 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACE: Pretrained Audio Continual Learning
Feb 03, 2026Audio is a fundamental modality for analyzing speech, music, and environmental sounds. Although pretrained audio models have significantly advanced audio understanding, they remain fragile in real-world settings where data distributions shift over time. In this work, we present the first systematic benchmark for audio continual learning (CL) with pretrained models (PTMs), together with a comprehensive analysis of its unique challenges. Unlike in vision, where parameter-efficient fine-tuning (PEFT) has proven effective for CL, directly transferring such strategies to audio leads to poor performance. This stems from a fundamental property of audio backbones: they focus on low-level spectral details rather than structured semantics, causing severe upstream-downstream misalignment. Through extensive empirical study, we identify analytic classifiers with first-session adaptation (FSA) as a promising direction, but also reveal two major limitations: representation saturation in coarse-grained scenarios and representation drift in fine-grained scenarios. To address these challenges, we propose PACE, a novel method that enhances FSA via a regularized analytic classifier and enables multi-session adaptation through adaptive subspace-orthogonal PEFT for improved semantic alignment. In addition, we introduce spectrogram-based boundary-aware perturbations to mitigate representation overlap and improve stability. Experiments on six diverse audio CL benchmarks demonstrate that PACE substantially outperforms state-of-the-art baselines, marking an important step toward robust and scalable audio continual learning with PTMs.
FlyPrompt: Brain-Inspired Random-Expanded Routing with Temporal-Ensemble Experts for General Continual Learning
Feb 03, 2026General continual learning (GCL) challenges intelligent systems to learn from single-pass, non-stationary data streams without clear task boundaries. While recent advances in continual parameter-efficient tuning (PET) of pretrained models show promise, they typically rely on multiple training epochs and explicit task cues, limiting their effectiveness in GCL scenarios. Moreover, existing methods often lack targeted design and fail to address two fundamental challenges in continual PET: how to allocate expert parameters to evolving data distributions, and how to improve their representational capacity under limited supervision. Inspired by the fruit fly's hierarchical memory system characterized by sparse expansion and modular ensembles, we propose FlyPrompt, a brain-inspired framework that decomposes GCL into two subproblems: expert routing and expert competence improvement. FlyPrompt introduces a randomly expanded analytic router for instance-level expert activation and a temporal ensemble of output heads to dynamically adapt decision boundaries over time. Extensive theoretical and empirical evaluations demonstrate FlyPrompt's superior performance, achieving up to 11.23%, 12.43%, and 7.62% gains over state-of-the-art baselines on CIFAR-100, ImageNet-R, and CUB-200, respectively. Our source code is available at https://github.com/AnAppleCore/FlyGCL.
CaRF: Enhancing Multi-View Consistency in Referring 3D Gaussian Splatting Segmentation
Nov 06, 2025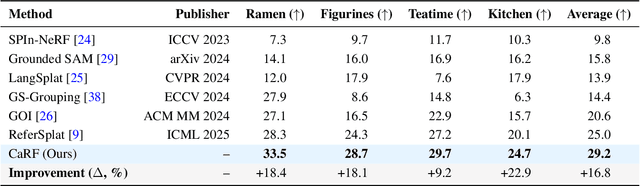
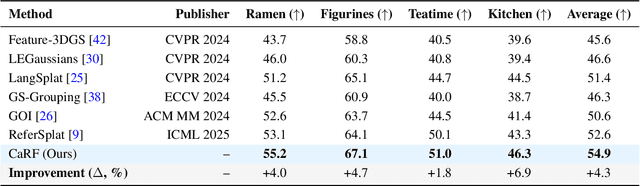
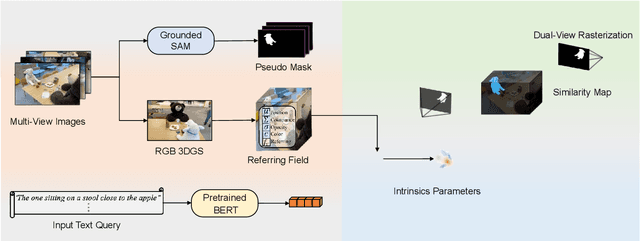
Referring 3D Gaussian Splatting Segmentation (R3DGS) aims to interpret free-form language expressions and localize the corresponding 3D regions in Gaussian fields. While recent advances have introduced cross-modal alignment between language and 3D geometry, existing pipelines still struggle with cross-view consistency due to their reliance on 2D rendered pseudo supervision and view specific feature learning. In this work, we present Camera Aware Referring Field (CaRF), a fully differentiable framework that operates directly in the 3D Gaussian space and achieves multi view consistency. Specifically, CaRF introduces Gaussian Field Camera Encoding (GFCE), which incorporates camera geometry into Gaussian text interactions to explicitly model view dependent variations and enhance geometric reasoning. Building on this, In Training Paired View Supervision (ITPVS) is proposed to align per Gaussian logits across calibrated views during training, effectively mitigating single view overfitting and exposing inter view discrepancies for optimization. Extensive experiments on three representative benchmarks demonstrate that CaRF achieves average improvements of 16.8%, 4.3%, and 2.0% in mIoU over state of the art methods on the Ref LERF, LERF OVS, and 3D OVS datasets, respectively. Moreover, this work promotes more reliable and view consistent 3D scene understanding, with potential benefits for embodied AI, AR/VR interaction, and autonomous perception.
