 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriage knowledge distillation for speaker verification
Jan 21, 2026Deploying speaker verification on resource-constrained devices remains challenging due to the computational cost of high-capacity models; knowledge distillation (KD) offers a remedy. Classical KD entangles target confidence with non-target structure in a Kullback-Leibler term, limiting the transfer of relational information. Decoupled KD separates these signals into target and non-target terms, yet treats non-targets uniformly and remains vulnerable to the long tail of low-probability classes in large-class settings. We introduce Triage KD (TRKD), a distillation scheme that operationalizes assess-prioritize-focus. TRKD introduces a cumulative-probability cutoff $τ$ to assess per-example difficulty and partition the teacher posterior into three groups: the target class, a high-probability non-target confusion-set, and a background-set. To prioritize informative signals, TRKD distills the confusion-set conditional distribution and discards the background. Concurrently, it transfers a three-mass (target/confusion/background) that capture sample difficulty and inter-class confusion. Finally, TRKD focuses learning via a curriculum on $τ$: training begins with a larger $τ$ to convey broad non-target context, then $τ$ is progressively decreased to shrink the confusion-set, concentrating supervision on the most confusable classes. In extensive experiments on VoxCeleb1 with both homogeneous and heterogeneous teacher-student pairs, TRKD was consistently superior to recent KD variants and attained the lowest EER across all protocols.
DAME: Duration-Aware Matryoshka Embedding for Duration-Robust Speaker Verification
Jan 20, 2026Short-utterance speaker verification remains challenging due to limited speaker-discriminative cues in short speech segments. While existing methods focus on enhancing speaker encoders, the embedding learning strategy still forces a single fixed-dimensional representation reused for utterances of any length, leaving capacity misaligned with the information available at different durations. We propose Duration-Aware Matryoshka Embedding (DAME), a model-agnostic framework that builds a nested hierarchy of sub-embeddings aligned to utterance durations: lower-dimensional representations capture compact speaker traits from short utterances, while higher dimensions encode richer details from longer speech. DAME supports both training from scratch and fine-tuning, and serves as a direct alternative to conventional large-margin fine-tuning, consistently improving performance across durations. On the VoxCeleb1-O/E/H and VOiCES evaluation sets, DAME consistently reduces the equal error rate on 1-s and other short-duration trials, while maintaining full-length performance with no additional inference cost. These gains generalize across various speaker encoder architectures under both general training and fine-tuning setups.
MR-RawNet: Speaker verification system with multiple temporal resolutions for variable duration utterances using raw waveforms
Jun 11, 2024

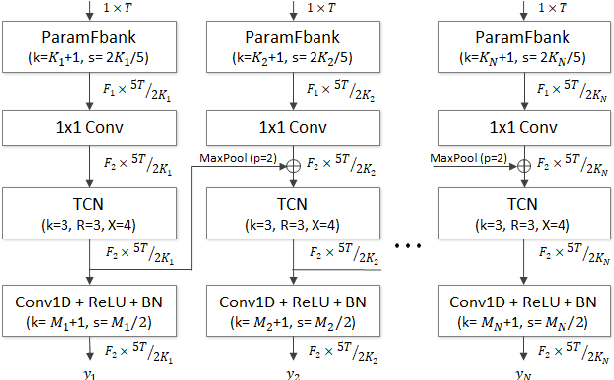

In speaker verification systems, the utilization of short utterances presents a persistent challenge, leading to performance degradation primarily due to insufficient phonetic information to characterize the speakers. To overcome this obstacle, we propose a novel structure, MR-RawNet, designed to enhance the robustness of speaker verification systems against variable duration utterances using raw waveforms. The MR-RawNet extracts time-frequency representations from raw waveforms via a multi-resolution feature extractor that optimally adjusts both temporal and spectral resolutions simultaneously. Furthermore, we apply a multi-resolution attention block that focuses on diverse and extensive temporal contexts, ensuring robustness against changes in utterance length. The experimental results, conducted on VoxCeleb1 dataset, demonstrate that the MR-RawNet exhibits superior performance in handling utterances of variable duration compared to other raw waveform-based systems.
HM-Conformer: A Conformer-based audio deepfake detection system with hierarchical pooling and multi-level classification token aggregation methods
Sep 15, 2023



