 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeking SOTA: Time-Series Forecasting Must Adopt Taxonomy-Specific Evaluation to Dispel Illusory Gains
Mar 16, 2026We argue that the current practice of evaluating AI/ML time-series forecasting models, predominantly on benchmarks characterized by strong, persistent periodicities and seasonalities, obscures real progress by overlooking the performance of efficient classical methods. We demonstrate that these "standard" datasets often exhibit dominant autocorrelation patterns and seasonal cycles that can be effectively captured by simpler linear or statistical models, rendering complex deep learning architectures frequently no more performant than their classical counterparts for these specific data characteristics, and raising questions as to whether any marginal improvements justify the significant increase in computational overhead and model complexity. We call on the community to (I) retire or substantially augment current benchmarks with datasets exhibiting a wider spectrum of non-stationarities, such as structural breaks, time-varying volatility, and concept drift, and less predictable dynamics drawn from diverse real-world domains, and (II) require every deep learning submission to include robust classical and simple baselines, appropriately chosen for the specific characteristics of the downstream tasks' time series. By doing so, we will help ensure that reported gains reflect genuine scientific methodological advances rather than artifacts of benchmark selection favoring models adept at learning repetitive patterns.
An Approximate Ascent Approach To Prove Convergence of PPO
Feb 03, 2026Proximal Policy Optimization (PPO) is among the most widely used deep reinforcement learning algorithms, yet its theoretical foundations remain incomplete. Most importantly, convergence and understanding of fundamental PPO advantages remain widely open. Under standard theory assumptions we show how PPO's policy update scheme (performing multiple epochs of minibatch updates on multi-use rollouts with a surrogate gradient) can be interpreted as approximated policy gradient ascent. We show how to control the bias accumulated by the surrogate gradients and use techniques from random reshuffling to prove a convergence theorem for PPO that sheds light on PPO's success. Additionally, we identify a previously overlooked issue in truncated Generalized Advantage Estimation commonly used in PPO. The geometric weighting scheme induces infinite mass collapse onto the longest $k$-step advantage estimator at episode boundaries. Empirical evaluations show that a simple weight correction can yield substantial improvements in environments with strong terminal signal, such as Lunar Lander.
Local and Global Trend Bayesian Exponential Smoothing Models
Sep 25, 2023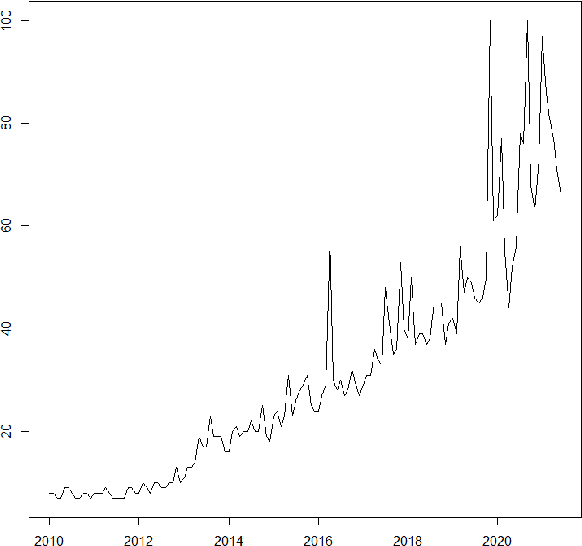


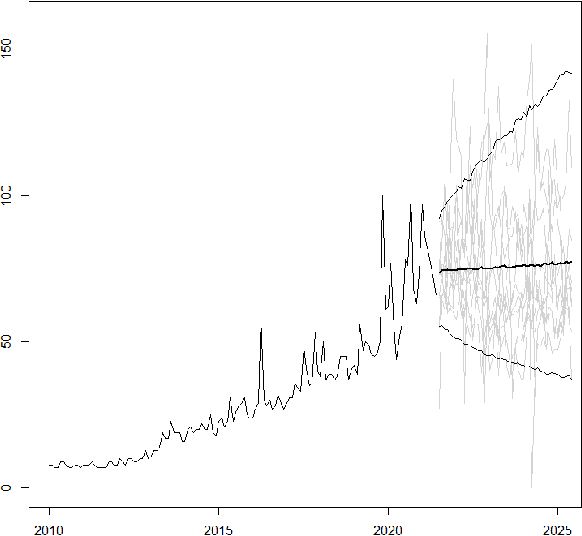
This paper describes a family of seasonal and non-seasonal time series models that can be viewed as generalisations of additive and multiplicative exponential smoothing models. Their development is motivated by fast-growing, volatile time series, and facilitated by state-of-the-art Bayesian fitting techniques. When applied to the M3 competition data set, they outperform the best algorithms in the competition as well as other benchmarks, thus achieving to the best of our knowledge the best results of univariate methods on this dataset in the literature.
