 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSV-Mixer: Replacing the Transformer Encoder with Lightweight MLPs for Self-Supervised Model Compression in Speaker Verification
Sep 17, 2025Self-supervised learning (SSL) has pushed speaker verification accuracy close to state-of-the-art levels, but the Transformer backbones used in most SSL encoders hinder on-device and real-time deployment. Prior compression work trims layer depth or width yet still inherits the quadratic cost of self-attention. We propose SV-Mixer, the first fully MLP-based student encoder for SSL distillation. SV-Mixer replaces Transformer with three lightweight modules: Multi-Scale Mixing for multi-resolution temporal features, Local-Global Mixing for frame-to-utterance context, and Group Channel Mixing for spectral subspaces. Distilled from WavLM, SV-Mixer outperforms a Transformer student by 14.6% while cutting parameters and GMACs by over half, and at 75% compression, it closely matches the teacher's performance. Our results show that attention-free SSL students can deliver teacher-level accuracy with hardware-friendly footprints, opening the door to robust on-device speaker verification.
Token-based Attractors and Cross-attention in Spoof Diarization
Sep 16, 2025Spoof diarization identifies ``what spoofed when" in a given speech by temporally locating spoofed regions and determining their manipulation techniques. As a first step toward this task, prior work proposed a two-branch model for localization and spoof type clustering, which laid the foundation for spoof diarization. However, its simple structure limits the ability to capture complex spoofing patterns and lacks explicit reference points for distinguishing between bona fide and various spoofing types. To address these limitations, our approach introduces learnable tokens where each token represents acoustic features of bona fide and spoofed speech. These attractors interact with frame-level embeddings to extract discriminative representations, improving separation between genuine and generated speech. Vast experiments on PartialSpoof dataset consistently demonstrate that our approach outperforms existing methods in bona fide detection and spoofing method clustering.
SEED: Speaker Embedding Enhancement Diffusion Model
May 22, 2025A primary challenge when deploying speaker recognition systems in real-world applications is performance degradation caused by environmental mismatch. We propose a diffusion-based method that takes speaker embeddings extracted from a pre-trained speaker recognition model and generates refined embeddings. For training, our approach progressively adds Gaussian noise to both clean and noisy speaker embeddings extracted from clean and noisy speech, respectively, via forward process of a diffusion model, and then reconstructs them to clean embeddings in the reverse process. While inferencing, all embeddings are regenerated via diffusion process. Our method needs neither speaker label nor any modification to the existing speaker recognition pipeline. Experiments on evaluation sets simulating environment mismatch scenarios show that our method can improve recognition accuracy by up to 19.6% over baseline models while retaining performance on conventional scenarios. We publish our code here https://github.com/kaistmm/seed-pytorch
MR-RawNet: Speaker verification system with multiple temporal resolutions for variable duration utterances using raw waveforms
Jun 11, 2024

