 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaSR: Context-Aware Speech Recognition via Latent Reasoning
May 30, 2026Recent advances in Speech Large Language Models (Speech LLMs) have significantly enhanced spoken language understanding and reasoning. However, their contextual awareness is limited, struggling to perform speech recognition that effectively reflects the speaker's intent and topical context. In this paper, we propose LaSR (Latent Speech Reasoning), a novel training paradigm featuring a context-aware reasoning trajectory that leverages the latent reasoning process. Instead of generating explicit intermediate tokens, LaSR aligns chain-of-thought (CoT) supervision around the acoustic feature region of the targeted word, and introduces latent reasoning periods for context information grounding and transcriptional transition. Furthermore, to effectively benchmark contextual recognition on specialized vocabulary, we propose Spoken Darwin-Science, a large-scale corpus focusing on academic terminologies. Preliminary experiments on Fun-Audio-Chat demonstrate that LaSR significantly improves terminology recognition without introducing additional latency and consistently outperforms standard supervised fine-tuning baselines. Our findings highlight the potential of latent reasoning in building efficient, context-aware speech assistants.
VocalNet-MDM: Accelerating Streaming Speech LLM via Self-Distilled Masked Diffusion Modeling
Feb 09, 2026Recent Speech Large Language Models~(LLMs) have achieved impressive capabilities in end-to-end speech interaction. However, the prevailing autoregressive paradigm imposes strict serial constraints, limiting generation efficiency and introducing exposure bias. In this paper, we investigate Masked Diffusion Modeling~(MDM) as a non-autoregressive paradigm for speech LLMs and introduce VocalNet-MDM. To adapt MDM for streaming speech interaction, we address two critical challenges: training-inference mismatch and iterative overhead. We propose Hierarchical Block-wise Masking to align training objectives with the progressive masked states encountered during block diffusion decoding, and Iterative Self-Distillation to compress multi-step refinement into fewer steps for low-latency inference. Trained on a limited scale of only 6K hours of speech data, VocalNet-MDM achieves a 3.7$\times$--10$\times$ decoding speedup and reduces first-chunk latency by 34\% compared to AR baselines. It maintains competitive recognition accuracy while achieving state-of-the-art text quality and speech naturalness, demonstrating that MDM is a promising and scalable alternative for low-latency, efficient speech LLMs.
MeetBench-XL: Calibrated Multi-Dimensional Evaluation and Learned Dual-Policy Agents for Real-Time Meetings
Feb 03, 2026Enterprise meeting environments require AI assistants that handle diverse operational tasks, from rapid fact checking during live discussions to cross meeting analysis for strategic planning, under strict latency, cost, and privacy constraints. Existing meeting benchmarks mainly focus on simplified question answering and fail to reflect real world enterprise workflows, where queries arise organically from multi stakeholder collaboration, span long temporal contexts, and require tool augmented reasoning. We address this gap through a grounded dataset and a learned agent framework. First, we introduce MeetAll, a bilingual and multimodal corpus derived from 231 enterprise meetings totaling 140 hours. Questions are injected using an enterprise informed protocol validated by domain expert review and human discriminability studies. Unlike purely synthetic benchmarks, this protocol is grounded in four enterprise critical dimensions: cognitive load, temporal context span, domain expertise, and actionable task execution, calibrated through interviews with stakeholders across finance, healthcare, and technology sectors. Second, we propose MeetBench XL, a multi dimensional evaluation protocol aligned with human judgment that measures factual fidelity, intent alignment, response efficiency, structural clarity, and completeness. Third, we present MeetMaster XL, a learned dual policy agent that jointly optimizes query routing between fast and slow reasoning paths and tool invocation, including retrieval, cross meeting aggregation, and web search. A lightweight classifier enables accurate routing with minimal overhead, achieving a superior quality latency tradeoff over single model baselines. Experiments against commercial systems show consistent gains, supported by ablations, robustness tests, and a real world deployment case study.Resources: https://github.com/huyuelin/MeetBench.