Brain Model State Space Reconstruction Using an LSTM Neural Network
Jan 20, 2023Objective Kalman filtering has previously been applied to track neural model states and parameters, particularly at the scale relevant to EEG. However, this approach lacks a reliable method to determine the initial filter conditions and assumes that the distribution of states remains Gaussian. This study presents an alternative, data-driven method to track the states and parameters of neural mass models (NMMs) from EEG recordings using deep learning techniques, specifically an LSTM neural network. Approach An LSTM filter was trained on simulated EEG data generated by a neural mass model using a wide range of parameters. With an appropriately customised loss function, the LSTM filter can learn the behaviour of NMMs. As a result, it can output the state vector and parameters of NMMs given observation data as the input. Main Results Test results using simulated data yielded correlations with R squared of around 0.99 and verified that the method is robust to noise and can be more accurate than a nonlinear Kalman filter when the initial conditions of the Kalman filter are not accurate. As an example of real-world application, the LSTM filter was also applied to real EEG data that included epileptic seizures, and revealed changes in connectivity strength parameters at the beginnings of seizures. Significance Tracking the state vector and parameters of mathematical brain models is of great importance in the area of brain modelling, monitoring, imaging and control. This approach has no need to specify the initial state vector and parameters, which is very difficult to do in practice because many of the variables being estimated cannot be measured directly in physiological experiments. This method may be applied using any neural mass model and, therefore, provides a general, novel, efficient approach to estimate brain model variables that are often difficult to measure.
SETAR-Tree: A Novel and Accurate Tree Algorithm for Global Time Series Forecasting
Nov 16, 2022Threshold Autoregressive (TAR) models have been widely used by statisticians for non-linear time series forecasting during the past few decades, due to their simplicity and mathematical properties. On the other hand, in the forecasting community, general-purpose tree-based regression algorithms (forests, gradient-boosting) have become popular recently due to their ease of use and accuracy. In this paper, we explore the close connections between TAR models and regression trees. These enable us to use the rich methodology from the literature on TAR models to define a hierarchical TAR model as a regression tree that trains globally across series, which we call SETAR-Tree. In contrast to the general-purpose tree-based models that do not primarily focus on forecasting, and calculate averages at the leaf nodes, we introduce a new forecasting-specific tree algorithm that trains global Pooled Regression (PR) models in the leaves allowing the models to learn cross-series information and also uses some time-series-specific splitting and stopping procedures. The depth of the tree is controlled by conducting a statistical linearity test commonly employed in TAR models, as well as measuring the error reduction percentage at each node split. Thus, the proposed tree model requires minimal external hyperparameter tuning and provides competitive results under its default configuration. We also use this tree algorithm to develop a forest where the forecasts provided by a collection of diverse SETAR-Trees are combined during the forecasting process. In our evaluation on eight publicly available datasets, the proposed tree and forest models are able to achieve significantly higher accuracy than a set of state-of-the-art tree-based algorithms and forecasting benchmarks across four evaluation metrics.
