 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Complexity of Object Detection on Real-world Public Transportation Images for Social Distancing Measurement
Feb 14, 2022
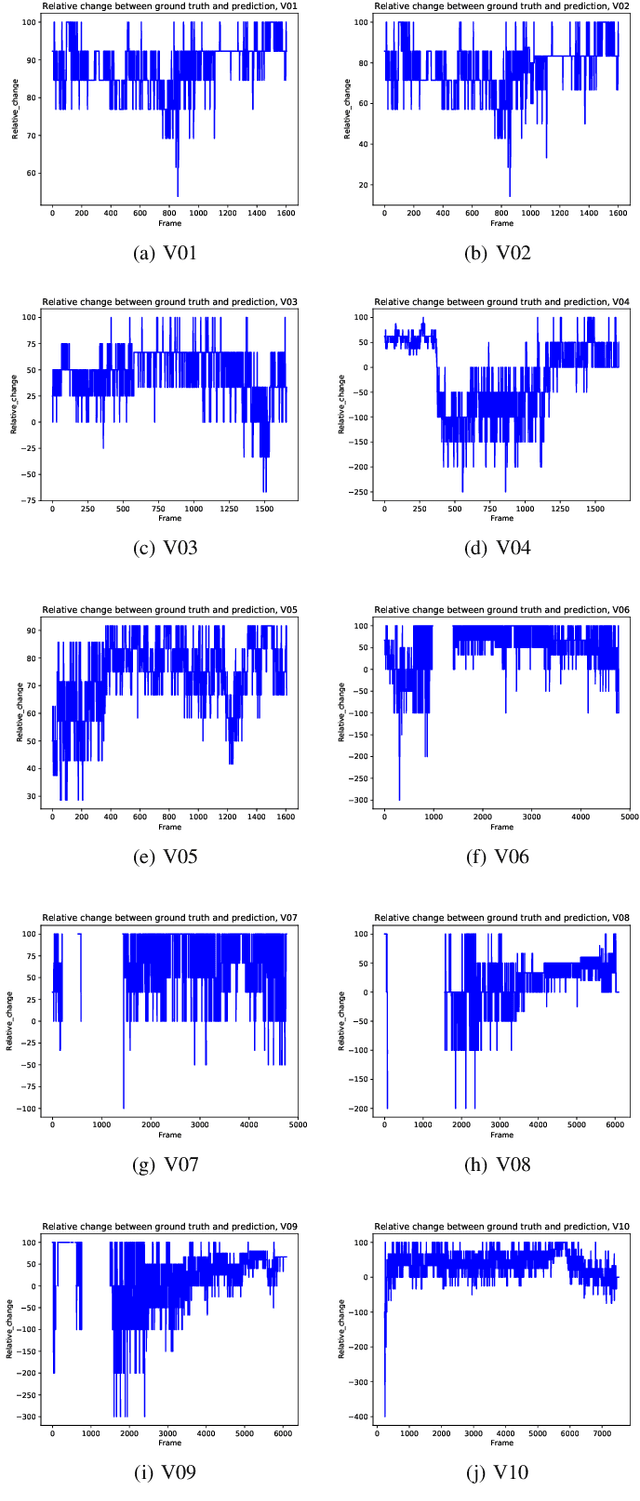


Social distancing in public spaces has become an essential aspect in helping to reduce the impact of the COVID-19 pandemic. Exploiting recent advances in machine learning, there have been many studies in the literature implementing social distancing via object detection through the use of surveillance cameras in public spaces. However, to date, there has been no study of social distance measurement on public transport. The public transport setting has some unique challenges, including some low-resolution images and camera locations that can lead to the partial occlusion of passengers, which make it challenging to perform accurate detection. Thus, in this paper, we investigate the challenges of performing accurate social distance measurement on public transportation. We benchmark several state-of-the-art object detection algorithms using real-world footage taken from the London Underground and bus network. The work highlights the complexity of performing social distancing measurement on images from current public transportation onboard cameras. Further, exploiting domain knowledge of expected passenger behaviour, we attempt to improve the quality of the detections using various strategies and show improvement over using vanilla object detection alone.
