 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCBANet: A Compact Attention-Based CNN-BiLSTM Network for Aggressive Driving Event Detection
May 22, 2026Aggressive driving is a major cause of traffic accidents and poses a serious threat to road safety. Although deep learning methods have shown promising results in detecting risky driving behaviours from vehicle sensor data, their performance in real-world conditions is often limited by severe data imbalance, large variability between drivers, and the lack of physically interpretable vehicle dynamics representations. In this paper, we propose an enhanced deep learning framework for aggressive driving detection using multivariate vehicle dynamics signals. Instead of relying solely on raw measurements, the proposed approach constructs engineered dynamic features that capture steering, acceleration, and braking behaviour. To address the extreme rarity of aggressive events in naturalistic driving data, we introduce a stable training strategy that combines controlled SMOTE-based oversampling with a class-weighted loss formulation, and evaluates focal loss variants for imbalance handling. Furthermore, a safety-oriented decision strategy based on class-specific threshold calibration is adopted to better reflect the asymmetric risks of missed detections and false alarms in real-world applications. The proposed framework is evaluated on a newly collected naturalistic driving dataset. Extensive experiments show that the proposed method consistently outperforms standard deep learning baselines with significant improvements in minority-class recall and safety-critical F-score metrics while maintaining practical computational efficiency. Code: \url {https://github.com/halhamdan/CBANet}
Motion-Adaptive Multi-Scale Temporal Modelling with Skeleton-Constrained Spatial Graphs for Efficient 3D Human Pose Estimation
Apr 04, 2026Accurate 3D human pose estimation from monocular videos requires effective modelling of complex spatial and temporal dependencies. However, existing methods often face challenges in efficiency and adaptability when modelling spatial and temporal dependencies, particularly under dense attention or fixed modelling schemes. In this work, we propose MASC-Pose, a Motion-Adaptive multi-scale temporal modelling framework with Skeleton-Constrained spatial graphs for efficient 3D human pose estimation. Specifically, it introduces an Adaptive Multi-scale Temporal Modelling (AMTM) module to adaptively capture heterogeneous motion dynamics at different temporal scales, together with a Skeleton-constrained Adaptive GCN (SAGCN) for joint-specific spatial interaction modelling. By jointly enabling adaptive temporal reasoning and efficient spatial aggregation, our method achieves strong accuracy with high computational efficiency. Extensive experiments on Human3.6M and MPI-INF-3DHP datasets demonstrate the effectiveness of our approach.