A Bayesian-inspired, deep learning, semi-supervised domain adaptation technique for land cover mapping
May 25, 2020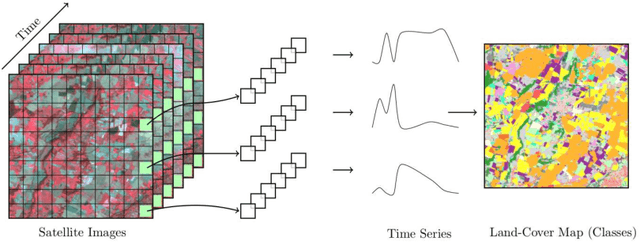
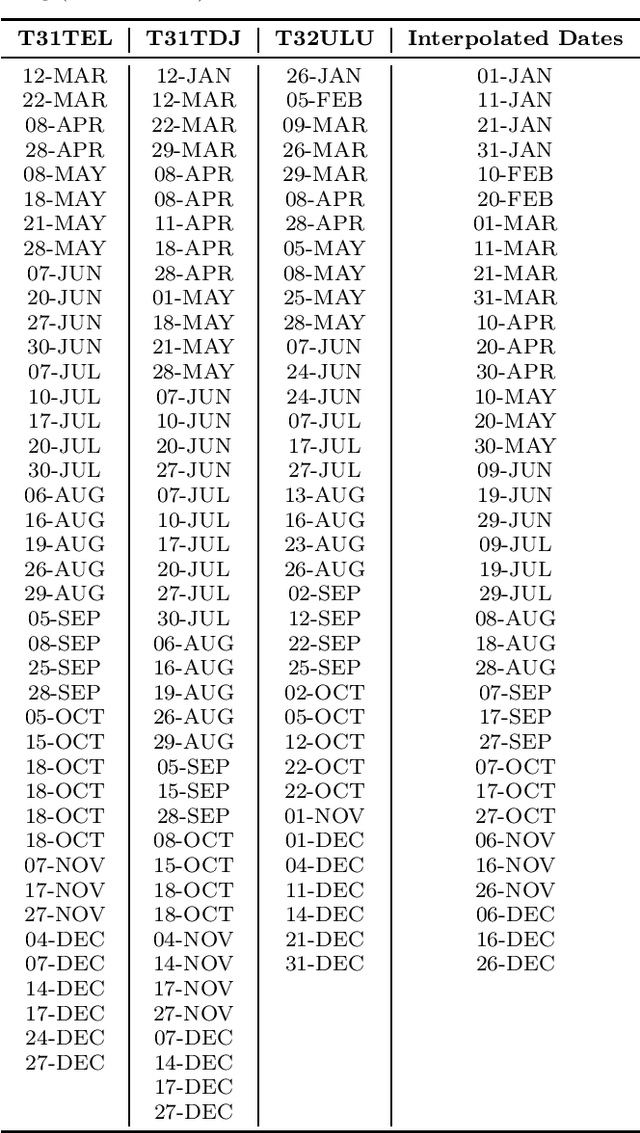
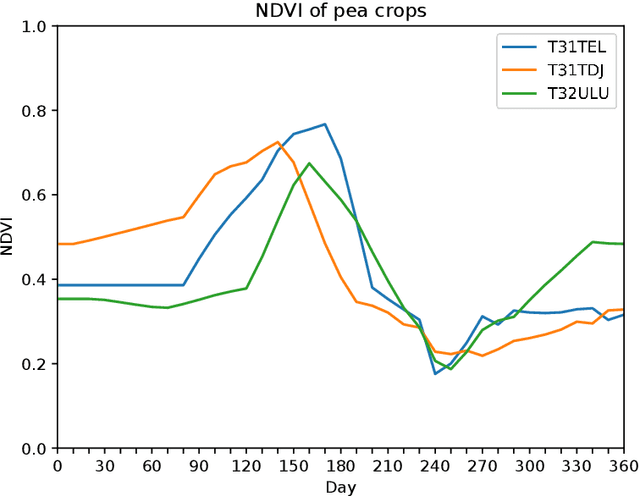
Land cover maps are a vital input variable to many types of environmental research and management. While they can be produced automatically by machine learning techniques, these techniques require substantial training data to achieve high levels of accuracy, which are not always available. One technique researchers use when labelled training data are scarce is domain adaptation (DA) -- where data from an alternate region, known as the source domain, are used to train a classifier and this model is adapted to map the study region, or target domain. The scenario we address in this paper is known as semi-supervised DA, where some labelled samples are available in the target domain. In this paper we present Sourcerer, a Bayesian-inspired, deep learning-based, semi-supervised DA technique for producing land cover maps from SITS data. The technique takes a convolutional neural network trained on a source domain and then trains further on the available target domain with a novel regularizer applied to the model weights. The regularizer adjusts the degree to which the model is modified to fit the target data, limiting the degree of change when the target data are few in number and increasing it as target data quantity increases. Our experiments on Sentinel-2 time series images compare Sourcerer with two state-of-the-art semi-supervised domain adaptation techniques and four baseline models. We show that on two different source-target domain pairings Sourcerer outperforms all other methods for any quantity of labelled target data available. In fact, the results on the more difficult target domain show that the starting accuracy of Sourcerer (when no labelled target data are available), 74.2%, is greater than the next-best state-of-the-art method trained on 20,000 labelled target instances.
