Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAS: Partial Additive Speech Data Augmentation Method for Noise Robust Speaker Verification
Paper and Code
Jul 20, 2023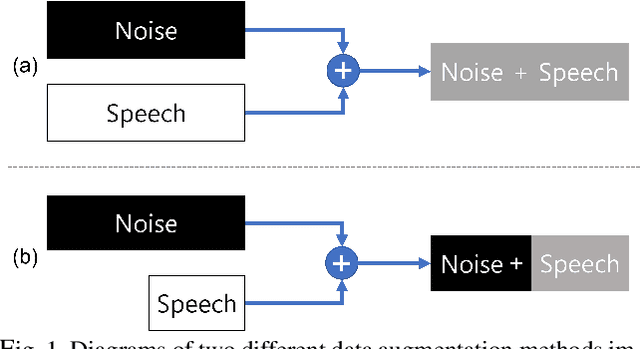
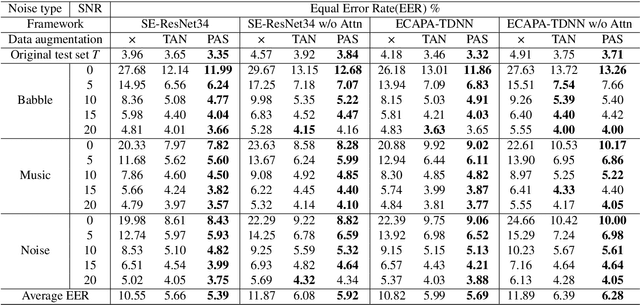
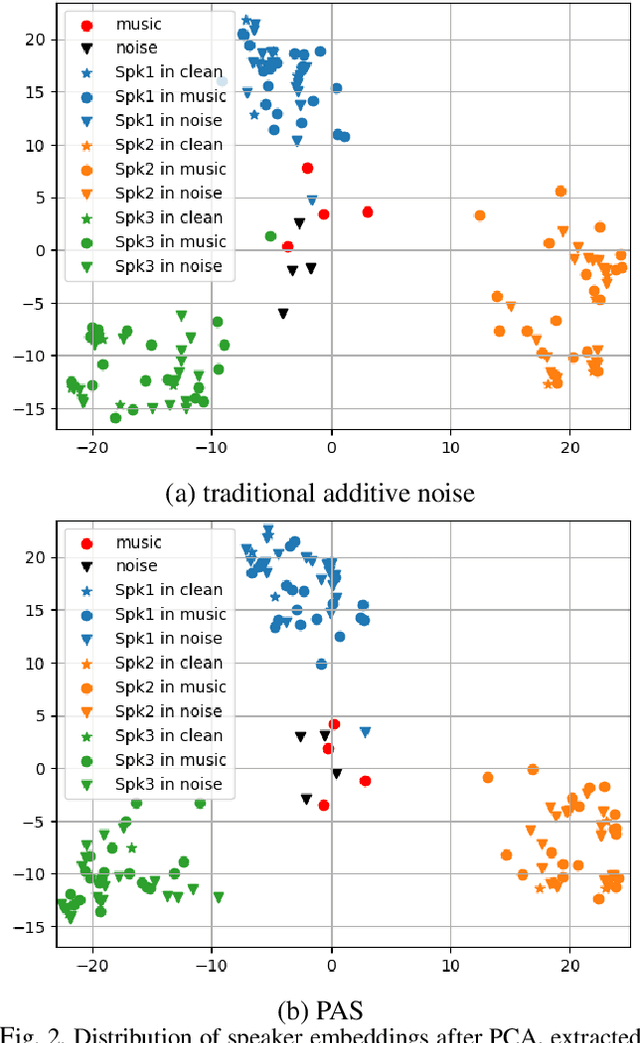
Background noise reduces speech intelligibility and quality, making speaker verification (SV) in noisy environments a challenging task. To improve the noise robustness of SV systems, additive noise data augmentation method has been commonly used. In this paper, we propose a new additive noise method, partial additive speech (PAS), which aims to train SV systems to be less affected by noisy environments. The experimental results demonstrate that PAS outperforms traditional additive noise in terms of equal error rates (EER), with relative improvements of 4.64% and 5.01% observed in SE-ResNet34 and ECAPA-TDNN. We also show the effectiveness of proposed method by analyzing attention modules and visualizing speaker embeddings.
* 5 pages, 2 figures, 1 table, accepted to CKAIA2023 as a conference
paper
View paper on