 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting the Computational Cost of Deep Learning Models
Paper and Code
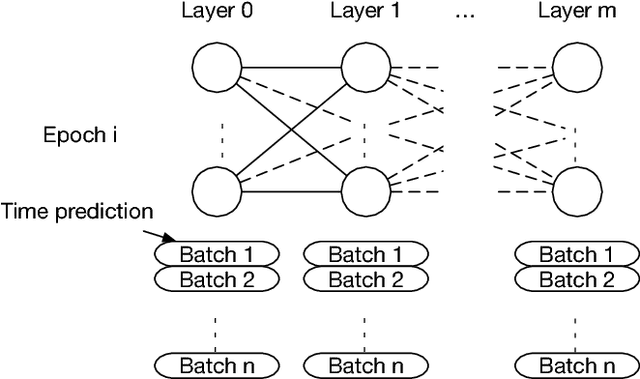
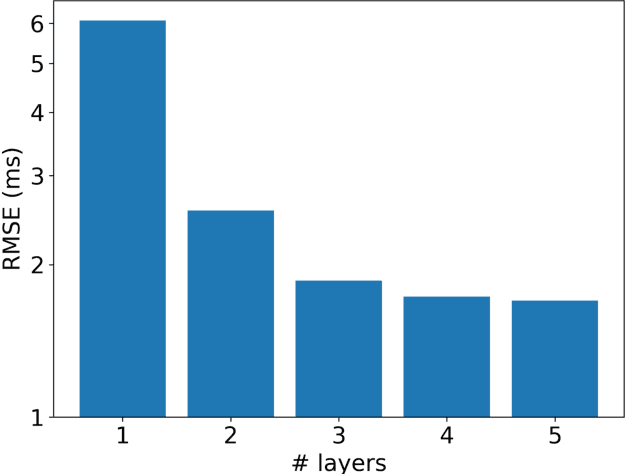
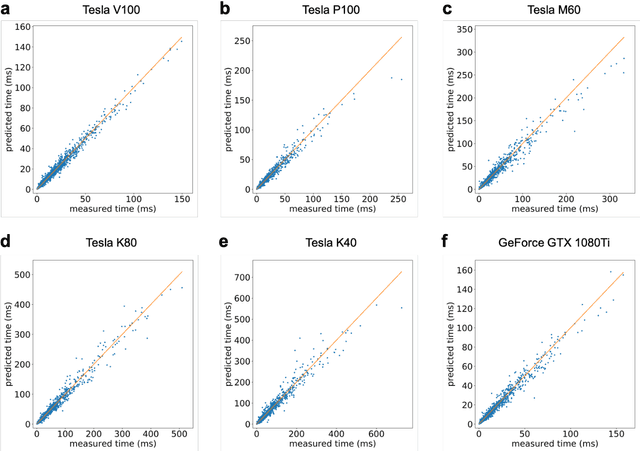
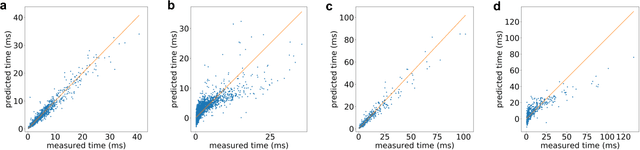
Deep learning is rapidly becoming a go-to tool for many artificial intelligence problems due to its ability to outperform other approaches and even humans at many problems. Despite its popularity we are still unable to accurately predict the time it will take to train a deep learning network to solve a given problem. This training time can be seen as the product of the training time per epoch and the number of epochs which need to be performed to reach the desired level of accuracy. Some work has been carried out to predict the training time for an epoch -- most have been based around the assumption that the training time is linearly related to the number of floating point operations required. However, this relationship is not true and becomes exacerbated in cases where other activities start to dominate the execution time. Such as the time to load data from memory or loss of performance due to non-optimal parallel execution. In this work we propose an alternative approach in which we train a deep learning network to predict the execution time for parts of a deep learning network. Timings for these individual parts can then be combined to provide a prediction for the whole execution time. This has advantages over linear approaches as it can model more complex scenarios. But, also, it has the ability to predict execution times for scenarios unseen in the training data. Therefore, our approach can be used not only to infer the execution time for a batch, or entire epoch, but it can also support making a well-informed choice for the appropriate hardware and model.