Not Half Bad: Exploring Half-Precision in Graph Convolutional Neural Networks
Oct 23, 2020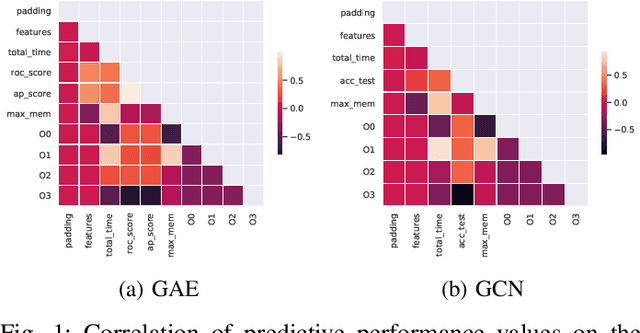
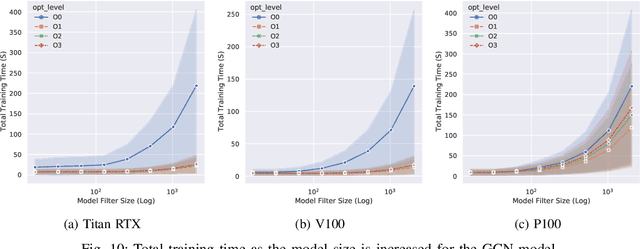
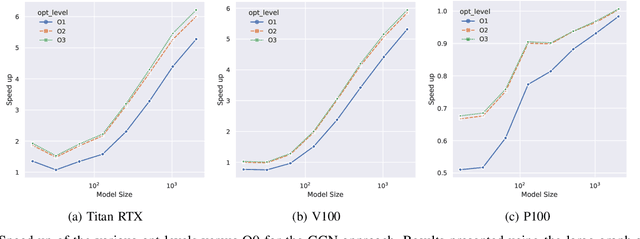
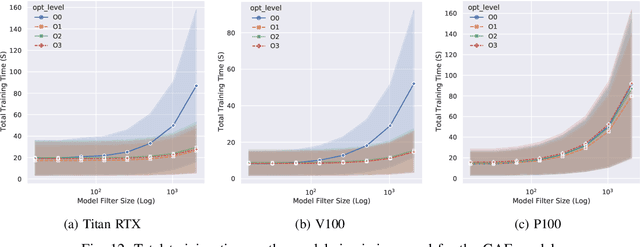
With the growing significance of graphs as an effective representation of data in numerous applications, efficient graph analysis using modern machine learning is receiving a growing level of attention. Deep learning approaches often operate over the entire adjacency matrix -- as the input and intermediate network layers are all designed in proportion to the size of the adjacency matrix -- leading to intensive computation and large memory requirements as the graph size increases. It is therefore desirable to identify efficient measures to reduce both run-time and memory requirements allowing for the analysis of the largest graphs possible. The use of reduced precision operations within the forward and backward passes of a deep neural network along with novel specialised hardware in modern GPUs can offer promising avenues towards efficiency. In this paper, we provide an in-depth exploration of the use of reduced-precision operations, easily integrable into the highly popular PyTorch framework, and an analysis of the effects of Tensor Cores on graph convolutional neural networks. We perform an extensive experimental evaluation of three GPU architectures and two widely-used graph analysis tasks (vertex classification and link prediction) using well-known benchmark and synthetically generated datasets. Thus allowing us to make important observations on the effects of reduced-precision operations and Tensor Cores on computational and memory usage of graph convolutional neural networks -- often neglected in the literature.
Gradient descent with momentum --- to accelerate or to super-accelerate?