Deep Learning-Enhanced Visual Monitoring in Hazardous Underwater Environments with a Swarm of Micro-Robots
Mar 04, 2025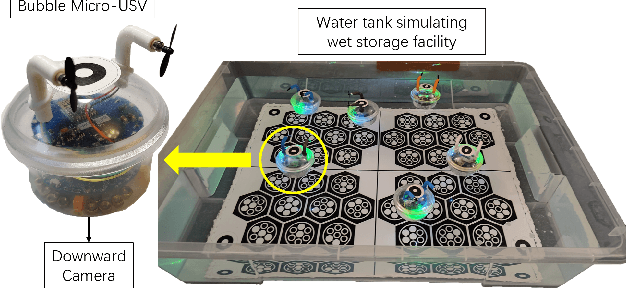
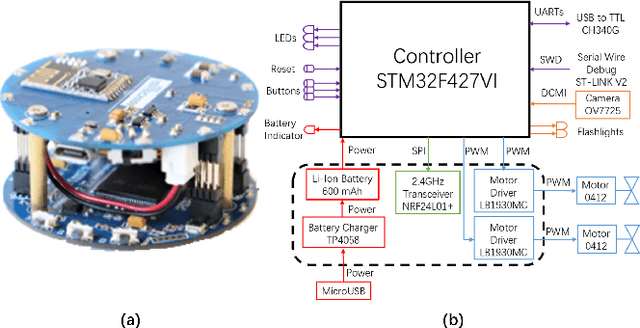
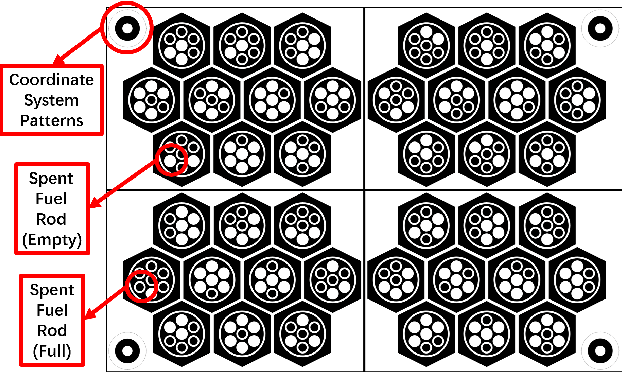
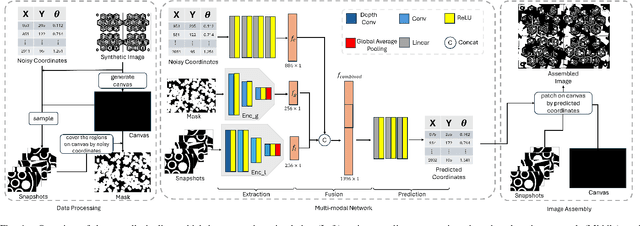
Long-term monitoring and exploration of extreme environments, such as underwater storage facilities, is costly, labor-intensive, and hazardous. Automating this process with low-cost, collaborative robots can greatly improve efficiency. These robots capture images from different positions, which must be processed simultaneously to create a spatio-temporal model of the facility. In this paper, we propose a novel approach that integrates data simulation, a multi-modal deep learning network for coordinate prediction, and image reassembly to address the challenges posed by environmental disturbances causing drift and rotation in the robots' positions and orientations. Our approach enhances the precision of alignment in noisy environments by integrating visual information from snapshots, global positional context from masks, and noisy coordinates. We validate our method through extensive experiments using synthetic data that simulate real-world robotic operations in underwater settings. The results demonstrate very high coordinate prediction accuracy and plausible image assembly, indicating the real-world applicability of our approach. The assembled images provide clear and coherent views of the underwater environment for effective monitoring and inspection, showcasing the potential for broader use in extreme settings, further contributing to improved safety, efficiency, and cost reduction in hazardous field monitoring. Code is available on https://github.com/ChrisChen1023/Micro-Robot-Swarm.
Federated Reinforcement Learning for Collective Navigation of Robotic Swarms
Feb 02, 2022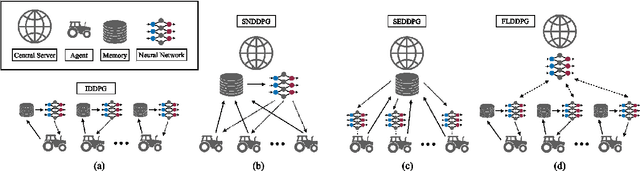
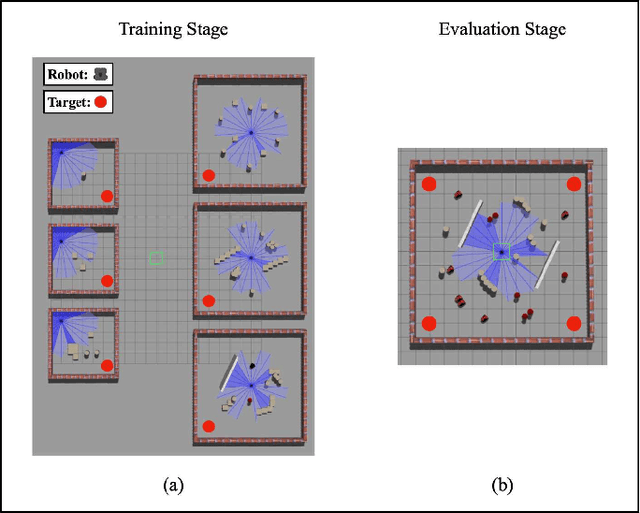
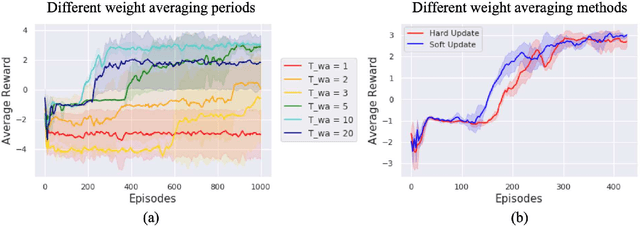
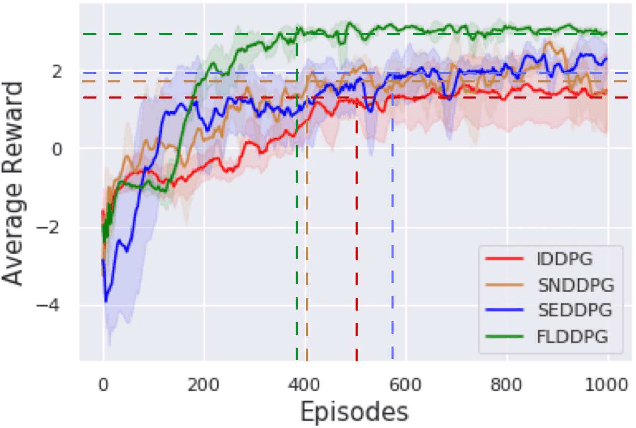
The recent advancement of Deep Reinforcement Learning (DRL) contributed to robotics by allowing automatic controller design. Automatic controller design is a crucial approach for designing swarm robotic systems, which require more complex controller than a single robot system to lead a desired collective behaviour. Although DRL-based controller design method showed its effectiveness, the reliance on the central training server is a critical problem in the