Lightweight High-Fidelity Low-Bitrate Talking Face Compression for 3D Video Conference
Jan 29, 2026The demand for immersive and interactive communication has driven advancements in 3D video conferencing, yet achieving high-fidelity 3D talking face representation at low bitrates remains a challenge. Traditional 2D video compression techniques fail to preserve fine-grained geometric and appearance details, while implicit neural rendering methods like NeRF suffer from prohibitive computational costs. To address these challenges, we propose a lightweight, high-fidelity, low-bitrate 3D talking face compression framework that integrates FLAME-based parametric modeling with 3DGS neural rendering. Our approach transmits only essential facial metadata in real time, enabling efficient reconstruction with a Gaussian-based head model. Additionally, we introduce a compact representation and compression scheme, including Gaussian attribute compression and MLP optimization, to enhance transmission efficiency. Experimental results demonstrate that our method achieves superior rate-distortion performance, delivering high-quality facial rendering at extremely low bitrates, making it well-suited for real-time 3D video conferencing applications.
VocalBench-zh: Decomposing and Benchmarking the Speech Conversational Abilities in Mandarin Context
Nov 17, 2025



The development of multi-modal large language models (LLMs) leads to intelligent approaches capable of speech interactions. As one of the most widely spoken languages globally, Mandarin is supported by most models to enhance their applicability and reach. However, the scarcity of comprehensive speech-to-speech (S2S) benchmarks in Mandarin contexts impedes systematic evaluation for developers and hinders fair model comparison for users. In this work, we propose VocalBench-zh, an ability-level divided evaluation suite adapted to Mandarin context consisting of 10 well-crafted subsets and over 10K high-quality instances, covering 12 user-oriented characters. The evaluation experiment on 14 mainstream models reveals the common challenges for current routes, and highlights the need for new insights into next-generation speech interactive systems. The evaluation codes and datasets will be available at https://github.com/SJTU-OmniAgent/VocalBench-zh.
VocalNet-M2: Advancing Low-Latency Spoken Language Modeling via Integrated Multi-Codebook Tokenization and Multi-Token Prediction
Nov 13, 2025Current end-to-end spoken language models (SLMs) have made notable progress, yet they still encounter considerable response latency. This delay primarily arises from the autoregressive generation of speech tokens and the reliance on complex flow-matching models for speech synthesis. To overcome this, we introduce VocalNet-M2, a novel low-latency SLM that integrates a multi-codebook tokenizer and a multi-token prediction (MTP) strategy. Our model directly generates multi-codebook speech tokens, thus eliminating the need for a latency-inducing flow-matching model. Furthermore, our MTP strategy enhances generation efficiency and improves overall performance. Extensive experiments demonstrate that VocalNet-M2 achieves a substantial reduction in first chunk latency (from approximately 725ms to 350ms) while maintaining competitive performance across mainstream SLMs. This work also provides a comprehensive comparison of single-codebook and multi-codebook strategies, offering valuable insights for developing efficient and high-performance SLMs for real-time interactive applications.
CS3-Bench: Evaluating and Enhancing Speech-to-Speech LLMs for Mandarin-English Code-Switching
Oct 09, 2025



The advancement of multimodal large language models has accelerated the development of speech-to-speech interaction systems. While natural monolingual interaction has been achieved, we find existing models exhibit deficiencies in language alignment. In our proposed Code-Switching Speech-to-Speech Benchmark (CS3-Bench), experiments on 7 mainstream models demonstrate a relative performance drop of up to 66% in knowledge-intensive question answering and varying degrees of misunderstanding in open-ended conversations. Starting from a model with severe performance deterioration, we propose both data constructions and training approaches to improve the language alignment capabilities, specifically employing Chain of Recognition (CoR) to enhance understanding and Keyword Highlighting (KH) to guide generation. Our approach improves the knowledge accuracy from 25.14% to 46.13%, with open-ended understanding rate from 64.5% to 86.5%, and significantly reduces pronunciation errors in the secondary language. CS3-Bench is available at https://huggingface.co/datasets/VocalNet/CS3-Bench.