Continual Action Quality Assessment via Adaptive Manifold-Aligned Graph Regularization
Oct 08, 2025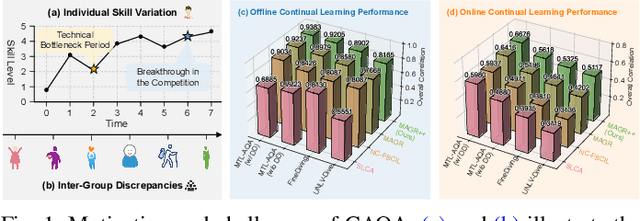
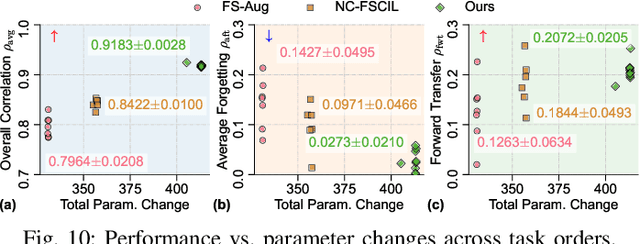
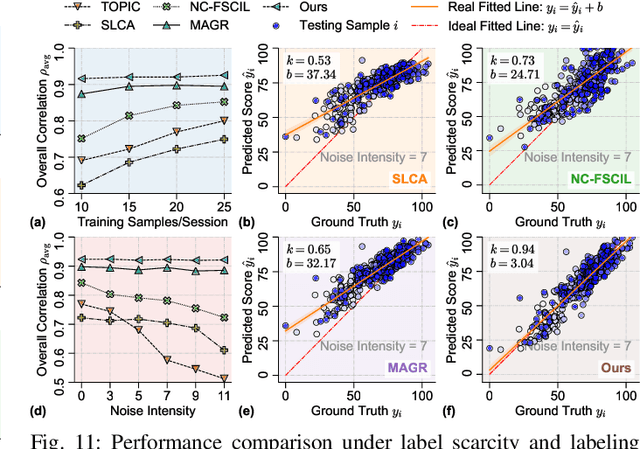
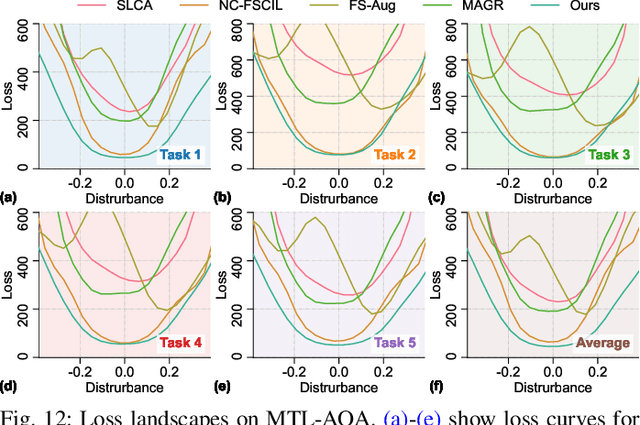
Action Quality Assessment (AQA) quantifies human actions in videos, supporting applications in sports scoring, rehabilitation, and skill evaluation. A major challenge lies in the non-stationary nature of quality distributions in real-world scenarios, which limits the generalization ability of conventional methods. We introduce Continual AQA (CAQA), which equips AQA with Continual Learning (CL) capabilities to handle evolving distributions while mitigating catastrophic forgetting. Although parameter-efficient fine-tuning of pretrained models has shown promise in CL for image classification, we find it insufficient for CAQA. Our empirical and theoretical analyses reveal two insights: (i) Full-Parameter Fine-Tuning (FPFT) is necessary for effective representation learning; yet (ii) uncontrolled FPFT induces overfitting and feature manifold shift, thereby aggravating forgetting. To address this, we propose Adaptive Manifold-Aligned Graph Regularization (MAGR++), which couples backbone fine-tuning that stabilizes shallow layers while adapting deeper ones with a two-step feature rectification pipeline: a manifold projector to translate deviated historical features into the current representation space, and a graph regularizer to align local and global distributions. We construct four CAQA benchmarks from three datasets with tailored evaluation protocols and strong baselines, enabling systematic cross-dataset comparison. Extensive experiments show that MAGR++ achieves state-of-the-art performance, with average correlation gains of 3.6% offline and 12.2% online over the strongest baseline, confirming its robustness and effectiveness. Our code is available at https://github.com/ZhouKanglei/MAGRPP.