Audio deepfake detection (ADD) is the task of detecting spoofing attacks generated by text-to-speech or voice conversion systems. Spoofing evidence, which helps to distinguish between spoofed and bona-fide utterances, might exist either locally or globally in the input features. To capture these, the Conformer, which consists of Transformers and CNN, possesses a suitable structure. However, since the Conformer was designed for sequence-to-sequence tasks, its direct application to ADD tasks may be sub-optimal. To tackle this limitation, we propose HM-Conformer by adopting two components: (1) Hierarchical pooling method progressively reducing the sequence length to eliminate duplicated information (2) Multi-level classification token aggregation method utilizing classification tokens to gather information from different blocks. Owing to these components, HM-Conformer can efficiently detect spoofing evidence by processing various sequence lengths and aggregating them. In experimental results on the ASVspoof 2021 Deepfake dataset, HM-Conformer achieved a 15.71% EER, showing competitive performance compared to recent systems.
Diff-SV: A Unified Hierarchical Framework for Noise-Robust Speaker Verification Using Score-Based Diffusion Probabilistic Models
Sep 14, 2023



Background noise considerably reduces the accuracy and reliability of speaker verification (SV) systems. These challenges can be addressed using a speech enhancement system as a front-end module. Recently, diffusion probabilistic models (DPMs) have exhibited remarkable noise-compensation capabilities in the speech enhancement domain. Building on this success, we propose Diff-SV, a noise-robust SV