 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVaccinating Federated Learning for Robust Modulation Classification in Distributed Wireless Networks
Oct 16, 2024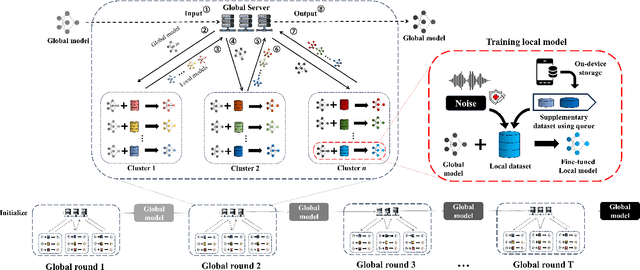
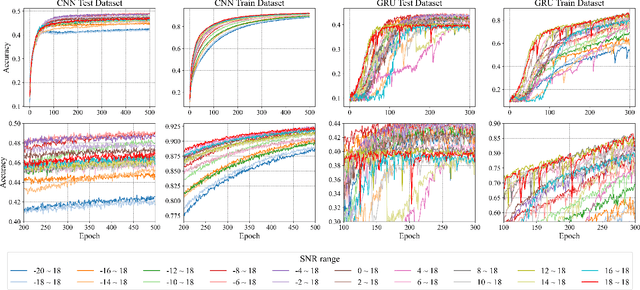
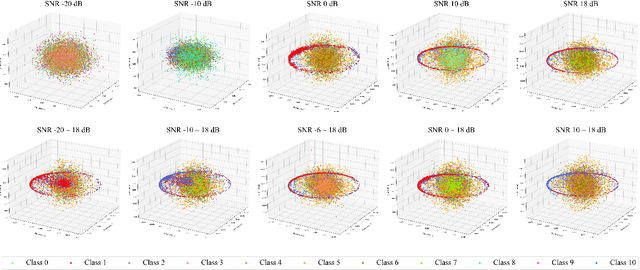
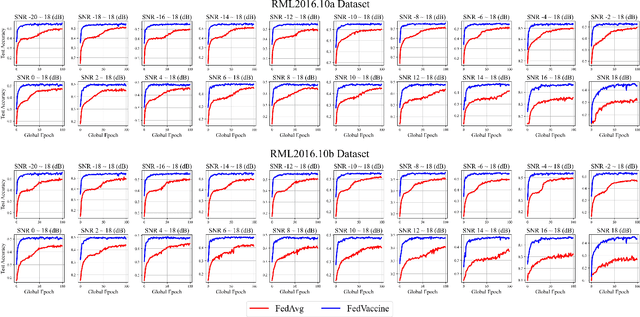
Automatic modulation classification (AMC) serves a vital role in ensuring efficient and reliable communication services within distributed wireless networks. Recent developments have seen a surge in interest in deep neural network (DNN)-based AMC models, with Federated Learning (FL) emerging as a promising framework. Despite these advancements, the presence of various noises within the signal exerts significant challenges while optimizing models to capture salient features. Furthermore, existing FL-based AMC models commonly rely on linear aggregation strategies, which face notable difficulties in integrating locally fine-tuned parameters within practical non-IID (Independent and Identically Distributed) environments, thereby hindering optimal learning convergence. To address these challenges, we propose FedVaccine, a novel FL model aimed at improving generalizability across signals with varying noise levels by deliberately introducing a balanced level of noise. This is accomplished through our proposed harmonic noise resilience approach, which identifies an optimal noise tolerance for DNN models, thereby regulating the training process and mitigating overfitting. Additionally, FedVaccine overcomes the limitations of existing FL-based AMC models' linear aggregation by employing a split-learning strategy using structural clustering topology and local queue data structure, enabling adaptive and cumulative updates to local models. Our experimental results, including IID and non-IID datasets as well as ablation studies, confirm FedVaccine's robust performance and superiority over existing FL-based AMC approaches across different noise levels. These findings highlight FedVaccine's potential to enhance the reliability and performance of AMC systems in practical wireless network environments.
HM-Conformer: A Conformer-based audio deepfake detection system with hierarchical pooling and multi-level classification token aggregation methods
Sep 15, 2023



Audio deepfake detection (ADD) is the task of detecting spoofing attacks generated by text-to-speech or voice conversion systems. Spoofing evidence, which helps to distinguish between spoofed and bona-fide utterances, might exist either locally or globally in the input features. To capture these, the Conformer, which consists of Transformers and CNN, possesses a suitable structure. However, since the Conformer was designed for sequence-to-sequence tasks, its direct application to ADD tasks may be sub-optimal. To tackle this limitation, we propose HM-Conformer by adopting two components: (1) Hierarchical pooling method progressively reducing the sequence length to eliminate duplicated information (2) Multi-level classification token aggregation method utilizing classification tokens to gather information from different blocks. Owing to these components, HM-Conformer can efficiently detect spoofing evidence by processing various sequence lengths and aggregating them. In experimental results on the ASVspoof 2021 Deepfake dataset, HM-Conformer achieved a 15.71% EER, showing competitive performance compared to recent systems.