Understanding Knowledge Gaps in Visual Question Answering: Implications for Gap Identification and Testing
Apr 08, 2020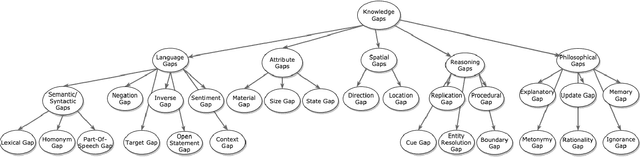
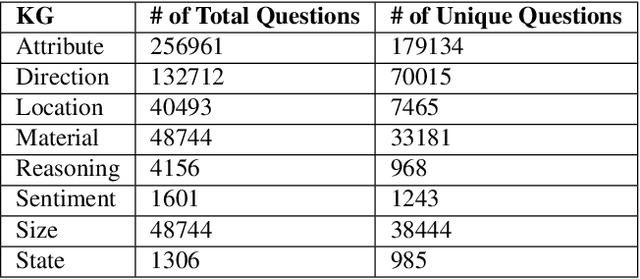

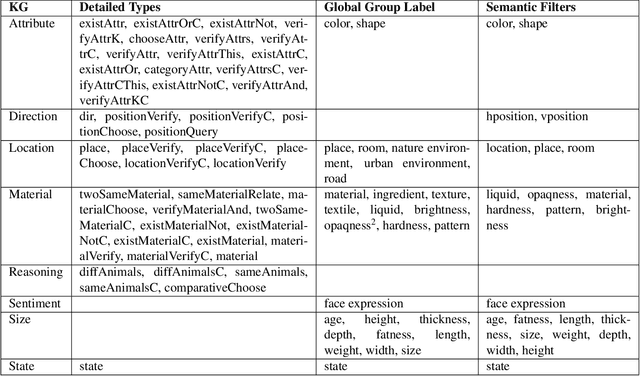
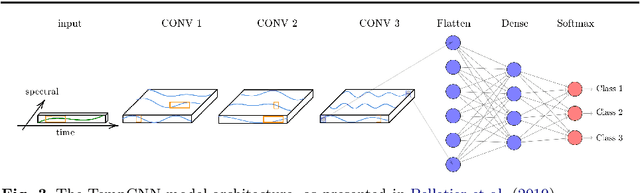
Visual Question Answering (VQA) systems are tasked with answering natural language questions corresponding to a presented image. Current VQA datasets typically contain questions related to the spatial information of objects, object attributes, or general scene questions. Recently, researchers have recognized the need for improving the balance of such datasets to reduce the system's dependency on memorized linguistic features and statistical biases and to allow for improved visual understanding. However, it is unclear as to whether there are any latent patterns that can be used to quantify and explain these failures. To better quantify our understanding of the performance of VQA models, we use a taxonomy of Knowledge Gaps (KGs) to identify/tag questions with one or more types of KGs. Each KG describes the reasoning abilities needed to arrive at a resolution, and failure to resolve gaps indicate an absence of the required reasoning ability. After identifying KGs for each question, we examine the skew in the distribution of the number of questions for each KG. In order to reduce the skew in the distribution of questions across KGs, we introduce a targeted question generation model. This model allows us to generate new types of questions for an image.