 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank over Class: The Untapped Potential of Ranking in Natural Language Processing
Paper and Code
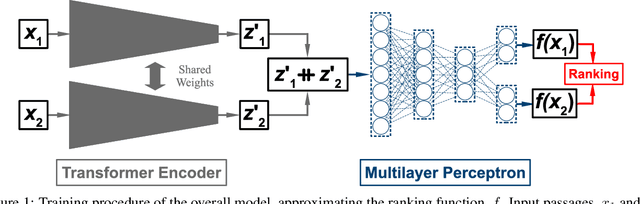
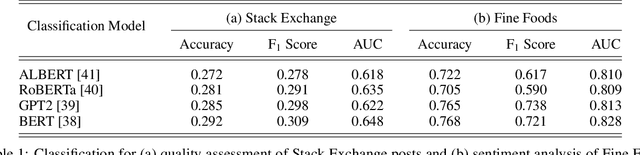
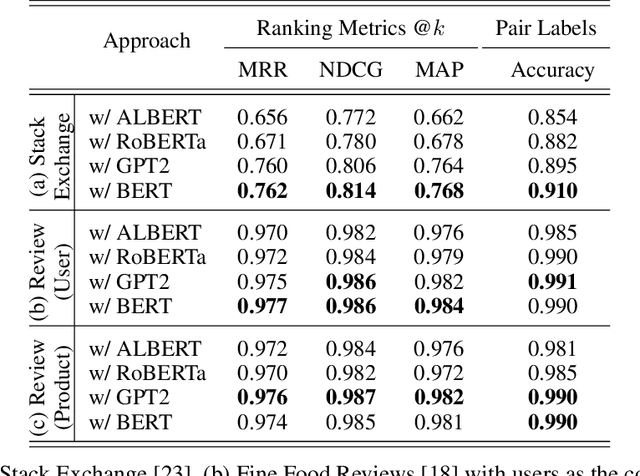
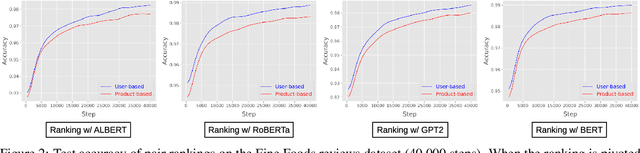
Text classification has long been a staple in natural language processing with applications spanning across sentiment analysis, online content tagging, recommender systems and spam detection. However, text classification, by nature, suffers from a variety of issues stemming from dataset imbalance, text ambiguity, subjectivity and the lack of linguistic context in the data. In this paper, we explore the use of text ranking, commonly used in information retrieval, to carry out challenging classification-based tasks. We propose a novel end-to-end ranking approach consisting of a Transformer network responsible for producing representations for a pair of text sequences, which are in turn passed into a context aggregating network outputting ranking scores used to determine an ordering to the sequences based on some notion of relevance. We perform numerous experiments on publicly-available datasets and investigate the possibility of applying our ranking approach to certain problems often addressed using classification. In an experiment on a heavily-skewed sentiment analysis dataset, converting ranking results to classification labels yields an approximately 22% improvement over state-of-the-art text classification, demonstrating the efficacy of text ranking over text classification in certain scenarios.