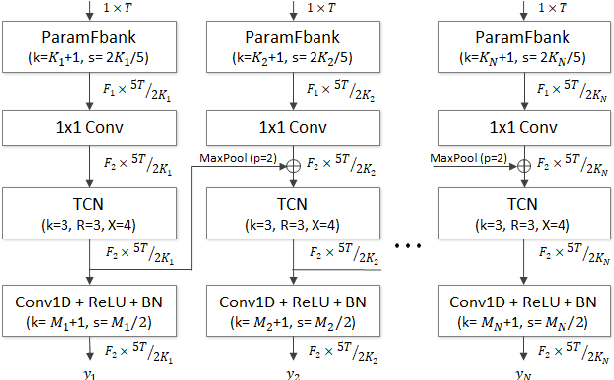

In speaker verification systems, the utilization of short utterances presents a persistent challenge, leading to performance degradation primarily due to insufficient phonetic information to characterize the speakers. To overcome this obstacle, we propose a novel structure, MR-RawNet, designed to enhance the robustness of speaker verification systems against variable duration utterances using raw waveforms. The MR-RawNet extracts time-frequency representations from raw waveforms via a multi-resolution feature extractor that optimally adjusts both temporal and spectral resolutions simultaneously. Furthermore, we apply a multi-resolution attention block that focuses on diverse and extensive temporal contexts, ensuring robustness against changes in utterance length. The experimental results, conducted on VoxCeleb1 dataset, demonstrate that the MR-RawNet exhibits superior performance in handling utterances of variable duration compared to other raw waveform-based systems.
NM-FlowGAN: Modeling sRGB Noise with a Hybrid Approach based on Normalizing Flows and Generative Adversarial Networks
Dec 15, 2023
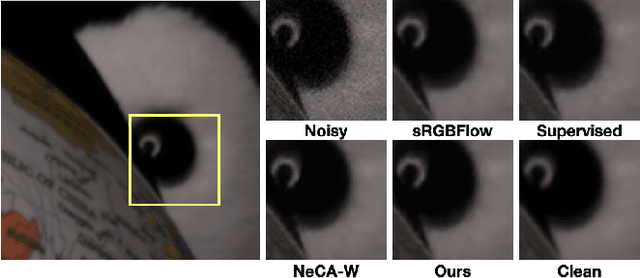
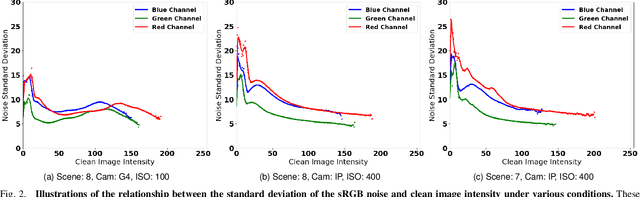

Modeling and synthesizing real sRGB noise is crucial for various low-level vision tasks. The distribution of real sRGB noise is highly complex and affected by a multitude of factors, making its accurate modeling extremely challenging. Therefore, recent studies have proposed methods that employ data-driven generative models, such as generative adversarial networks (GAN) and Normalizing Flows. These studies achieve more accurate modeling of sRGB noise compared to traditional noise modeling methods. However, there are performance limitations due to the inherent characteristics of each generative model. To address this issue, we propose NM-FlowGAN, a hybrid approach that exploits the strengths of both GAN and Normalizing Flows. We simultaneously employ a pixel-wise noise modeling network based on Normalizing Flows, and spatial correlation modeling networks based on GAN. In our experiments, our NM-FlowGAN outperforms other baselines on the sRGB noise synthesis task. Moreover, the denoising neural network, trained with synthesized image pairs from our model, also shows superior performance compared to other baselines. Our code is available at: https://github.com/YoungJooHan/NM-FlowGAN
HM-Conformer: A Conformer-based audio deepfake detection system with hierarchical pooling and multi-level classification token aggregation methods
Sep 15, 2023



Audio deepfake detection (ADD) is the task of detecting spoofing attacks generated by text-to-speech or voice conversion systems. Spoofing evidence, which helps to distinguish between spoofed and bona-fide utterances, might exist either locally or globally in the input features. To capture these, the Conformer, which consists of Transformers and CNN, possesses a suitable structure. However, since the Conformer was designed for sequence-to-sequence tasks, its direct application to ADD tasks may be sub-optimal. To tackle this limitation, we propose HM-Conformer by adopting two components: (1) Hierarchical pooling method progressively reducing the sequence length to eliminate duplicated information (2) Multi-level classification token aggregation method utilizing classification tokens to gather information from different blocks. Owing to these components, HM-Conformer can efficiently detect spoofing evidence by processing various sequence lengths and aggregating them. In experimental results on the ASVspoof 2021 Deepfake dataset, HM-Conformer achieved a 15.71% EER, showing competitive performance compared to recent systems.
Diff-SV: A Unified Hierarchical Framework for Noise-Robust Speaker Verification Using Score-Based Diffusion Probabilistic Models
Sep 14, 2023