real-world environments where the robot-server communication is unstable or limited. We propose a novel Federated Learning (FL) based DRL training strategy for use in swarm robotic applications. As FL reduces the number of robot-server communication by only sharing neural network model weights, not local data samples, the proposed strategy reduces the reliance on the central server during controller training with DRL. The experimental results from the collective learning scenario showed that the proposed FL-based strategy dramatically reduced the number of communication by minimum 1600 times and even increased the success rate of navigation with the trained controller by 2.8 times compared to the baseline strategies that share a central server. The results suggest that our proposed strategy can efficiently train swarm robotic systems in the real-world environments with the limited robot-server communication, e.g. agri-robotics, underwater and damaged nuclear facilities.
Accelerated Sim-to-Real Deep Reinforcement Learning: Learning Collision Avoidance from Human Player
Feb 23, 2021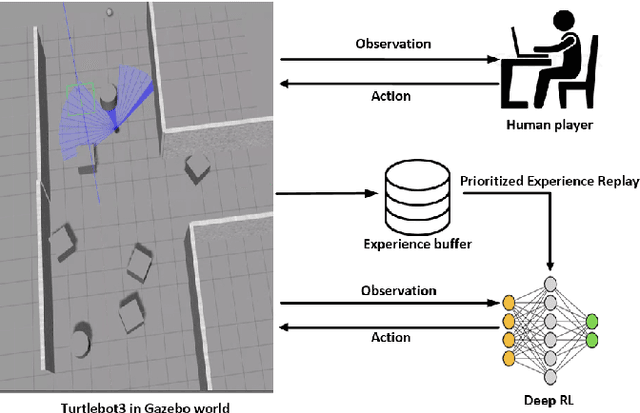
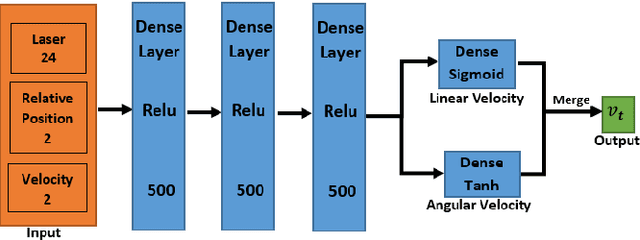
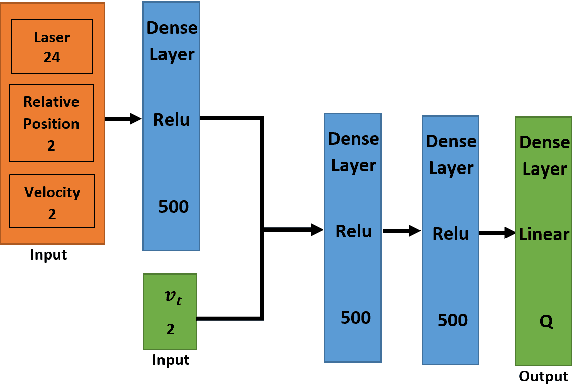
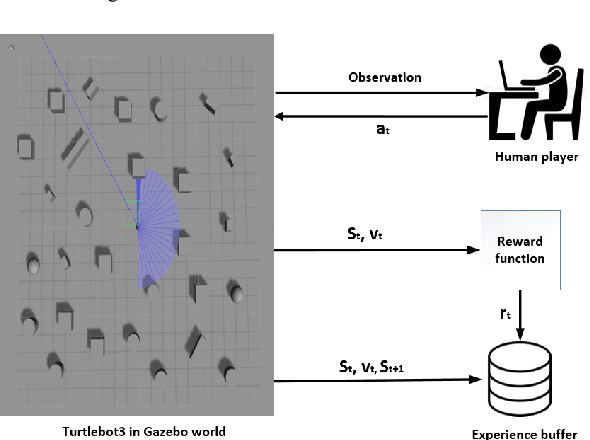
This paper presents a sensor-level mapless collision avoidance algorithm for use in mobile robots that map raw sensor data to linear and angular velocities and navigate in an unknown environment without a map. An efficient training strategy is proposed to allow a robot to learn from both human experience data and self-exploratory data. A game format simulation framework is designed to allow the human player to tele-operate the mobile robot to a goal and human action is also scored using the reward function. Both human player data and self-playing data are sampled using prioritized experience replay algorithm. The proposed algorithm and training strategy have been evaluated in two different experimental configurations: \textit{Environment 1}, a simulated cluttered environment, and \textit{Environment 2}, a simulated corridor environment, to investigate the performance. It was demonstrated that the proposed method achieved the same level of reward using only 16\% of the training steps required by the standard Deep Deterministic Policy Gradient (DDPG) method in Environment 1 and 20\% of that in Environment 2. In the evaluation of 20 random missions, the proposed method achieved no collision in less than 2~h and 2.5~h of training time in the two Gazebo environments respectively. The method also generated smoother trajectories than DDPG. The proposed method has also been implemented on a real robot in the real-world environment for performance evaluation. We can confirm that the trained model with the simulation software can be directly applied into the real-world scenario without further fine-tuning, further demonstrating its higher robustness than DDPG. The video and code are available: https://youtu.be/BmwxevgsdGc https://github.com/hanlinniu/turtlebot3_ddpg_collision_avoidance