framework that leverages DPM. Diff-SV unifies a DPM-based speech enhancement system with a speaker embedding extractor, and yields a discriminative and noise-tolerable speaker representation through a hierarchical structure. The proposed model was evaluated under both in-domain and out-of-domain noisy conditions using the VoxCeleb1 test set, an external noise source, and the VOiCES corpus. The obtained experimental results demonstrate that Diff-SV achieves state-of-the-art performance, outperforming recently proposed noise-robust SV systems.
PAS: Partial Additive Speech Data Augmentation Method for Noise Robust Speaker Verification
Jul 20, 2023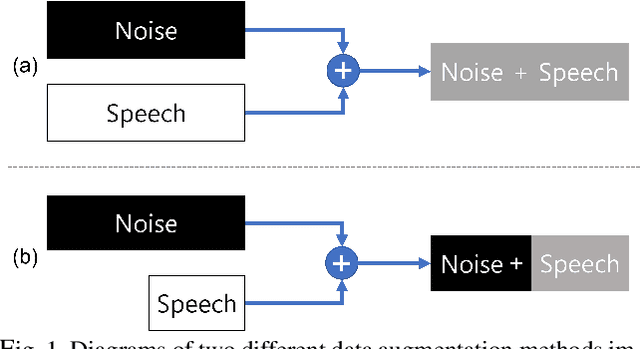
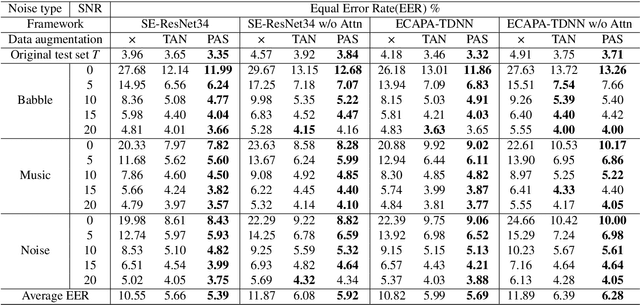
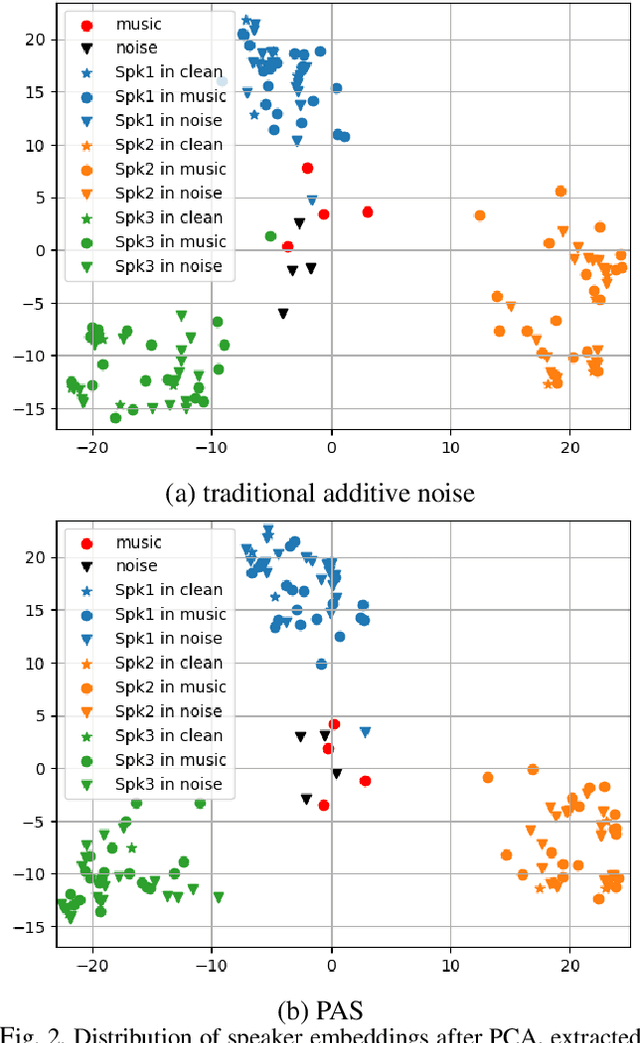
Background noise reduces speech intelligibility and quality, making speaker verification (SV) in noisy environments a challenging task. To improve the noise robustness of SV systems, additive noise data augmentation method has been commonly used. In this paper, we propose a new additive noise method, partial additive speech (PAS), which aims to train SV systems to be less affected by noisy environments. The experimental results demonstrate that PAS outperforms traditional additive noise in terms of equal error rates (EER), with relative improvements of 4.64% and 5.01% observed in SE-ResNet34 and ECAPA-TDNN. We also show the effectiveness of proposed method by analyzing attention modules and visualizing speaker embeddings.
One-Step Knowledge Distillation and Fine-Tuning in Using Large Pre-Trained Self-Supervised Learning Models for Speaker Verification
Jun 08, 2023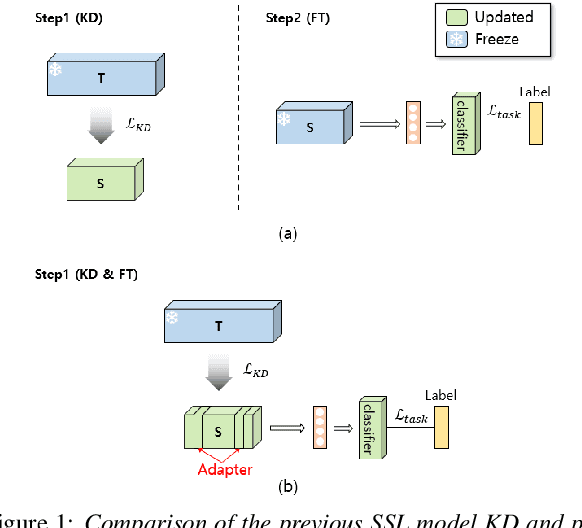

