 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeighbourhood Watch: Referring Expression Comprehension via Language-guided Graph Attention Networks
Paper and Code
Dec 12, 2018

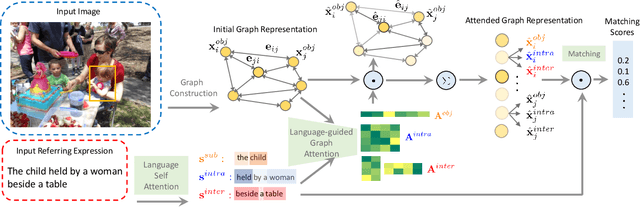
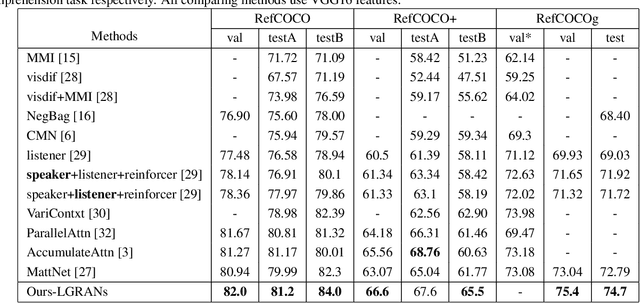
The task in referring expression comprehension is to localise the object instance in an image described by a referring expression phrased in natural language. As a language-to-vision matching task, the key to this problem is to learn a discriminative object feature that can adapt to the expression used. To avoid ambiguity, the expression normally tends to describe not only the properties of the referent itself, but also its relationships to its neighbourhood. To capture and exploit this important information we propose a graph-based, language-guided attention mechanism. Being composed of node attention component and edge attention component, the proposed graph attention mechanism explicitly represents inter-object relationships, and properties with a flexibility and power impossible with competing approaches. Furthermore, the proposed graph attention mechanism enables the comprehension decision to be visualisable and explainable. Experiments on three referring expression comprehension datasets show the advantage of the proposed approach.