Cooperative Pollution Source Localization and Cleanup with a Bio-inspired Swarm Robot Aggregation
Jul 22, 2019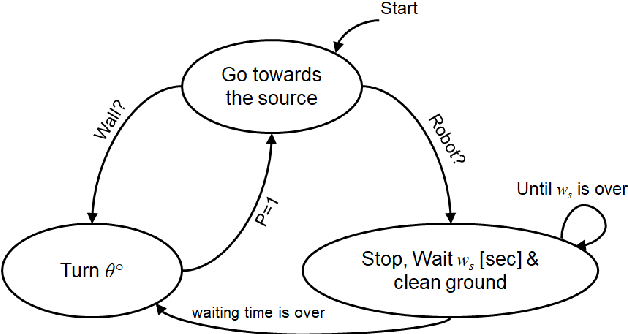



Using robots for exploration of extreme and hazardous environments has the potential to significantly improve human safety. For example, robotic solutions can be deployed to find the source of a chemical leakage and clean the contaminated area. This paper demonstrates a proof-of-concept bio-inspired exploration method using a swarm robotic system, which is based on a combination of two bio-inspired behaviours: aggregation, and pheromone tracking. The main idea of the work presented is to follow pheromone trails to find the source of a chemical leakage and then carry out a decontamination task by aggregating at the critical zone. Using experiments conducted by a simulated model of a Mona robot, we evaluate the effects of population size and robot speed on the ability of the swarm in a decontamination task. The results indicate the feasibility of deploying robotic swarms in an exploration and cleaning task in an extreme environment.
Self-organized Collective Motion with a Simulated Real Robot Swarm
Apr 05, 2019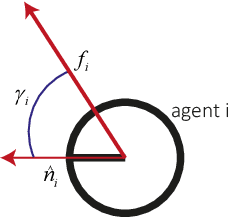
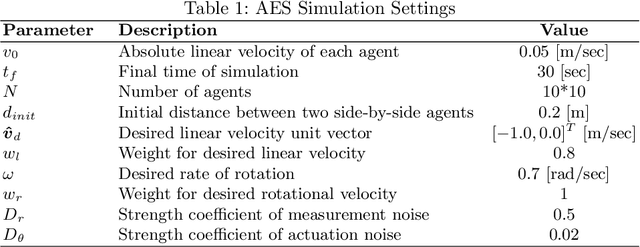

Collective motion is one of the most fascinating phenomena observed in the nature. In the last decade, it aroused so much attention in physics, control and robotics fields. In particular, many studies have been done in swarm robotics related to collective motion, also called flocking. In most of these studies, robots use orientation and proximity of their neighbors to achieve collective motion. In such an approach, one of the biggest problems is to measure orientation information using on-board sensors. In most of the studies, this information is either simulated or implemented using communication. In this paper, to the best of our knowledge, we implemented a fully autonomous coordinated motion without alignment using very simple Mona robots. We used an approach based on Active Elastic Sheet (AES) method. We modified the method and added the capability to enable the swarm to move toward a desired direction and rotate about an arbitrary point. The parameters of the modified method are optimized using TCACS optimization algorithm. We tested our approach in different settings using Matlab and Webots.