PHI: Bridging Domain Shift in Long-Term Action Quality Assessment via Progressive Hierarchical Instruction
May 26, 2025Long-term Action Quality Assessment (AQA) aims to evaluate the quantitative performance of actions in long videos. However, existing methods face challenges due to domain shifts between the pre-trained large-scale action recognition backbones and the specific AQA task, thereby hindering their performance. This arises since fine-tuning resource-intensive backbones on small AQA datasets is impractical. We address this by identifying two levels of domain shift: task-level, regarding differences in task objectives, and feature-level, regarding differences in important features. For feature-level shifts, which are more detrimental, we propose Progressive Hierarchical Instruction (PHI) with two strategies. First, Gap Minimization Flow (GMF) leverages flow matching to progressively learn a fast flow path that reduces the domain gap between initial and desired features across shallow to deep layers. Additionally, a temporally-enhanced attention module captures long-range dependencies essential for AQA. Second, List-wise Contrastive Regularization (LCR) facilitates coarse-to-fine alignment by comprehensively comparing batch pairs to learn fine-grained cues while mitigating domain shift. Integrating these modules, PHI offers an effective solution. Experiments demonstrate that PHI achieves state-of-the-art performance on three representative long-term AQA datasets, proving its superiority in addressing the domain shift for long-term AQA.
FineCausal: A Causal-Based Framework for Interpretable Fine-Grained Action Quality Assessment
Mar 31, 2025Action quality assessment (AQA) is critical for evaluating athletic performance, informing training strategies, and ensuring safety in competitive sports. However, existing deep learning approaches often operate as black boxes and are vulnerable to spurious correlations, limiting both their reliability and interpretability. In this paper, we introduce FineCausal, a novel causal-based framework that achieves state-of-the-art performance on the FineDiving-HM dataset. Our approach leverages a Graph Attention Network-based causal intervention module to disentangle human-centric foreground cues from background confounders, and incorporates a temporal causal attention module to capture fine-grained temporal dependencies across action stages. This dual-module strategy enables FineCausal to generate detailed spatio-temporal representations that not only achieve state-of-the-art scoring performance but also provide transparent, interpretable feedback on which features drive the assessment. Despite its strong performance, FineCausal requires extensive expert knowledge to define causal structures and depends on high-quality annotations, challenges that we discuss and address as future research directions. Code is available at https://github.com/Harrison21/FineCausal.
Adaptive Score Alignment Learning for Continual Perceptual Quality Assessment of 360-Degree Videos in Virtual Reality
Feb 27, 2025Virtual Reality Video Quality Assessment (VR-VQA) aims to evaluate the perceptual quality of 360-degree videos, which is crucial for ensuring a distortion-free user experience. Traditional VR-VQA methods trained on static datasets with limited distortion diversity struggle to balance correlation and precision. This becomes particularly critical when generalizing to diverse VR content and continually adapting to dynamic and evolving video distribution variations. To address these challenges, we propose a novel approach for assessing the perceptual quality of VR videos, Adaptive Score Alignment Learning (ASAL). ASAL integrates correlation loss with error loss to enhance alignment with human subjective ratings and precision in predicting perceptual quality. In particular, ASAL can naturally adapt to continually changing distributions through a feature space smoothing process that enhances generalization to unseen content. To further improve continual adaptation to dynamic VR environments, we extend ASAL with adaptive memory replay as a novel Continul Learning (CL) framework. Unlike traditional CL models, ASAL utilizes key frame extraction and feature adaptation to address the unique challenges of non-stationary variations with both the computation and storage restrictions of VR devices. We establish a comprehensive benchmark for VR-VQA and its CL counterpart, introducing new data splits and evaluation metrics. Our experiments demonstrate that ASAL outperforms recent strong baseline models, achieving overall correlation gains of up to 4.78\% in the static joint training setting and 12.19\% in the dynamic CL setting on various datasets. This validates the effectiveness of ASAL in addressing the inherent challenges of VR-VQA.Our code is available at https://github.com/ZhouKanglei/ASAL_CVQA.
