 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey of Action Quality Assessment: Method and Benchmark
Dec 15, 2024Action Quality Assessment (AQA) quantitatively evaluates the quality of human actions, providing automated assessments that reduce biases in human judgment. Its applications span domains such as sports analysis, skill assessment, and medical care. Recent advances in AQA have introduced innovative methodologies, but similar methods often intertwine across different domains, highlighting the fragmented nature that hinders systematic reviews. In addition, the lack of a unified benchmark and limited computational comparisons hinder consistent evaluation and fair assessment of AQA approaches. In this work, we address these gaps by systematically analyzing over 150 AQA-related papers to develop a hierarchical taxonomy, construct a unified benchmark, and provide an in-depth analysis of current trends, challenges, and future directions. Our hierarchical taxonomy categorizes AQA methods based on input modalities (video, skeleton, multi-modal) and their specific characteristics, highlighting the evolution and interrelations across various approaches. To promote standardization, we present a unified benchmark, integrating diverse datasets to evaluate the assessment precision and computational efficiency. Finally, we review emerging task-specific applications and identify under-explored challenges in AQA, providing actionable insights into future research directions. This survey aims to deepen understanding of AQA progress, facilitate method comparison, and guide future innovations. The project web page can be found at https://ZhouKanglei.github.io/AQA-Survey.
CoFInAl: Enhancing Action Quality Assessment with Coarse-to-Fine Instruction Alignment
Apr 22, 2024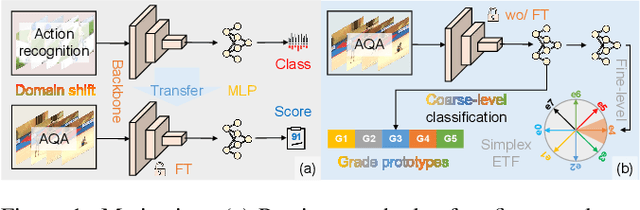
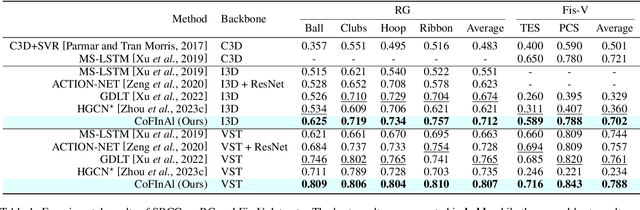
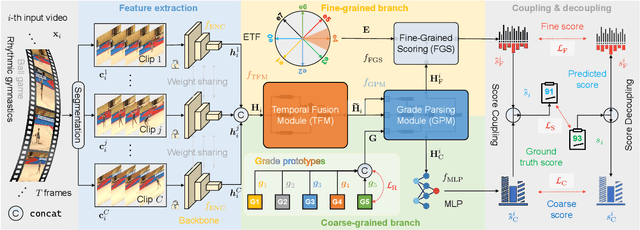

Action Quality Assessment (AQA) is pivotal for quantifying actions across domains like sports and medical care. Existing methods often rely on pre-trained backbones from large-scale action recognition datasets to boost performance on smaller AQA datasets. However, this common strategy yields suboptimal results due to the inherent struggle of these backbones to capture the subtle cues essential for AQA. Moreover, fine-tuning on smaller datasets risks overfitting. To address these issues, we propose Coarse-to-Fine Instruction Alignment (CoFInAl). Inspired by recent advances in large language model tuning, CoFInAl aligns AQA with broader pre-trained tasks by reformulating it as a coarse-to-fine classification task. Initially, it learns grade prototypes for coarse assessment and then utilizes fixed sub-grade prototypes for fine-grained assessment. This hierarchical approach mirrors the judging process, enhancing interpretability within the AQA framework. Experimental results on two long-term AQA datasets demonstrate CoFInAl achieves state-of-the-art performance with significant correlation gains of 5.49% and 3.55% on Rhythmic Gymnastics and Fis-V, respectively. Our code is available at https://github.com/ZhouKanglei/CoFInAl_AQA.