 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSV-Mixer: Replacing the Transformer Encoder with Lightweight MLPs for Self-Supervised Model Compression in Speaker Verification
Sep 17, 2025


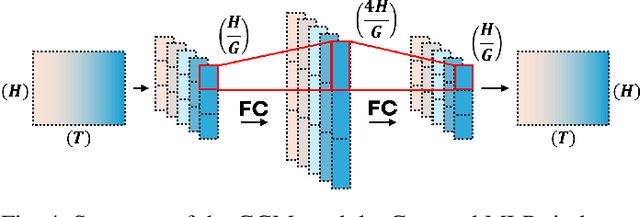
Self-supervised learning (SSL) has pushed speaker verification accuracy close to state-of-the-art levels, but the Transformer backbones used in most SSL encoders hinder on-device and real-time deployment. Prior compression work trims layer depth or width yet still inherits the quadratic cost of self-attention. We propose SV-Mixer, the first fully MLP-based student encoder for SSL distillation. SV-Mixer replaces Transformer with three lightweight modules: Multi-Scale Mixing for multi-resolution temporal features, Local-Global Mixing for frame-to-utterance context, and Group Channel Mixing for spectral subspaces. Distilled from WavLM, SV-Mixer outperforms a Transformer student by 14.6% while cutting parameters and GMACs by over half, and at 75% compression, it closely matches the teacher's performance. Our results show that attention-free SSL students can deliver teacher-level accuracy with hardware-friendly footprints, opening the door to robust on-device speaker verification.
MR-RawNet: Speaker verification system with multiple temporal resolutions for variable duration utterances using raw waveforms
Jun 11, 2024

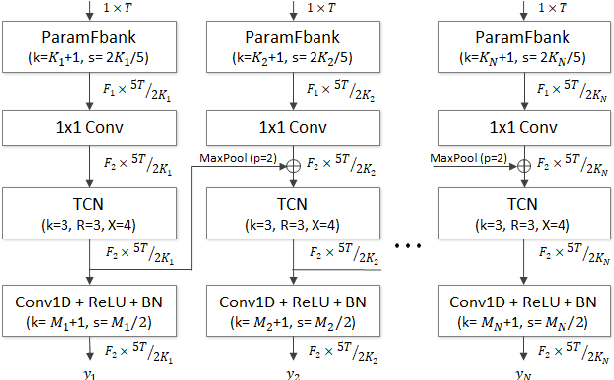

In speaker verification systems, the utilization of short utterances presents a persistent challenge, leading to performance degradation primarily due to insufficient phonetic information to characterize the speakers. To overcome this obstacle, we propose a novel structure, MR-RawNet, designed to enhance the robustness of speaker verification systems against variable duration utterances using raw waveforms. The MR-RawNet extracts time-frequency representations from raw waveforms via a multi-resolution feature extractor that optimally adjusts both temporal and spectral resolutions simultaneously. Furthermore, we apply a multi-resolution attention block that focuses on diverse and extensive temporal contexts, ensuring robustness against changes in utterance length. The experimental results, conducted on VoxCeleb1 dataset, demonstrate that the MR-RawNet exhibits superior performance in handling utterances of variable duration compared to other raw waveform-based systems.
Integrated Replay Spoofing-aware Text-independent Speaker Verification
Jun 10, 2020



A number of studies have successfully developed speaker verification or spoofing detection systems. However, studies integrating the two tasks remain in the preliminary stages. In this paper, we propose two approaches for the integrated replay spoofing-aware speaker verification task: an end-to-end monolithic and a back-end modular approach. The first approach simultaneously trains speaker identification, replay spoofing detection, and the integrated system using multi-task learning with a common feature. However, through experiments, we hypothesize that the information required for performing speaker verification and replay spoofing detection might differ because speaker verification systems try to remove device-specific information from speaker embeddings while replay spoofing exploits such information. Therefore, we propose a back-end approach using a deep neural network that takes speaker embeddings extracted from enrollment and test utterances and a replay detection prediction on the test utterance as input. Experiments are conducted using the ASVspoof 2017-v2 dataset, which includes official trials on the integration of speaker verification and replay spoofing detection. The proposed back-end approach demonstrates a relative improvement of 21.77% in terms of the equal error rate for integrated trials compared to a conventional speaker verification system.
Segment Aggregation for short utterances speaker verification using raw waveforms
May 11, 2020



Most studies on speaker verification systems focus on long-duration utterances, which are composed of sufficient phonetic information. However, the performances of these systems are known to degrade when short-duration utterances are inputted due to the lack of phonetic information as compared to the long utterances. In this paper, we propose a method that compensates for the performance degradation of speaker verification for short utterances, referred to as "segment aggregation". The proposed method adopts an ensemble-based design to improve the stability and accuracy of speaker verification systems. The proposed method segments an input utterance into several short utterances and then aggregates the segment embeddings extracted from the segmented inputs to compose a speaker embedding. Then, this method simultaneously trains the segment embeddings and the aggregated speaker embedding. In addition, we also modified the teacher-student learning method for the proposed method. Experimental results on different input duration using the VoxCeleb1 test set demonstrate that the proposed technique improves speaker verification performance by about 45.37% relatively compared to the baseline system with 1-second test utterance condition.
Improved RawNet with Filter-wise Rescaling for Text-independent Speaker Verification using Raw Waveforms
Apr 01, 2020



Recent advances in deep learning have facilitated the design of speaker verification systems that directly input raw waveforms. For example, RawNet extracts speaker embeddings from raw waveforms, which simplifies the process pipeline and demonstrates competitive performance. In this study, we improve RawNet by rescaling feature maps using various methods. The proposed mechanism utilizes a filter-wise rescale map that adopts a sigmoid non-linear function. It refers to a vector with dimensionality equal to the number of filters in a given feature map. Using a filter-wise rescale map, we propose to rescale the feature map multiplicatively, additively, or both. In addition, we investigate replacing the first convolution layer with the sinc-convolution layer of SincNet. Experiments performed on the VoxCeleb1 evaluation dataset demonstrate that the proposed methods are effective, and the best performing system reduces the equal error rate by half compared to the original RawNet. Expanded evaluation results obtained using the VoxCeleb1-E and VoxCeleb-H protocols marginally outperform existing state-of-the-art systems.