Jan 17, 2020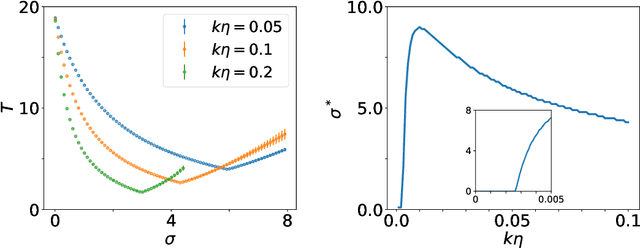
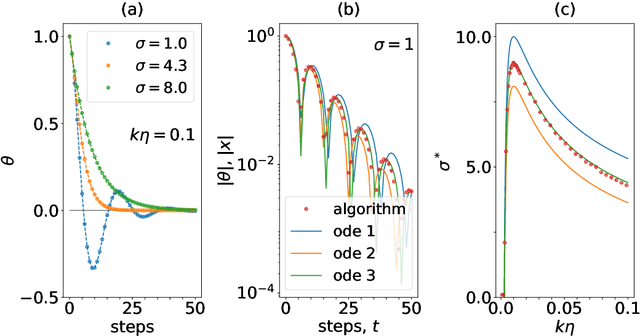
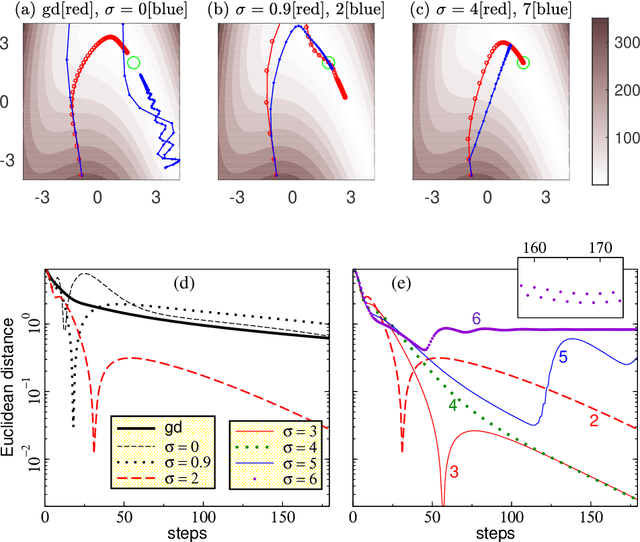
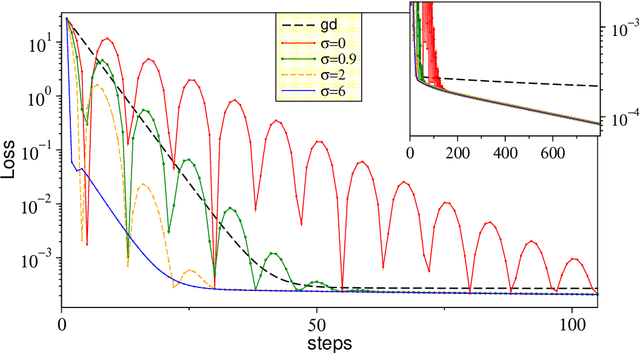
We consider gradient descent with `momentum', a widely used method for loss function minimization in machine learning. This method is often used with `Nesterov acceleration', meaning that the gradient is evaluated not at the current position in parameter space, but at the estimated position after one step. In this work, we show that the algorithm can be improved by extending this `acceleration' --- by using the gradient at an estimated position several steps ahead rather than just one step ahead. How far one looks ahead in this `super-acceleration' algorithm is determined by a new hyperparameter. Considering a one-parameter quadratic loss function, the optimal value of the super-acceleration can be exactly calculated and analytically estimated. We show explicitly that super-accelerating the momentum algorithm is beneficial, not only for this idealized problem, but also for several synthetic loss landscapes and for the MNIST classification task with neural networks. Super-acceleration is also easy to incorporate into adaptive algorithms like RMSProp or Adam, and is shown to improve these algorithms.