Omnipotent Virtual Giant for Remote Human-Swarm Interaction
Apr 01, 2019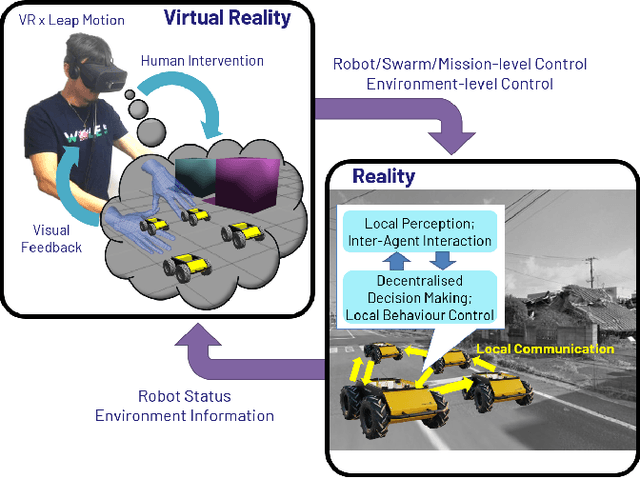
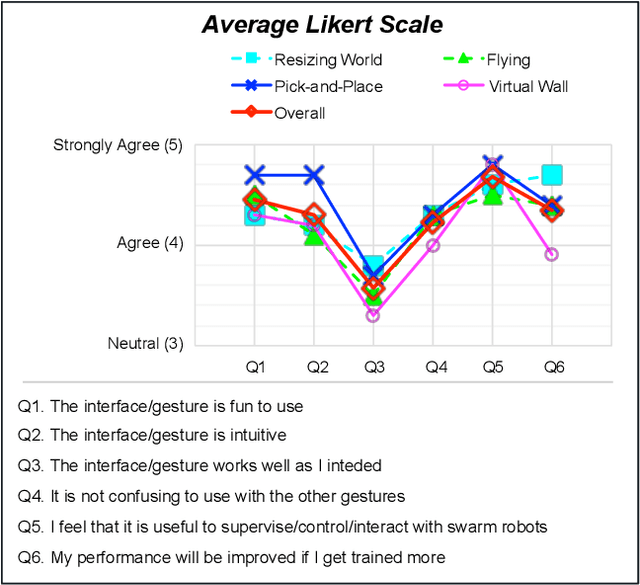
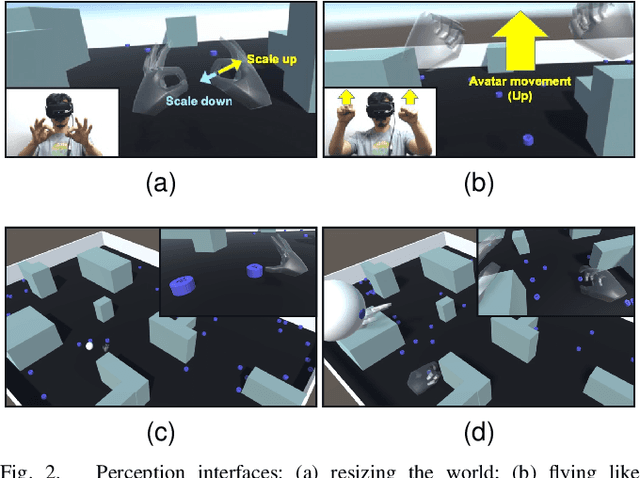

This paper proposes an intuitive human-swarm interaction framework inspired by our childhood memory in which we interacted with living ants by changing their positions and environments as if we were omnipotent relative to the ants. In virtual reality, analogously, we can be a super-powered virtual giant who can supervise a swarm of mobile robots in a vast and remote environment by flying over or resizing the world and coordinate them by picking and placing a robot or creating virtual walls. This work implements this idea by using Virtual Reality along with Leap Motion, which is then validated by proof-of-concept experiments using real and virtual mobile robots in mixed reality. We conduct a usability analysis to quantify the effectiveness of the overall system as well as the individual interfaces proposed in this work. The results revealed that the proposed method is intuitive and feasible for interaction with swarm robots, but may require appropriate training for the new end-user interface device.