 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRawNeXt: Speaker verification system for variable-duration utterances with deep layer aggregation and extended dynamic scaling policies
Paper and Code
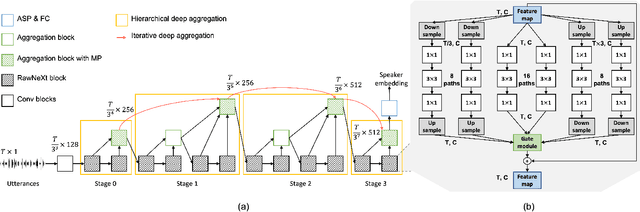
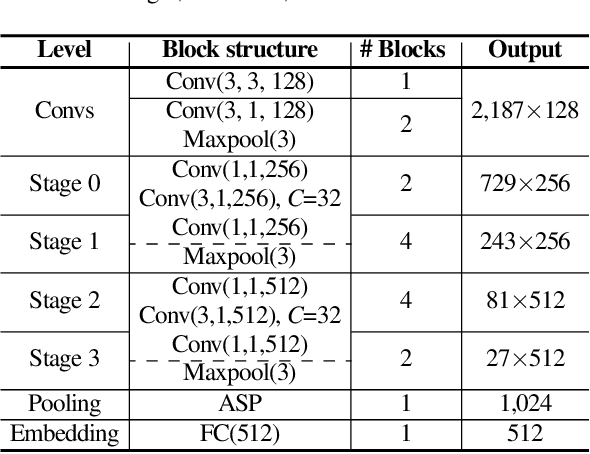


Despite achieving satisfactory performance in speaker verification using deep neural networks, variable-duration utterances remain a challenge that threatens the robustness of systems. To deal with this issue, we propose a speaker verification system called RawNeXt that can handle input raw waveforms of arbitrary length by employing the following two components: (1) A deep layer aggregation strategy enhances speaker information by iteratively and hierarchically aggregating features of various time scales and spectral channels output from blocks. (2) An extended dynamic scaling policy flexibly processes features according to the length of the utterance by selectively merging the activations of different resolution branches in each block. Owing to these two components, our proposed model can extract speaker embeddings rich in time-spectral information and operate dynamically on length variations. Experimental results on the VoxCeleb1 test set consisting of various duration utterances demonstrate that RawNeXt achieves state-of-the-art performance compared to the recently proposed systems. Our code and trained model weights are available at https://github.com/wngh1187/RawNeXt.