 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInsights from the Use of Previously Unseen Neural Architecture Search Datasets
Apr 02, 2024The boundless possibility of neural networks which can be used to solve a problem -- each with different performance -- leads to a situation where a Deep Learning expert is required to identify the best neural network. This goes against the hope of removing the need for experts. Neural Architecture Search (NAS) offers a solution to this by automatically identifying the best architecture. However, to date, NAS work has focused on a small set of datasets which we argue are not representative of real-world problems. We introduce eight new datasets created for a series of NAS Challenges: AddNIST, Language, MultNIST, CIFARTile, Gutenberg, Isabella, GeoClassing, and Chesseract. These datasets and challenges are developed to direct attention to issues in NAS development and to encourage authors to consider how their models will perform on datasets unknown to them at development time. We present experimentation using standard Deep Learning methods as well as the best results from challenge participants.
Long-term Reproducibility for Neural Architecture Search
Jul 18, 2022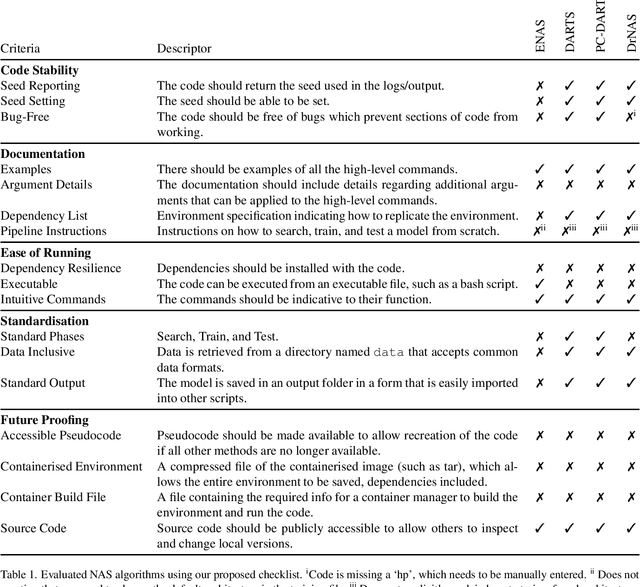
It is a sad reflection of modern academia that code is often ignored after publication -- there is no academic 'kudos' for bug fixes / maintenance. Code is often unavailable or, if available, contains bugs, is incomplete, or relies on out-of-date / unavailable libraries. This has a significant impact on reproducibility and general scientific progress. Neural Architecture Search (NAS) is no exception to this, with some prior work in reproducibility. However, we argue that these do not consider long-term reproducibility issues. We therefore propose a checklist for long-term NAS reproducibility. We evaluate our checklist against common NAS approaches along with proposing how we can retrospectively make these approaches more long-term reproducible.