Predicting the Computational Cost of Deep Learning Models
Nov 28, 2018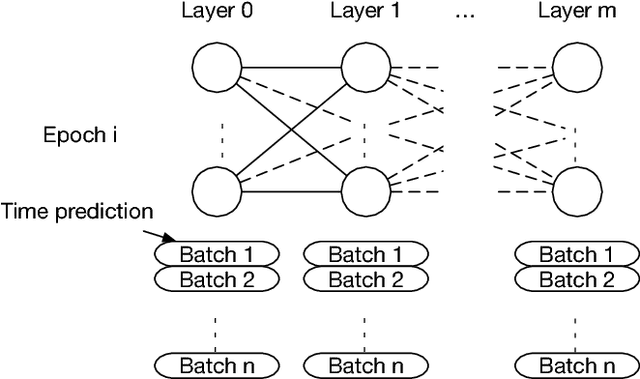
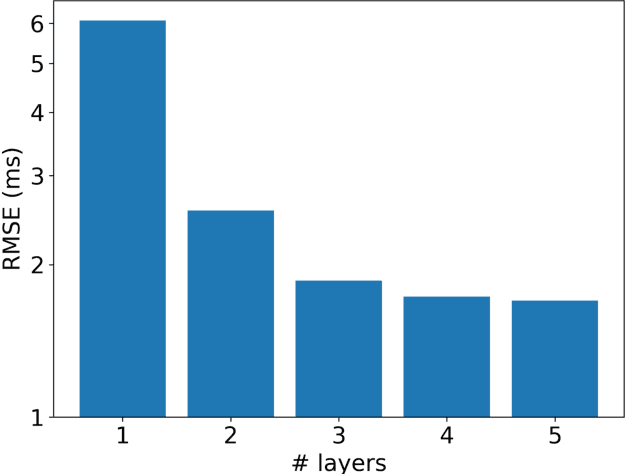
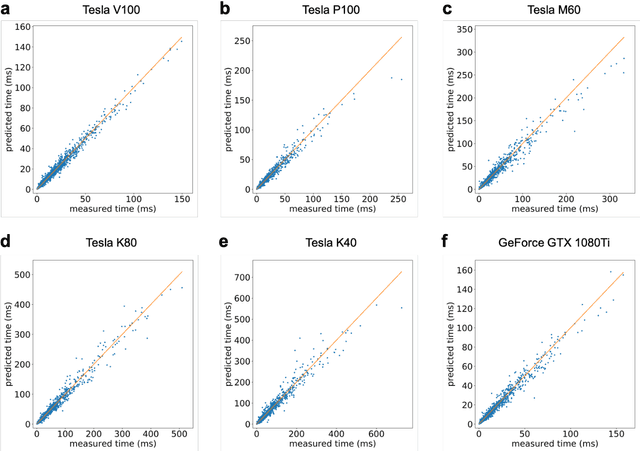
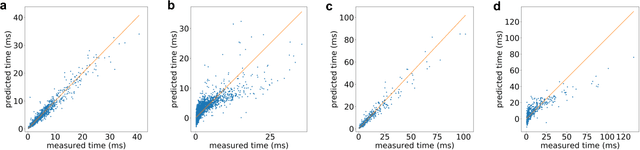
Deep learning is rapidly becoming a go-to tool for many artificial intelligence problems due to its ability to outperform other approaches and even humans at many problems. Despite its popularity we are still unable to accurately predict the time it will take to train a deep learning network to solve a given problem. This training time can be seen as the product of the training time per epoch and the number of epochs which need to be performed to reach the desired level of accuracy. Some work has been carried out to predict the training time for an epoch -- most have been based around the assumption that the training time is linearly related to the number of floating point operations required. However, this relationship is not true and becomes exacerbated in cases where other activities start to dominate the execution time. Such as the time to load data from memory or loss of performance due to non-optimal parallel execution. In this work we propose an alternative approach in which we train a deep learning network to predict the execution time for parts of a deep learning network. Timings for these individual parts can then be combined to provide a prediction for the whole execution time. This has advantages over linear approaches as it can model more complex scenarios. But, also, it has the ability to predict execution times for scenarios unseen in the training data. Therefore, our approach can be used not only to infer the execution time for a batch, or entire epoch, but it can also support making a well-informed choice for the appropriate hardware and model.
