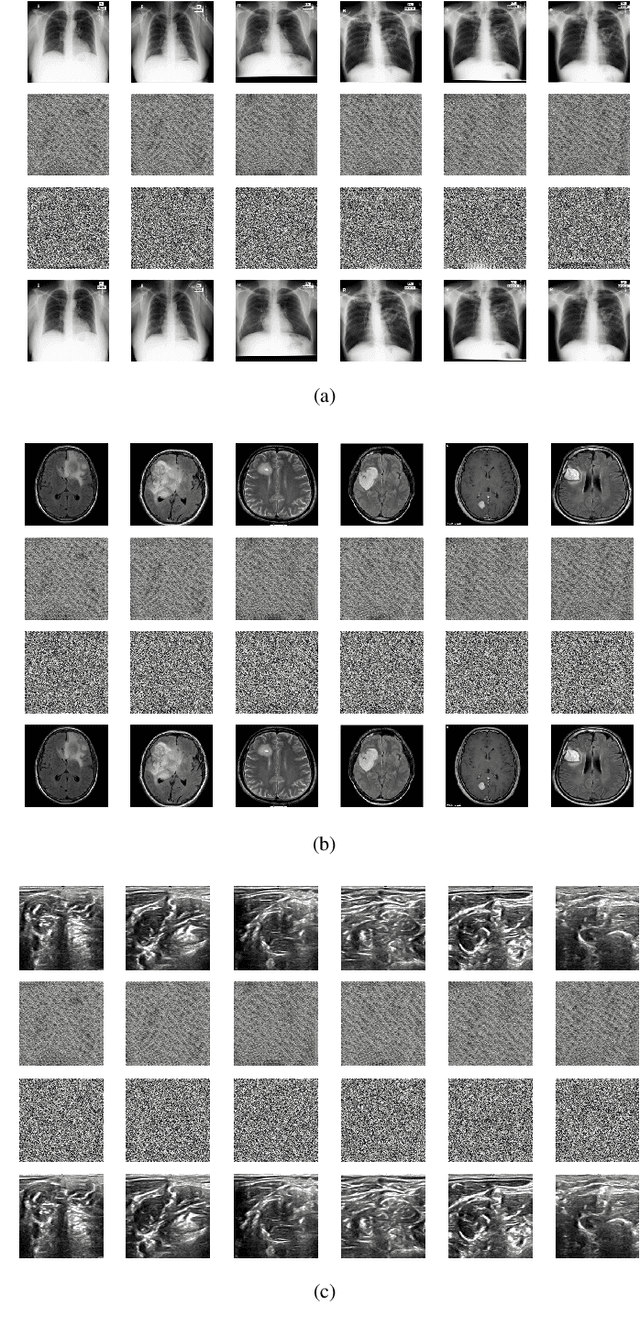
The need for medical image encryption is increasingly pronounced, for example to safeguard the privacy of the patients' medical imaging data. In this paper, a novel deep learning-based key generation network (DeepKeyGen) is proposed as a stream cipher generator to generate the private key, which can then be used for encrypting and decrypting of medical images. In DeepKeyGen, the generative adversarial network (GAN) is adopted as the learning network to generate the private key. Furthermore, the transformation domain (that represents the "style" of the private key to be generated) is designed to guide the learning network to realize the private key generation process. The goal of DeepKeyGen is to learn the mapping relationship of how to transfer the initial image to the private key. We evaluate DeepKeyGen using three datasets, namely: the Montgomery County chest X-ray dataset, the Ultrasonic Brachial Plexus dataset, and the BraTS18 dataset. The evaluation findings and security analysis show that the proposed key generation network can achieve a high-level security in generating the private key.
DeepEDN: A Deep Learning-based Image Encryption and Decryption Network for Internet of Medical Things
May 05, 2020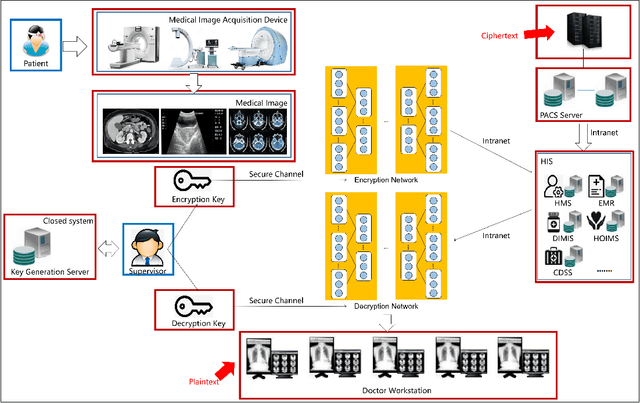

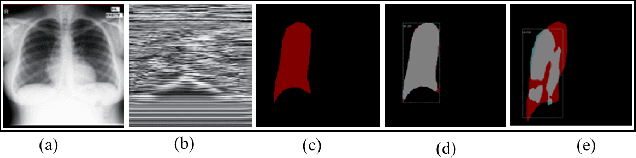
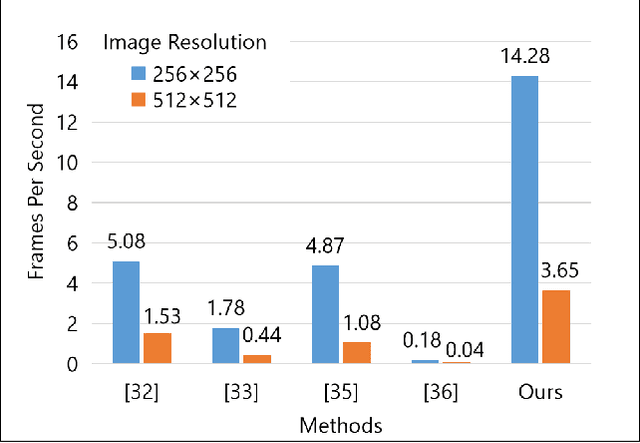
Internet of Medical Things (IoMT) can connect many medical imaging equipments to the medical information network to facilitate the process of diagnosing and treating for doctors. As medical image contains sensitive information, it is of importance yet very challenging to safeguard the privacy or security of the patient. In this work, a deep learning based encryption and decryption network (DeepEDN) is proposed to fulfill the process of encrypting and decrypting the medical image. Specifically, in DeepEDN, the Cycle-Generative Adversarial Network (Cycle-GAN) is employed as the main learning network to transfer the medical image from its original domain into the target domain. Target domain is regarded as a "Hidden Factors" to guide the learning model for realizing the encryption. The encrypted image is restored to the original (plaintext) image through a reconstruction network to achieve an image decryption. In order to facilitate the data mining directly from the privacy-protected environment, a region of interest(ROI)-mining-network is proposed to extract the interested object from the encrypted image. The proposed DeepEDN is evaluated on the chest X-ray dataset. Extensive experimental results and security analysis show that the proposed method can achieve a high level of security with a good performance in efficiency.