 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtended U-Net for Speaker Verification in Noisy Environments
Paper and Code
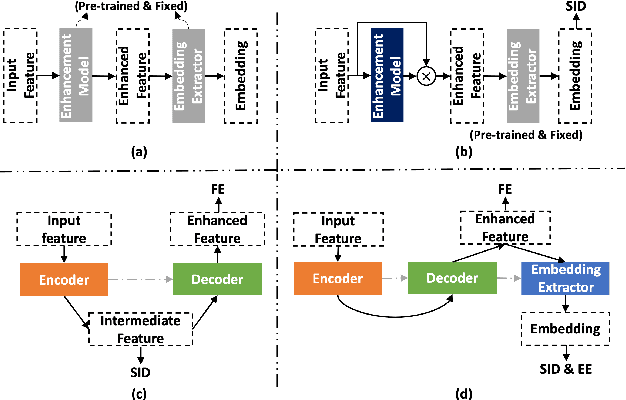
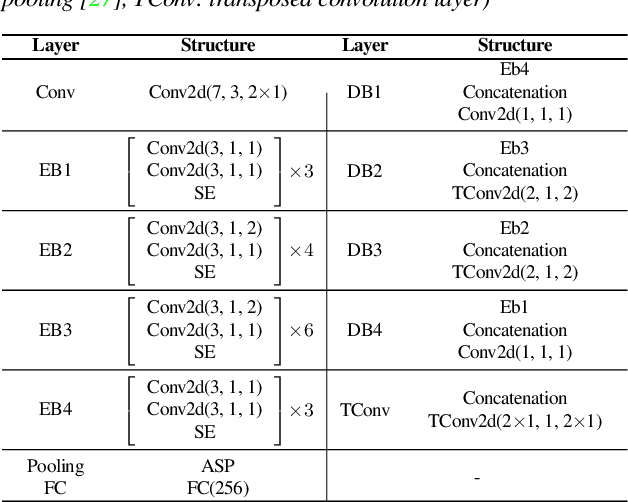
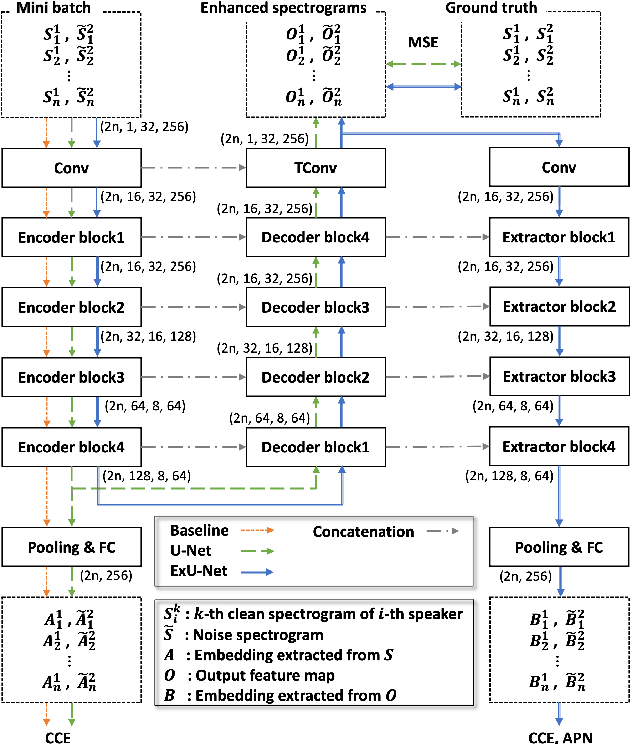

Background noise is a well-known factor that deteriorates the accuracy and reliability of speaker verification (SV) systems by blurring speech intelligibility. Various studies have used separate pretrained enhancement models as the front-end module of the SV system in noisy environments, and these methods effectively remove noises. However, the denoising process of independent enhancement models not tailored to the SV task can also distort the speaker information included in utterances. We argue that the enhancement network and speaker embedding extractor should be fully jointly trained for SV tasks under noisy conditions to alleviate this issue. Therefore, we proposed a U-Net-based integrated framework that simultaneously optimizes speaker identification and feature enhancement losses. Moreover, we analyzed the structural limitations of using U-Net directly for noise SV tasks and further proposed Extended U-Net to reduce these drawbacks. We evaluated the models on the noise-synthesized VoxCeleb1 test set and VOiCES development set recorded in various noisy scenarios. The experimental results demonstrate that the U-Net-based fully joint training framework is more effective than the baseline, and the extended U-Net exhibited state-of-the-art performance versus the recently proposed compensation systems.