 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFashion Object Detection for Tops & Bottoms
May 29, 2023

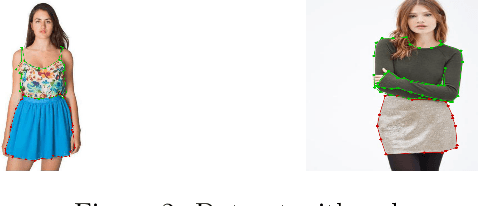
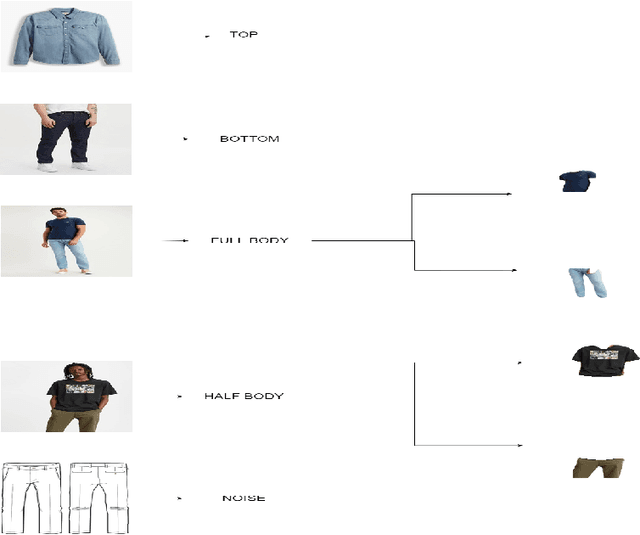
Fashion is one of the largest world's industries and computer vision techniques have been becoming more popular in recent years, in particular, for tasks such as object detection and apparel segmentation. Even with the rapid growth in computer vision solutions, specifically for the fashion industry, many problems are far for being resolved. Therefore, not at all times, adjusting out-of-the-box pre-trained computer vision models will provide the desired solution. In the present paper is proposed a pipeline that takes a noisy image with a person and specifically detects the regions with garments that are bottoms or tops. Our solution implements models that are capable of finding human parts in an image e.g. full-body vs half-body, or no human is found. Then, other models knowing that there's a human and its composition (e.g. not always we have a full-body) finds the bounding boxes/regions of the image that very likely correspond to a bottom or a top. For the creation of bounding boxes/regions task, a benchmark dataset was specifically prepared. The results show that the Mask RCNN solution is robust, and generalized enough to be used and scalable in unseen apparel/fashion data.
Human Body Shape Classification Based on a Single Image
May 29, 2023



There is high demand for online fashion recommender systems that incorporate the needs of the consumer's body shape. As such, we present a methodology to classify human body shape from a single image. This is achieved through the use of instance segmentation and keypoint estimation models, trained only on open-source benchmarking datasets. The system is capable of performing in noisy environments owing to to robust background subtraction. The proposed methodology does not require 3D body recreation as a result of classification based on estimated keypoints, nor requires historical information about a user to operate - calculating all required measurements at the point of use. We evaluate our methodology both qualitatively against existing body shape classifiers and quantitatively against a novel dataset of images, which we provide for use to the community. The resultant body shape classification can be utilised in a variety of downstream tasks, such as input to size and fit recommendation or virtual try-on systems.
Being the center of attention: A Person-Context CNN framework for Personality Recognition
Oct 15, 2019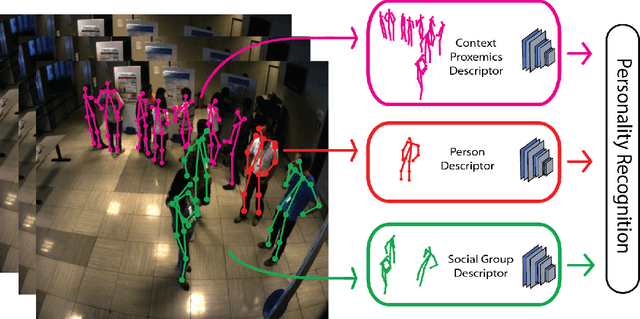
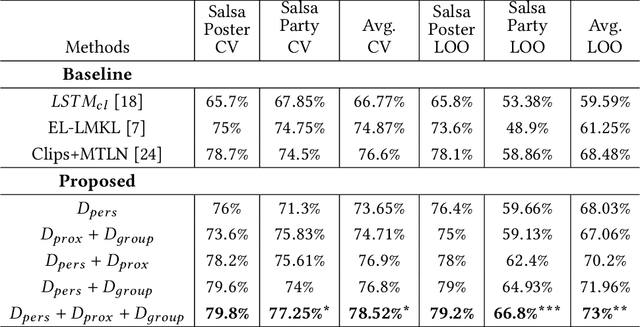
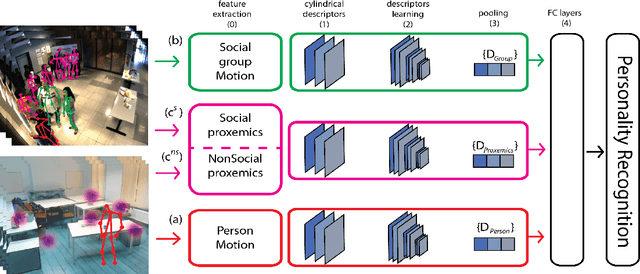
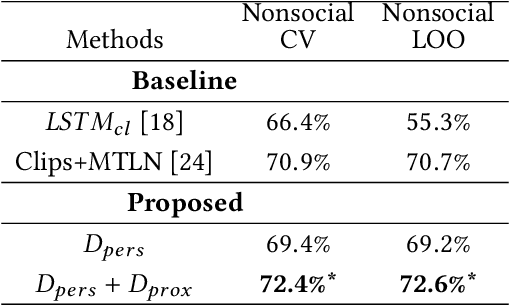
This paper proposes a novel study on personality recognition using video data from different scenarios. Our goal is to jointly model nonverbal behavioral cues with contextual information for a robust, multi-scenario, personality recognition system. Therefore, we build a novel multi-stream Convolutional Neural Network framework (CNN), which considers multiple sources of information. From a given scenario, we extract spatio-temporal motion descriptors from every individual in the scene, spatio-temporal motion descriptors encoding social group dynamics, and proxemics descriptors to encode the interaction with the surrounding context. All the proposed descriptors are mapped to the same feature space facilitating the overall learning effort. Experiments on two public datasets demonstrate the effectiveness of jointly modeling the mutual Person-Context information, outperforming the state-of-the art-results for personality recognition in two different scenarios. Lastly, we present CNN class activation maps for each personality trait, shedding light on behavioral patterns linked with personality attributes.