 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-based Attractors and Cross-attention in Spoof Diarization
Sep 16, 2025Spoof diarization identifies ``what spoofed when" in a given speech by temporally locating spoofed regions and determining their manipulation techniques. As a first step toward this task, prior work proposed a two-branch model for localization and spoof type clustering, which laid the foundation for spoof diarization. However, its simple structure limits the ability to capture complex spoofing patterns and lacks explicit reference points for distinguishing between bona fide and various spoofing types. To address these limitations, our approach introduces learnable tokens where each token represents acoustic features of bona fide and spoofed speech. These attractors interact with frame-level embeddings to extract discriminative representations, improving separation between genuine and generated speech. Vast experiments on PartialSpoof dataset consistently demonstrate that our approach outperforms existing methods in bona fide detection and spoofing method clustering.
MR-RawNet: Speaker verification system with multiple temporal resolutions for variable duration utterances using raw waveforms
Jun 11, 2024

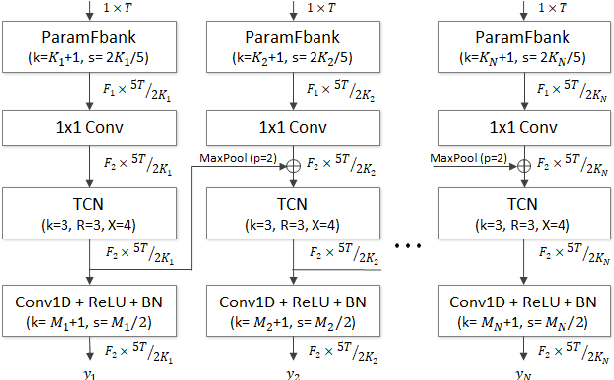

In speaker verification systems, the utilization of short utterances presents a persistent challenge, leading to performance degradation primarily due to insufficient phonetic information to characterize the speakers. To overcome this obstacle, we propose a novel structure, MR-RawNet, designed to enhance the robustness of speaker verification systems against variable duration utterances using raw waveforms. The MR-RawNet extracts time-frequency representations from raw waveforms via a multi-resolution feature extractor that optimally adjusts both temporal and spectral resolutions simultaneously. Furthermore, we apply a multi-resolution attention block that focuses on diverse and extensive temporal contexts, ensuring robustness against changes in utterance length. The experimental results, conducted on VoxCeleb1 dataset, demonstrate that the MR-RawNet exhibits superior performance in handling utterances of variable duration compared to other raw waveform-based systems.