Temporal Graph Offset Reconstruction: Towards Temporally Robust Graph Representation Learning
Nov 20, 2018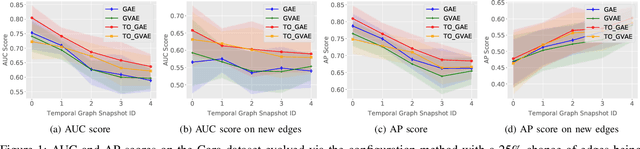
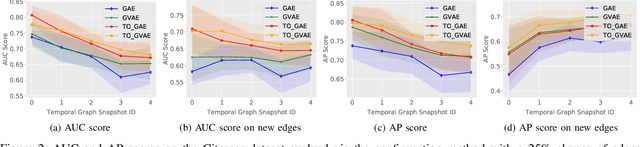
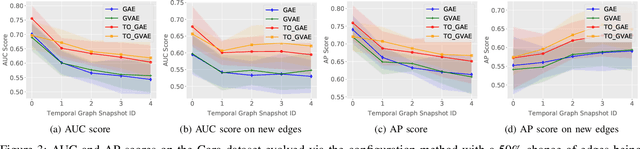
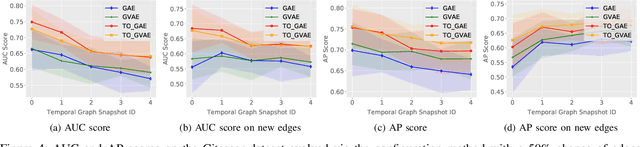
Graphs are a commonly used construct for representing relationships between elements in complex high dimensional datasets. Many real-world phenomenon are dynamic in nature, meaning that any graph used to represent them is inherently temporal. However, many of the machine learning models designed to capture knowledge about the structure of these graphs ignore this rich temporal information when creating representations of the graph. This results in models which do not perform well when used to make predictions about the future state of the graph -- especially when the delta between time stamps is not small. In this work, we explore a novel training procedure and an associated unsupervised model which creates graph representations optimised to predict the future state of the graph. We make use of graph convolutional neural networks to encode the graph into a latent representation, which we then use to train our temporal offset reconstruction method, inspired by auto-encoders, to predict a later time point -- multiple time steps into the future. Using our method, we demonstrate superior performance for the task of future link prediction compared with none-temporal state-of-the-art baselines. We show our approach to be capable of outperforming non-temporal baselines by 38% on a real world dataset.
Using Machine Learning to reduce the energy wasted in Volunteer Computing Environments
Oct 19, 2018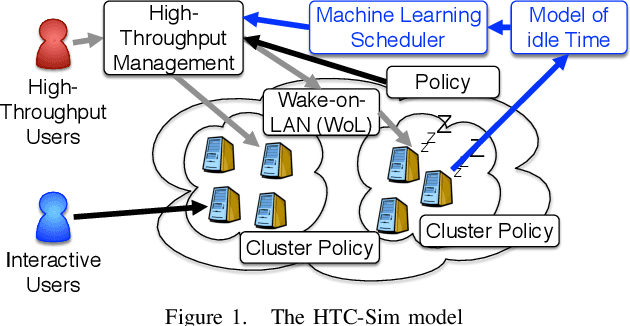
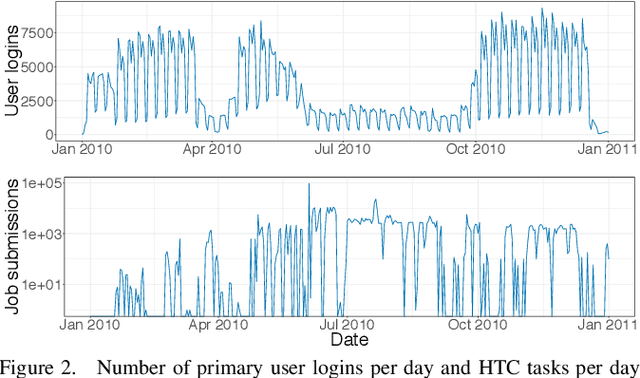
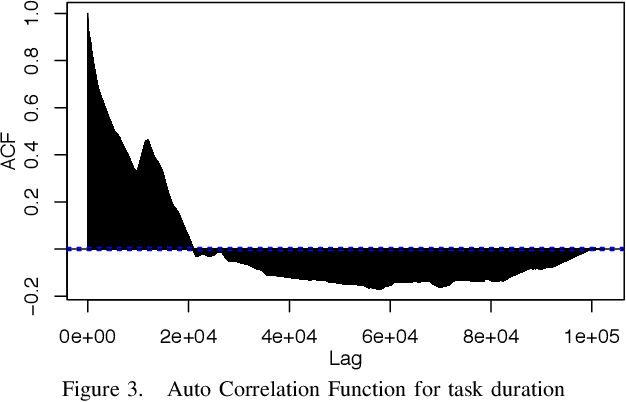
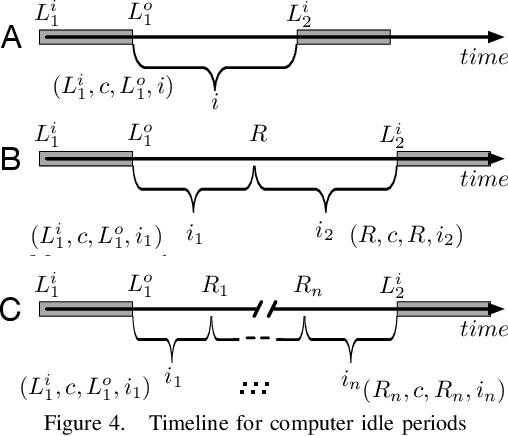
High Throughput Computing (HTC) provides a convenient mechanism for running thousands of tasks. Many HTC systems exploit computers which are provisioned for other purposes by utilising their idle time - volunteer computing. This has great advantages as it gives access to vast quantities of computational power for little or no cost. The downside is that running tasks are sacrificed if the computer is needed for its primary use. Normally terminating the task which must be restarted on a different computer - leading to wasted energy and an increase in task completion time. We demonstrate, through the use of simulation, how we can reduce this wasted energy by targeting tasks at computers less likely to be needed for primary use, predicting this idle time through machine learning. By combining two machine learning approaches, namely Random Forest and MultiLayer Perceptron, we save 51.4% of the energy without significantly affecting the time to complete tasks.
