 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavioral Generative Agents for Energy Operations
Jun 14, 2025Accurately modeling consumer behavior in energy operations remains challenging due to inherent uncertainties, behavioral complexities, and limited empirical data. This paper introduces a novel approach leveraging generative agents--artificial agents powered by large language models--to realistically simulate customer decision-making in dynamic energy operations. We demonstrate that these agents behave more optimally and rationally in simpler market scenarios, while their performance becomes more variable and suboptimal as task complexity rises. Furthermore, the agents exhibit heterogeneous customer preferences, consistently maintaining distinct, persona-driven reasoning patterns. Our findings highlight the potential value of integrating generative agents into energy management simulations to improve the design and effectiveness of energy policies and incentive programs.
Non-Stationary Contextual Bandit Learning via Neural Predictive Ensemble Sampling
Oct 14, 2023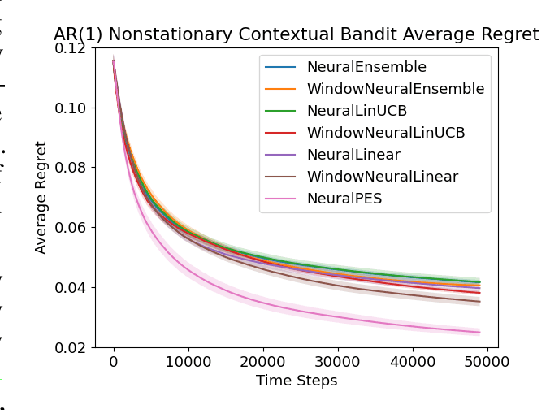
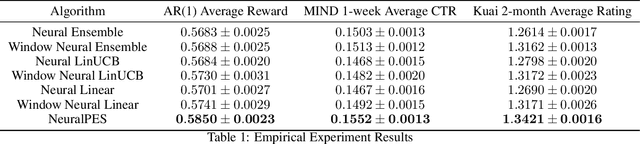


Real-world applications of contextual bandits often exhibit non-stationarity due to seasonality, serendipity, and evolving social trends. While a number of non-stationary contextual bandit learning algorithms have been proposed in the literature, they excessively explore due to a lack of prioritization for information of enduring value, or are designed in ways that do not scale in modern applications with high-dimensional user-specific features and large action set, or both. In this paper, we introduce a novel non-stationary contextual bandit algorithm that addresses these concerns. It combines a scalable, deep-neural-network-based architecture with a carefully designed exploration mechanism that strategically prioritizes collecting information with the most lasting value in a non-stationary environment. Through empirical evaluations on two real-world recommendation datasets, which exhibit pronounced non-stationarity, we demonstrate that our approach significantly outperforms the state-of-the-art baselines.