 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Body Shape Classification Based on a Single Image
May 29, 2023



There is high demand for online fashion recommender systems that incorporate the needs of the consumer's body shape. As such, we present a methodology to classify human body shape from a single image. This is achieved through the use of instance segmentation and keypoint estimation models, trained only on open-source benchmarking datasets. The system is capable of performing in noisy environments owing to to robust background subtraction. The proposed methodology does not require 3D body recreation as a result of classification based on estimated keypoints, nor requires historical information about a user to operate - calculating all required measurements at the point of use. We evaluate our methodology both qualitatively against existing body shape classifiers and quantitatively against a novel dataset of images, which we provide for use to the community. The resultant body shape classification can be utilised in a variety of downstream tasks, such as input to size and fit recommendation or virtual try-on systems.
Towards Automatic Cetacean Photo-Identification: A Framework for Fine-Grain, Few-Shot Learning in Marine Ecology
Dec 07, 2022



Photo-identification (photo-id) is one of the main non-invasive capture-recapture methods utilised by marine researchers for monitoring cetacean (dolphin, whale, and porpoise) populations. This method has historically been performed manually resulting in high workload and cost due to the vast number of images collected. Recently automated aids have been developed to help speed-up photo-id, although they are often disjoint in their processing and do not utilise all available identifying information. Work presented in this paper aims to create a fully automatic photo-id aid capable of providing most likely matches based on all available information without the need for data pre-processing such as cropping. This is achieved through a pipeline of computer vision models and post-processing techniques aimed at detecting cetaceans in unedited field imagery before passing them downstream for individual level catalogue matching. The system is capable of handling previously uncatalogued individuals and flagging these for investigation thanks to catalogue similarity comparison. We evaluate the system against multiple real-life photo-id catalogues, achieving mAP@IOU[0.5] = 0.91, 0.96 for the task of dorsal fin detection on catalogues from Tanzania and the UK respectively and 83.1, 97.5% top-10 accuracy for the task of individual classification on catalogues from the UK and USA.
Application of deep learning to camera trap data for ecologists in planning / engineering -- Can captivity imagery train a model which generalises to the wild?
Nov 24, 2021
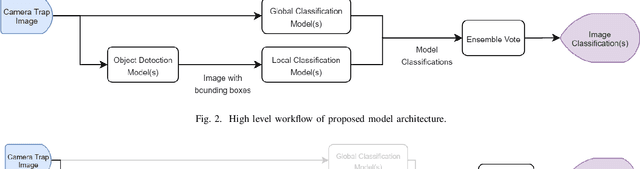


Understanding the abundance of a species is the first step towards understanding both its long-term sustainability and the impact that we may be having upon it. Ecologists use camera traps to remotely survey for the presence of specific animal species. Previous studies have shown that deep learning models can be trained to automatically detect and classify animals within camera trap imagery with high levels of confidence. However, the ability to train these models is reliant upon having enough high-quality training data. What happens when the animal is rare or the data sets are non-existent? This research proposes an approach of using images of rare animals in captivity (focusing on the Scottish wildcat) to generate the training dataset. We explore the challenges associated with generalising a model trained on captivity data when applied to data collected in the wild. The research is contextualised by the needs of ecologists in planning/engineering. Following precedents from other research, this project establishes an ensemble for object detection, image segmentation and image classification models which are then tested using different image manipulation and class structuring techniques to encourage model generalisation. The research concludes, in the context of Scottish wildcat, that models trained on captivity imagery cannot be generalised to wild camera trap imagery using existing techniques. However, final model performances based on a two-class model Wildcat vs Not Wildcat achieved an overall accuracy score of 81.6% and Wildcat accuracy score of 54.8% on a test set in which only 1% of images contained a wildcat. This suggests using captivity images is feasible with further research. This is the first research which attempts to generate a training set based on captivity data and the first to explore the development of such models in the context of ecologists in planning/engineering.
NDD20: A large-scale few-shot dolphin dataset for coarse and fine-grained categorisation
May 27, 2020

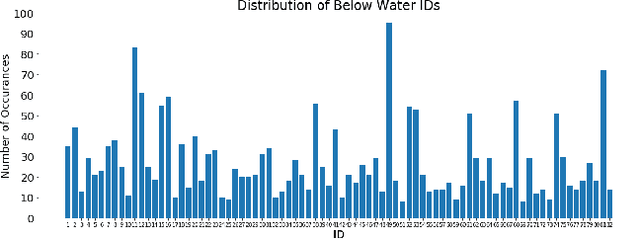

We introduce the Northumberland Dolphin Dataset 2020 (NDD20), a challenging image dataset annotated for both coarse and fine-grained instance segmentation and categorisation. This dataset, the first release of the NDD, was created in response to the rapid expansion of computer vision into conservation research and the production of field-deployable systems suited to extreme environmental conditions -- an area with few open source datasets. NDD20 contains a large collection of above and below water images of two different dolphin species for traditional coarse and fine-grained segmentation. All data contained in NDD20 was obtained via manual collection in the North Sea around the Northumberland coastline, UK. We present experimentation using standard deep learning network architecture trained using NDD20 and report baselines results.
The Northumberland Dolphin Dataset: A Multimedia Individual Cetacean Dataset for Fine-Grained Categorisation
Aug 07, 2019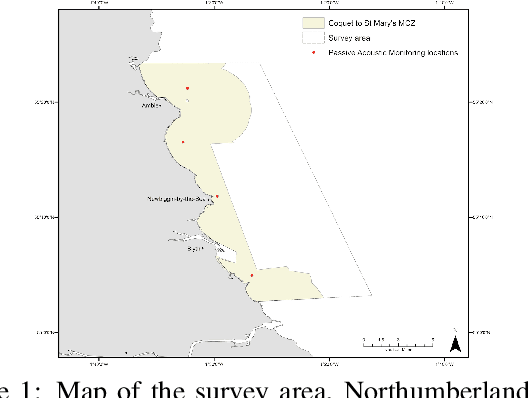
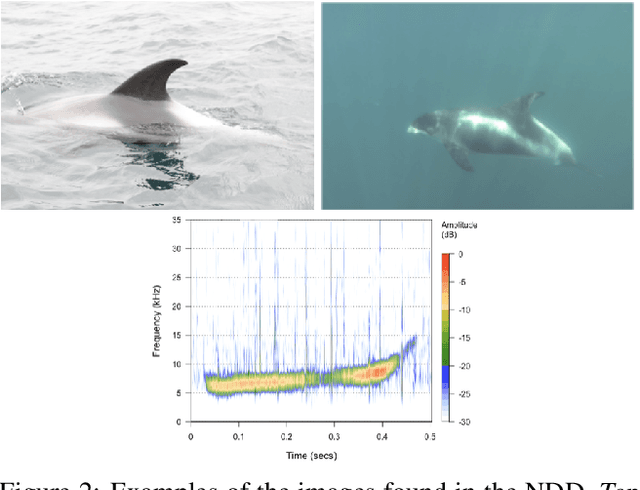


Methods for cetacean research include photo-identification (photo-id) and passive acoustic monitoring (PAM) which generate thousands of images per expedition that are currently hand categorised by researchers into the individual dolphins sighted. With the vast amount of data obtained it is crucially important to develop a system that is able to categorise this quickly. The Northumberland Dolphin Dataset (NDD) is an on-going novel dataset project made up of above and below water images of, and spectrograms of whistles from, white-beaked dolphins. These are produced by photo-id and PAM data collection methods applied off the coast of Northumberland, UK. This dataset will aid in building cetacean identification models, reducing the number of human-hours required to categorise images. Example use cases and areas identified for speed up are examined.