 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Half Bad: Exploring Half-Precision in Graph Convolutional Neural Networks
Paper and Code
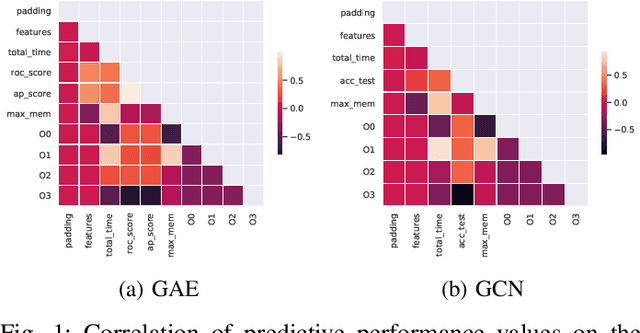
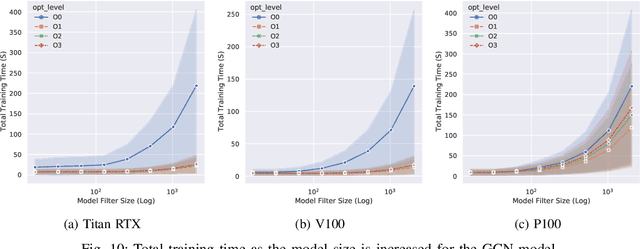
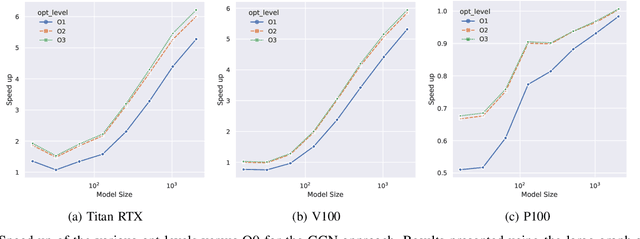
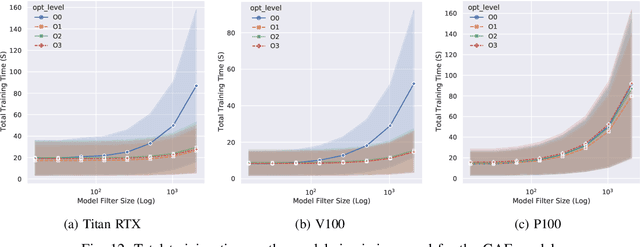
With the growing significance of graphs as an effective representation of data in numerous applications, efficient graph analysis using modern machine learning is receiving a growing level of attention. Deep learning approaches often operate over the entire adjacency matrix -- as the input and intermediate network layers are all designed in proportion to the size of the adjacency matrix -- leading to intensive computation and large memory requirements as the graph size increases. It is therefore desirable to identify efficient measures to reduce both run-time and memory requirements allowing for the analysis of the largest graphs possible. The use of reduced precision operations within the forward and backward passes of a deep neural network along with novel specialised hardware in modern GPUs can offer promising avenues towards efficiency. In this paper, we provide an in-depth exploration of the use of reduced-precision operations, easily integrable into the highly popular PyTorch framework, and an analysis of the effects of Tensor Cores on graph convolutional neural networks. We perform an extensive experimental evaluation of three GPU architectures and two widely-used graph analysis tasks (vertex classification and link prediction) using well-known benchmark and synthetically generated datasets. Thus allowing us to make important observations on the effects of reduced-precision operations and Tensor Cores on computational and memory usage of graph convolutional neural networks -- often neglected in the literature.