 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Attention Modeling for Learned Image Compression
Feb 09, 2025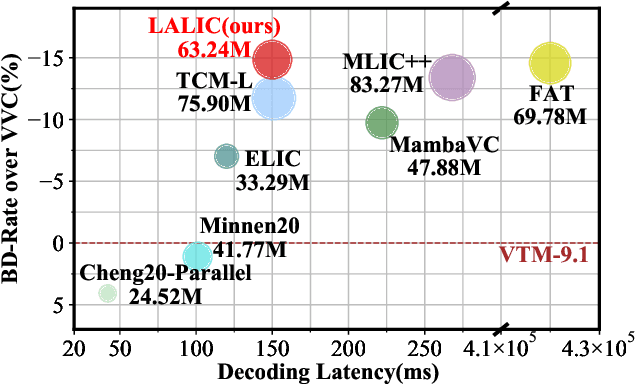



Recent years, learned image compression has made tremendous progress to achieve impressive coding efficiency. Its coding gain mainly comes from non-linear neural network-based transform and learnable entropy modeling. However, most of recent focuses have been solely on a strong backbone, and few studies consider the low-complexity design. In this paper, we propose LALIC, a linear attention modeling for learned image compression. Specially, we propose to use Bi-RWKV blocks, by utilizing the Spatial Mix and Channel Mix modules to achieve more compact features extraction, and apply the Conv based Omni-Shift module to adapt to two-dimensional latent representation. Furthermore, we propose a RWKV-based Spatial-Channel ConTeXt model (RWKV-SCCTX), that leverages the Bi-RWKV to modeling the correlation between neighboring features effectively, to further improve the RD performance. To our knowledge, our work is the first work to utilize efficient Bi-RWKV models with linear attention for learned image compression. Experimental results demonstrate that our method achieves competitive RD performances by outperforming VTM-9.1 by -14.84%, -15.20%, -17.32% in BD-rate on Kodak, Tecnick and CLIC Professional validation datasets.
AsymLLIC: Asymmetric Lightweight Learned Image Compression
Dec 23, 2024



Learned image compression (LIC) methods often employ symmetrical encoder and decoder architectures, evitably increasing decoding time. However, practical scenarios demand an asymmetric design, where the decoder requires low complexity to cater to diverse low-end devices, while the encoder can accommodate higher complexity to improve coding performance. In this paper, we propose an asymmetric lightweight learned image compression (AsymLLIC) architecture with a novel training scheme, enabling the gradual substitution of complex decoding modules with simpler ones. Building upon this approach, we conduct a comprehensive comparison of different decoder network structures to strike a better trade-off between complexity and compression performance. Experiment results validate the efficiency of our proposed method, which not only achieves comparable performance to VVC but also offers a lightweight decoder with only 51.47 GMACs computation and 19.65M parameters. Furthermore, this design methodology can be easily applied to any LIC models, enabling the practical deployment of LIC techniques.
CMC-Bench: Towards a New Paradigm of Visual Signal Compression
Jun 13, 2024



Ultra-low bitrate image compression is a challenging and demanding topic. With the development of Large Multimodal Models (LMMs), a Cross Modality Compression (CMC) paradigm of Image-Text-Image has emerged. Compared with traditional codecs, this semantic-level compression can reduce image data size to 0.1\% or even lower, which has strong potential applications. However, CMC has certain defects in consistency with the original image and perceptual quality. To address this problem, we introduce CMC-Bench, a benchmark of the cooperative performance of Image-to-Text (I2T) and Text-to-Image (T2I) models for image compression. This benchmark covers 18,000 and 40,000 images respectively to verify 6 mainstream I2T and 12 T2I models, including 160,000 subjective preference scores annotated by human experts. At ultra-low bitrates, this paper proves that the combination of some I2T and T2I models has surpassed the most advanced visual signal codecs; meanwhile, it highlights where LMMs can be further optimized toward the compression task. We encourage LMM developers to participate in this test to promote the evolution of visual signal codec protocols.
MISC: Ultra-low Bitrate Image Semantic Compression Driven by Large Multimodal Model
Feb 29, 2024