VocalBench: Benchmarking the Vocal Conversational Abilities for Speech Interaction Models
May 21, 2025The rapid advancement of large language models (LLMs) has accelerated the development of multi-modal models capable of vocal communication. Unlike text-based interactions, speech conveys rich and diverse information, including semantic content, acoustic variations, paralanguage cues, and environmental context. However, existing evaluations of speech interaction models predominantly focus on the quality of their textual responses, often overlooking critical aspects of vocal performance and lacking benchmarks with vocal-specific test instances. To address this gap, we propose VocalBench, a comprehensive benchmark designed to evaluate speech interaction models' capabilities in vocal communication. VocalBench comprises 9,400 carefully curated instances across four key dimensions: semantic quality, acoustic performance, conversational abilities, and robustness. It covers 16 fundamental skills essential for effective vocal interaction. Experimental results reveal significant variability in current model capabilities, each exhibiting distinct strengths and weaknesses, and provide valuable insights to guide future research in speech-based interaction systems. Code and evaluation instances are available at https://github.com/SJTU-OmniAgent/VocalBench.
VocalNet: Speech LLM with Multi-Token Prediction for Faster and High-Quality Generation
Apr 05, 2025Speech large language models (LLMs) have emerged as a prominent research focus in speech processing. We propose VocalNet-1B and VocalNet-8B, a series of high-performance, low-latency speech LLMs enabled by a scalable and model-agnostic training framework for real-time voice interaction. Departing from the conventional next-token prediction (NTP), we introduce multi-token prediction (MTP), a novel approach optimized for speech LLMs that simultaneously improves generation speed and quality. Experiments show that VocalNet outperforms mainstream Omni LLMs despite using significantly less training data, while also surpassing existing open-source speech LLMs by a substantial margin. To support reproducibility and community advancement, we will open-source all model weights, inference code, training data, and framework implementations upon publication.
Linear Attention Modeling for Learned Image Compression
Feb 09, 2025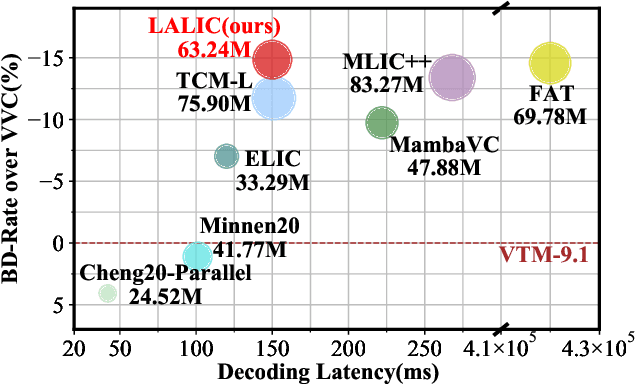



Recent years, learned image compression has made tremendous progress to achieve impressive coding efficiency. Its coding gain mainly comes from non-linear neural network-based transform and learnable entropy modeling. However, most of recent focuses have been solely on a strong backbone, and few studies consider the low-complexity design. In this paper, we propose LALIC, a linear attention modeling for learned image compression. Specially, we propose to use Bi-RWKV blocks, by utilizing the Spatial Mix and Channel Mix modules to achieve more compact features extraction, and apply the Conv based Omni-Shift module to adapt to two-dimensional latent representation. Furthermore, we propose a RWKV-based Spatial-Channel ConTeXt model (RWKV-SCCTX), that leverages the Bi-RWKV to modeling the correlation between neighboring features effectively, to further improve the RD performance. To our knowledge, our work is the first work to utilize efficient Bi-RWKV models with linear attention for learned image compression. Experimental results demonstrate that our method achieves competitive RD performances by outperforming VTM-9.1 by -14.84%, -15.20%, -17.32% in BD-rate on Kodak, Tecnick and CLIC Professional validation datasets.