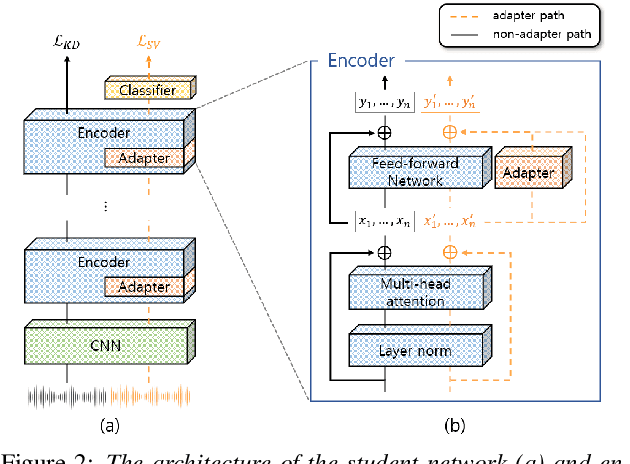

The application of speech self-supervised learning (SSL) models has achieved remarkable performance in speaker verification (SV). However, there is a computational cost hurdle in employing them, which makes development and deployment difficult. Several studies have simply compressed SSL models through knowledge distillation (KD) without considering the target task. Consequently, these methods could not extract SV-tailored features. This paper suggests One-Step Knowledge Distillation and Fine-Tuning (OS-KDFT), which incorporates KD and fine-tuning (FT). We optimize a student model for SV during KD training to avert the distillation of inappropriate information for the SV. OS-KDFT could downsize Wav2Vec 2.0 based ECAPA-TDNN size by approximately 76.2%, and reduce the SSL model's inference time by 79% while presenting an EER of 0.98%. The proposed OS-KDFT is validated across VoxCeleb1 and VoxCeleb2 datasets and W2V2 and HuBERT SSL models. Experiments are available on our GitHub.
Integrated Parameter-Efficient Tuning for General-Purpose Audio Models
Nov 04, 2022



The advent of hyper-scale and general-purpose pre-trained models is shifting the paradigm of building task-specific models for target tasks. In the field of audio research, task-agnostic pre-trained models with high transferability and adaptability have achieved state-of-the-art performances through fine-tuning for downstream tasks. Nevertheless, re-training all the parameters of these massive models entails an enormous amount of time and cost, along with a huge carbon footprint. To overcome these limitations, the present study explores and applies efficient transfer learning methods in the audio domain. We also propose an integrated parameter-efficient tuning (IPET) framework by aggregating the embedding prompt (a prompt-based learning approach), and the adapter (an effective transfer learning method). We demonstrate the efficacy of the proposed framework using two backbone pre-trained audio models with different characteristics: the audio spectrogram transformer and wav2vec 2.0. The proposed IPET framework exhibits remarkable performance compared to fine-tuning method with fewer trainable parameters in four downstream tasks: sound event classification, music genre classification, keyword spotting, and speaker verification. Furthermore, the authors identify and analyze the shortcomings of the IPET framework, providing lessons and research directions for parameter efficient tuning in the audio domain.
Convolution channel separation and frequency sub-bands aggregation for music genre classification
Nov 03, 2022



In music, short-term features such as pitch and tempo constitute long-term semantic features such as melody and narrative. A music genre classification (MGC) system should be able to analyze these features. In this research, we propose a novel framework that can extract and aggregate both short- and long-term features hierarchically. Our framework is based on ECAPA-TDNN, where all the layers that extract short-term features are affected by the layers that extract long-term features because of the back-propagation training. To prevent the distortion of short-term features, we devised the convolution channel separation technique that separates short-term features from long-term feature extraction paths. To extract more diverse features from our framework, we incorporated the frequency sub-bands aggregation method, which divides the input spectrogram along frequency bandwidths and processes each segment. We evaluated our framework using the Melon Playlist dataset which is a large-scale dataset containing 600 times more data than GTZAN which is a widely used dataset in MGC studies. As the result, our framework achieved 70.4% accuracy, which was improved by 16.9% compared to a conventional framework.
Two Methods for Spoofing-Aware Speaker Verification: Multi-Layer Perceptron Score Fusion Model and Integrated Embedding Projector
Jun 28, 2022



The use of deep neural networks (DNN) has dramatically elevated the performance of automatic speaker verification (ASV) over the last decade. However, ASV systems can be easily neutralized by spoofing attacks. Therefore, the Spoofing-Aware Speaker Verification (SASV) challenge is designed and held to promote development of systems that can perform ASV considering spoofing attacks by integrating ASV and spoofing countermeasure (CM) systems. In this paper, we propose two back-end systems: multi-layer perceptron score fusion model (MSFM) and integrated embedding projector (IEP). The MSFM, score fusion back-end system, derived SASV score utilizing ASV and CM scores and embeddings. On the other hand,IEP combines ASV and CM embeddings into SASV embedding and calculates final SASV score based on the cosine similarity. We effectively integrated ASV and CM systems through proposed MSFM and IEP and achieved the SASV equal error rates 0.56%, 1.32% on the official evaluation trials of the SASV 2022 challenge.