With the evolution of storage and communication protocols, ultra-low bitrate image compression has become a highly demanding topic. However, existing compression algorithms must sacrifice either consistency with the ground truth or perceptual quality at ultra-low bitrate. In recent years, the rapid development of the Large Multimodal Model (LMM) has made it possible to balance these two goals. To solve this problem, this paper proposes a method called Multimodal Image Semantic Compression (MISC), which consists of an LMM encoder for extracting the semantic information of the image, a map encoder to locate the region corresponding to the semantic, an image encoder generates an extremely compressed bitstream, and a decoder reconstructs the image based on the above information. Experimental results show that our proposed MISC is suitable for compressing both traditional Natural Sense Images (NSIs) and emerging AI-Generated Images (AIGIs) content. It can achieve optimal consistency and perception results while saving 50% bitrate, which has strong potential applications in the next generation of storage and communication. The code will be released on https://github.com/lcysyzxdxc/MISC.
Complexity-Oriented Per-shot Video Coding Optimization
Dec 23, 2021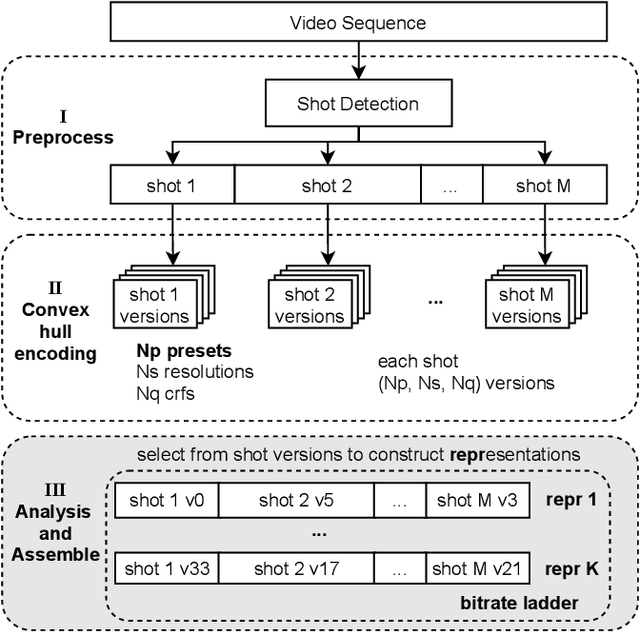

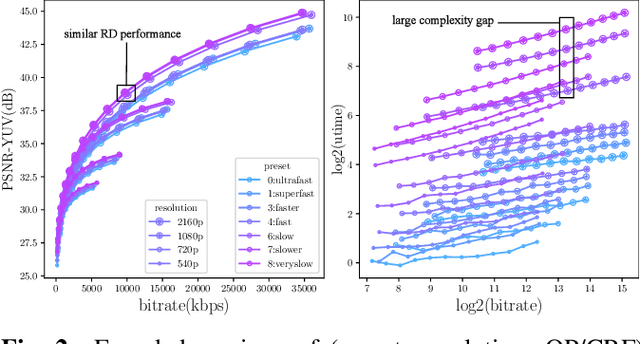

Current per-shot encoding schemes aim to improve the compression efficiency by shot-level optimization. It splits a source video sequence into shots and imposes optimal sets of encoding parameters to each shot. Per-shot encoding achieved approximately 20% bitrate savings over baseline fixed QP encoding at the expense of pre-processing complexity. However, the adjustable parameter space of the current per-shot encoding schemes only has spatial resolution and QP/CRF, resulting in a lack of encoding flexibility. In this paper, we extend the per-shot encoding framework in the complexity dimension. We believe that per-shot encoding with flexible complexity will help in deploying user-generated content. We propose a rate-distortion-complexity optimization process for encoders and a methodology to determine the coding parameters under the constraints of complexities and bitrate ladders. Experimental results show that our proposed method achieves complexity constraints ranging from 100% to 3% in a dense form compared to the slowest per-shot anchor. With similar complexities of the per-shot scheme fixed in specific presets, our proposed method achieves BDrate gain up to -19.17%.