Background noise considerably reduces the accuracy and reliability of speaker verification (SV) systems. These challenges can be addressed using a speech enhancement system as a front-end module. Recently, diffusion probabilistic models (DPMs) have exhibited remarkable noise-compensation capabilities in the speech enhancement domain. Building on this success, we propose Diff-SV, a noise-robust SV framework that leverages DPM. Diff-SV unifies a DPM-based speech enhancement system with a speaker embedding extractor, and yields a discriminative and noise-tolerable speaker representation through a hierarchical structure. The proposed model was evaluated under both in-domain and out-of-domain noisy conditions using the VoxCeleb1 test set, an external noise source, and the VOiCES corpus. The obtained experimental results demonstrate that Diff-SV achieves state-of-the-art performance, outperforming recently proposed noise-robust SV systems.
PAS: Partial Additive Speech Data Augmentation Method for Noise Robust Speaker Verification
Jul 20, 2023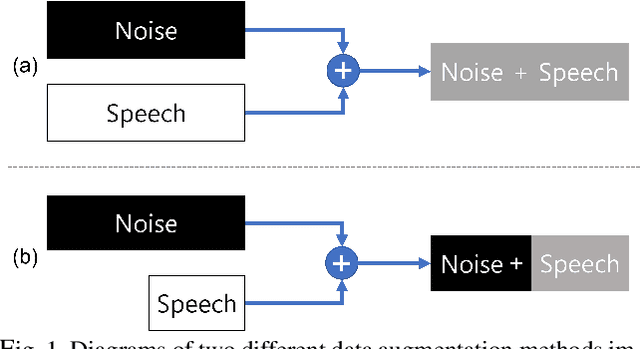
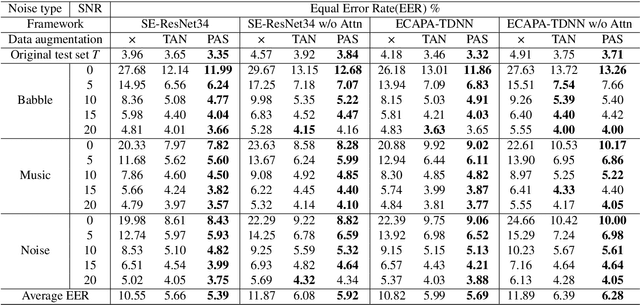
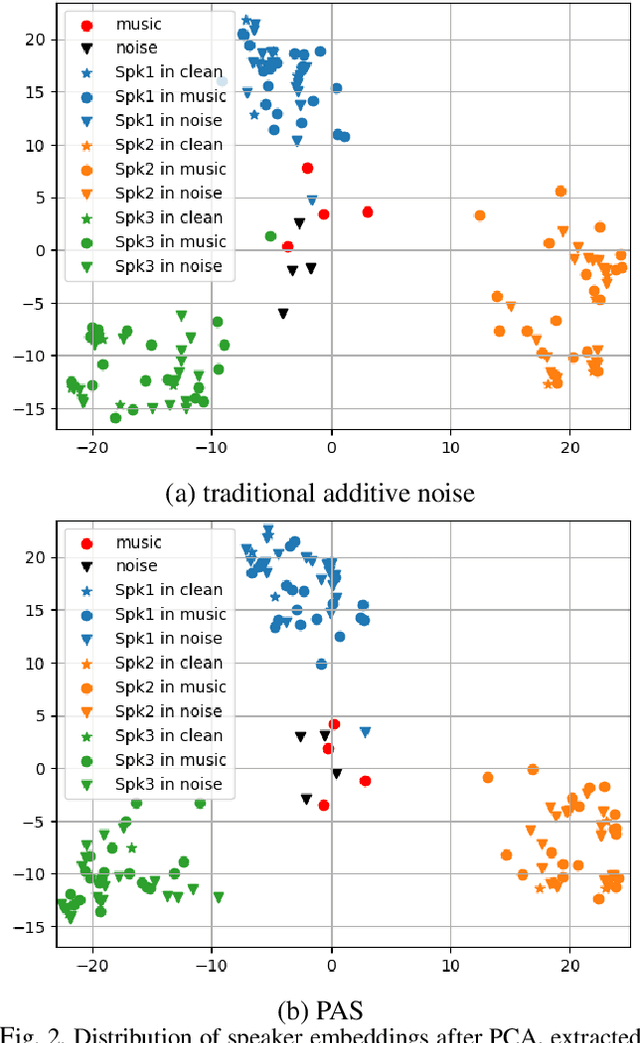
Background noise reduces speech intelligibility and quality, making speaker verification (SV) in noisy environments a challenging task. To improve the noise robustness of SV systems, additive noise data augmentation method has been commonly used. In this paper, we propose a new additive noise method, partial additive speech (PAS), which aims to train SV systems to be less affected by noisy environments. The experimental results demonstrate that PAS outperforms traditional additive noise in terms of equal error rates (EER), with relative improvements of 4.64% and 5.01% observed in SE-ResNet34 and ECAPA-TDNN. We also show the effectiveness of proposed method by analyzing attention modules and visualizing speaker embeddings.
One-Step Knowledge Distillation and Fine-Tuning in Using Large Pre-Trained Self-Supervised Learning Models for Speaker Verification
Jun 08, 2023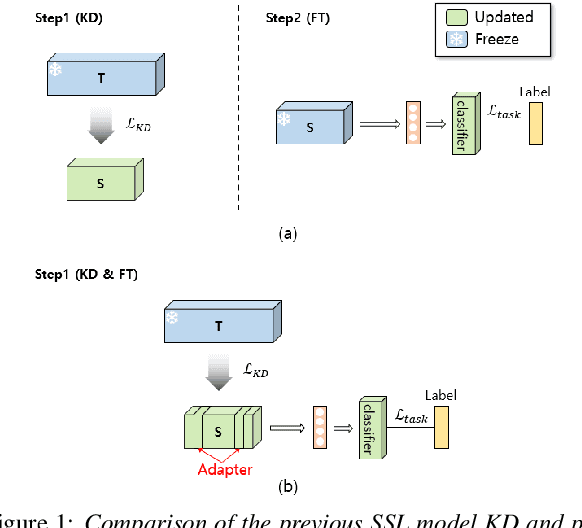

