 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient descent with momentum --- to accelerate or to super-accelerate?
Jan 17, 2020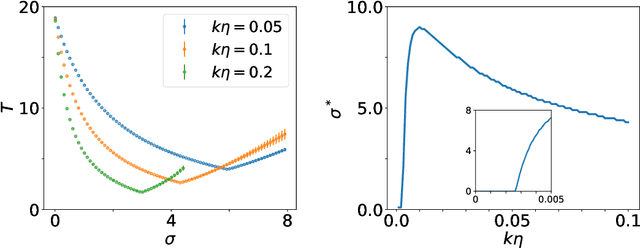
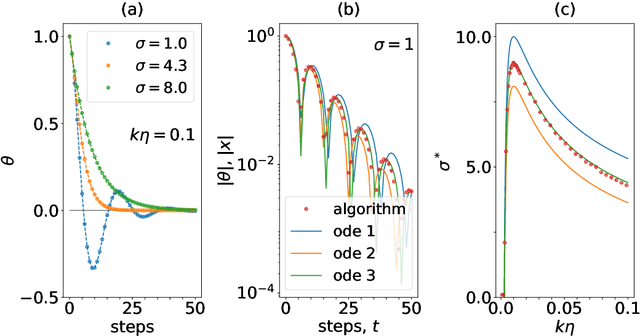
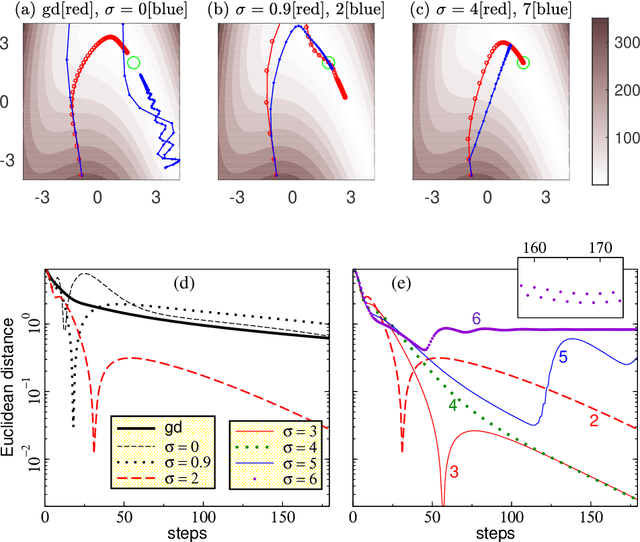
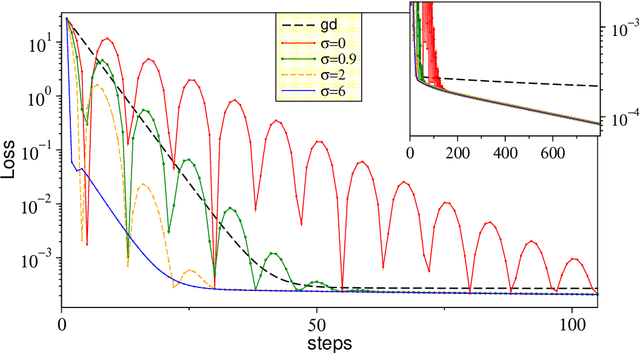
We consider gradient descent with `momentum', a widely used method for loss function minimization in machine learning. This method is often used with `Nesterov acceleration', meaning that the gradient is evaluated not at the current position in parameter space, but at the estimated position after one step. In this work, we show that the algorithm can be improved by extending this `acceleration' --- by using the gradient at an estimated position several steps ahead rather than just one step ahead. How far one looks ahead in this `super-acceleration' algorithm is determined by a new hyperparameter. Considering a one-parameter quadratic loss function, the optimal value of the super-acceleration can be exactly calculated and analytically estimated. We show explicitly that super-accelerating the momentum algorithm is beneficial, not only for this idealized problem, but also for several synthetic loss landscapes and for the MNIST classification task with neural networks. Super-acceleration is also easy to incorporate into adaptive algorithms like RMSProp or Adam, and is shown to improve these algorithms.