A Comprehensive Survey of Action Quality Assessment: Method and Benchmark
Dec 15, 2024Action Quality Assessment (AQA) quantitatively evaluates the quality of human actions, providing automated assessments that reduce biases in human judgment. Its applications span domains such as sports analysis, skill assessment, and medical care. Recent advances in AQA have introduced innovative methodologies, but similar methods often intertwine across different domains, highlighting the fragmented nature that hinders systematic reviews. In addition, the lack of a unified benchmark and limited computational comparisons hinder consistent evaluation and fair assessment of AQA approaches. In this work, we address these gaps by systematically analyzing over 150 AQA-related papers to develop a hierarchical taxonomy, construct a unified benchmark, and provide an in-depth analysis of current trends, challenges, and future directions. Our hierarchical taxonomy categorizes AQA methods based on input modalities (video, skeleton, multi-modal) and their specific characteristics, highlighting the evolution and interrelations across various approaches. To promote standardization, we present a unified benchmark, integrating diverse datasets to evaluate the assessment precision and computational efficiency. Finally, we review emerging task-specific applications and identify under-explored challenges in AQA, providing actionable insights into future research directions. This survey aims to deepen understanding of AQA progress, facilitate method comparison, and guide future innovations. The project web page can be found at https://ZhouKanglei.github.io/AQA-Survey.
CoFInAl: Enhancing Action Quality Assessment with Coarse-to-Fine Instruction Alignment
Apr 22, 2024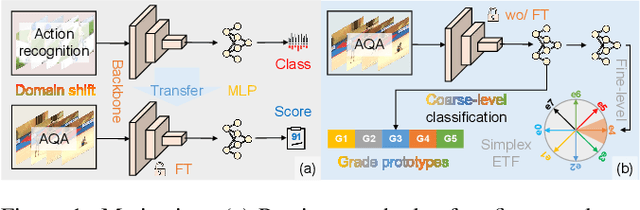
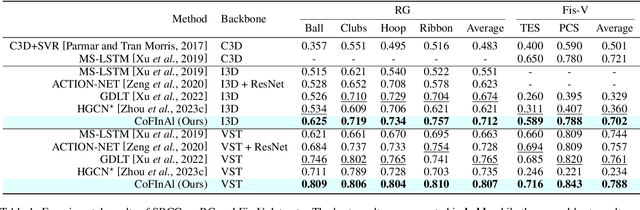
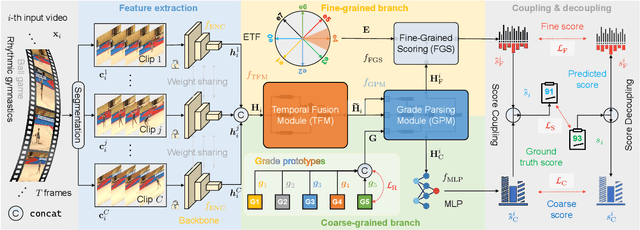

Action Quality Assessment (AQA) is pivotal for quantifying actions across domains like sports and medical care. Existing methods often rely on pre-trained backbones from large-scale action recognition datasets to boost performance on smaller AQA datasets. However, this common strategy yields suboptimal results due to the inherent struggle of these backbones to capture the subtle cues essential for AQA. Moreover, fine-tuning on smaller datasets risks overfitting. To address these issues, we propose Coarse-to-Fine Instruction Alignment (CoFInAl). Inspired by recent advances in large language model tuning, CoFInAl aligns AQA with broader pre-trained tasks by reformulating it as a coarse-to-fine classification task. Initially, it learns grade prototypes for coarse assessment and then utilizes fixed sub-grade prototypes for fine-grained assessment. This hierarchical approach mirrors the judging process, enhancing interpretability within the AQA framework. Experimental results on two long-term AQA datasets demonstrate CoFInAl achieves state-of-the-art performance with significant correlation gains of 5.49% and 3.55% on Rhythmic Gymnastics and Fis-V, respectively. Our code is available at https://github.com/ZhouKanglei/CoFInAl_AQA.
MAGR: Manifold-Aligned Graph Regularization for Continual Action Quality Assessment
Mar 07, 2024Action Quality Assessment (AQA) evaluates diverse skills but models struggle with non-stationary data. We propose Continual AQA (CAQA) to refine models using sparse new data. Feature replay preserves memory without storing raw inputs. However, the misalignment between static old features and the dynamically changing feature manifold causes severe catastrophic forgetting. To address this novel problem, we propose Manifold-Aligned Graph Regularization (MAGR), which first aligns deviated old features to the current feature manifold, ensuring representation consistency. It then constructs a graph jointly arranging old and new features aligned with quality scores. Experiments show MAGR outperforms recent strong baselines with up to 6.56%, 5.66%, 15.64%, and 9.05% correlation gains on the MTL-AQA, FineDiving, UNLV-Dive, and JDM-MSA split datasets, respectively. This validates MAGR for continual assessment challenges arising from non-stationary skill variations.