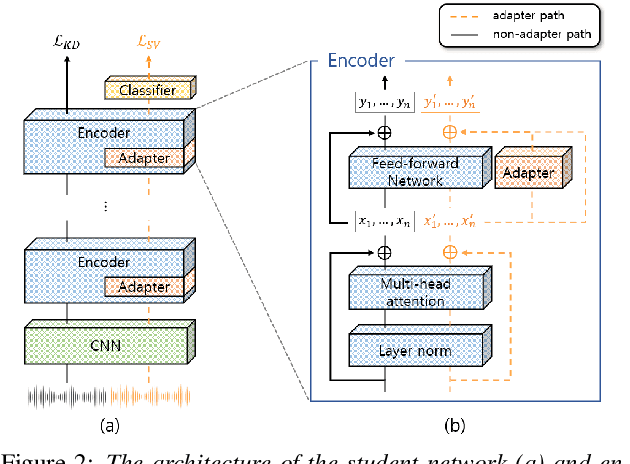

The application of speech self-supervised learning (SSL) models has achieved remarkable performance in speaker verification (SV). However, there is a computational cost hurdle in employing them, which makes development and deployment difficult. Several studies have simply compressed SSL models through knowledge distillation (KD) without considering the target task. Consequently, these methods could not extract SV-tailored features. This paper suggests One-Step Knowledge Distillation and Fine-Tuning (OS-KDFT), which incorporates KD and fine-tuning (FT). We optimize a student model for SV during KD training to avert the distillation of inappropriate information for the SV. OS-KDFT could downsize Wav2Vec 2.0 based ECAPA-TDNN size by approximately 76.2%, and reduce the SSL model's inference time by 79% while presenting an EER of 0.98%. The proposed OS-KDFT is validated across VoxCeleb1 and VoxCeleb2 datasets and W2V2 and HuBERT SSL models. Experiments are available on our GitHub.
SS-BSN: Attentive Blind-Spot Network for Self-Supervised Denoising with Nonlocal Self-Similarity
May 17, 2023
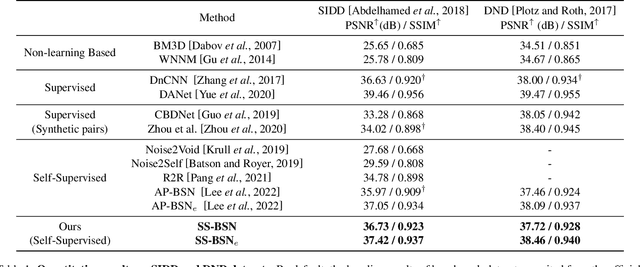


Recently, numerous studies have been conducted on supervised learning-based image denoising methods. However, these methods rely on large-scale noisy-clean image pairs, which are difficult to obtain in practice. Denoising methods with self-supervised training that can be trained with only noisy images have been proposed to address the limitation. These methods are based on the convolutional neural network (CNN) and have shown promising performance. However, CNN-based methods do not consider using nonlocal self-similarities essential in the traditional method, which can cause performance limitations. This paper presents self-similarity attention (SS-Attention), a novel self-attention module that can capture nonlocal self-similarities to solve the problem. We focus on designing a lightweight self-attention module in a pixel-wise manner, which is nearly impossible to implement using the classic self-attention module due to the quadratically increasing complexity with spatial resolution. Furthermore, we integrate SS-Attention into the blind-spot network called self-similarity-based blind-spot network (SS-BSN). We conduct the experiments on real-world image denoising tasks. The proposed method quantitatively and qualitatively outperforms state-of-the-art methods in self-supervised denoising on the Smartphone Image Denoising Dataset (SIDD) and Darmstadt Noise Dataset (DND) benchmark datasets.