PAS: Partial Additive Speech Data Augmentation Method for Noise Robust Speaker Verification
Jul 20, 2023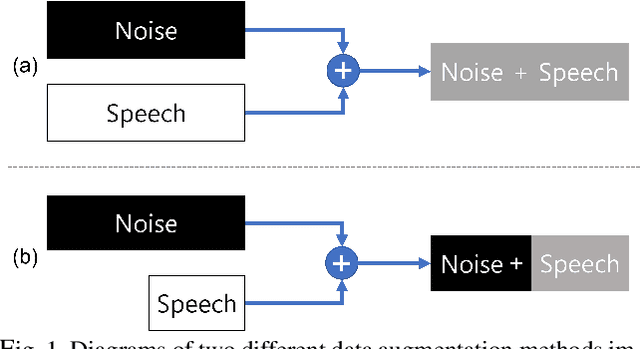
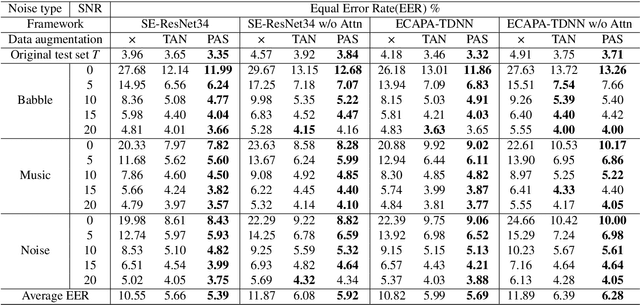
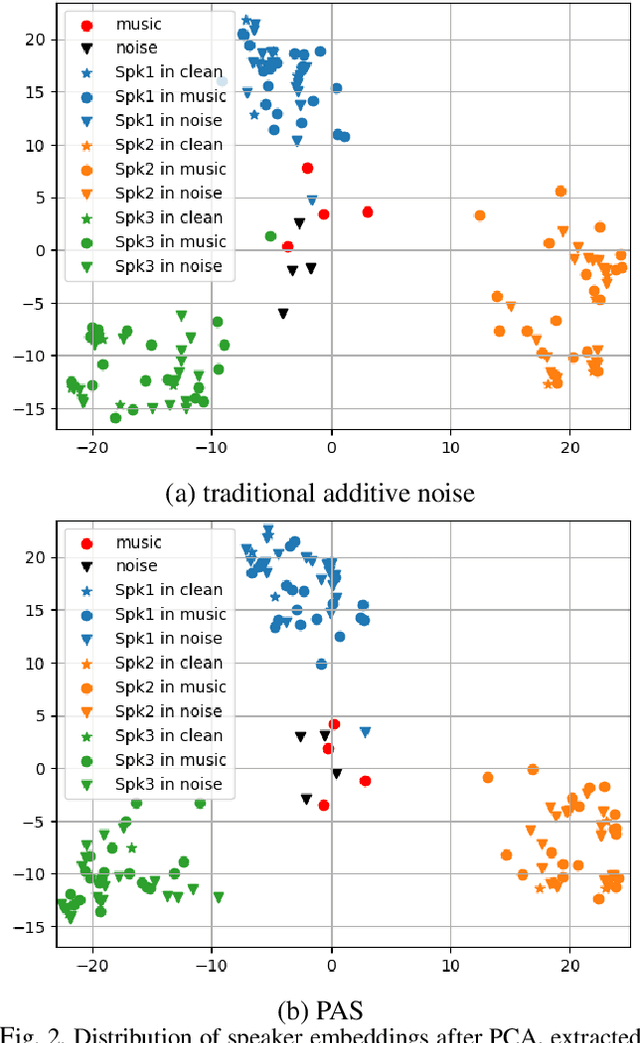
Background noise reduces speech intelligibility and quality, making speaker verification (SV) in noisy environments a challenging task. To improve the noise robustness of SV systems, additive noise data augmentation method has been commonly used. In this paper, we propose a new additive noise method, partial additive speech (PAS), which aims to train SV systems to be less affected by noisy environments. The experimental results demonstrate that PAS outperforms traditional additive noise in terms of equal error rates (EER), with relative improvements of 4.64% and 5.01% observed in SE-ResNet34 and ECAPA-TDNN. We also show the effectiveness of proposed method by analyzing attention modules and visualizing speaker embeddings.