Exploring the Semantic Content of Unsupervised Graph Embeddings: An Empirical Study
Jun 19, 2018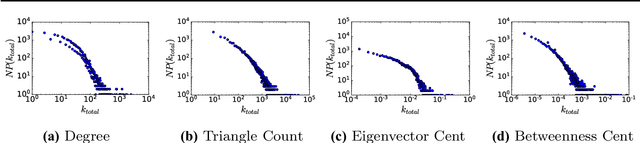
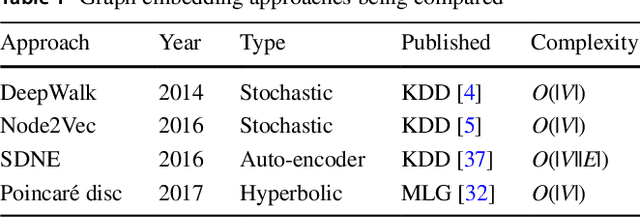
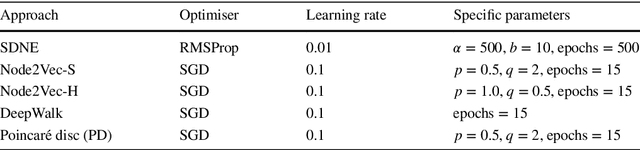
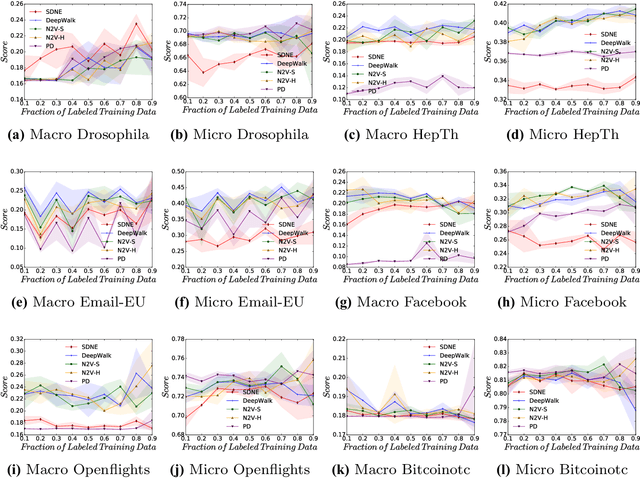
Graph embeddings have become a key and widely used technique within the field of graph mining, proving to be successful across a broad range of domains including social, citation, transportation and biological. Graph embedding techniques aim to automatically create a low-dimensional representation of a given graph, which captures key structural elements in the resulting embedding space. However, to date, there has been little work exploring exactly which topological structures are being learned in the embeddings process. In this paper, we investigate if graph embeddings are approximating something analogous with traditional vertex level graph features. If such a relationship can be found, it could be used to provide a theoretical insight into how graph embedding approaches function. We perform this investigation by predicting known topological features, using supervised and unsupervised methods, directly from the embedding space. If a mapping between the embeddings and topological features can be found, then we argue that the structural information encapsulated by the features is represented in the embedding space. To explore this, we present extensive experimental evaluation from five state-of-the-art unsupervised graph embedding techniques, across a range of empirical graph datasets, measuring a selection of topological features. We demonstrate that several topological features are indeed being approximated by the embedding space, allowing key insight into how graph embeddings create good representations.