 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAG-3D: Multi-Agent Grounded Reasoning for 3D Understanding
Apr 10, 2026Vision-language models (VLMs) have achieved strong performance in multimodal understanding and reasoning, yet grounded reasoning in 3D scenes remains underexplored. Effective 3D reasoning hinges on accurate grounding: to answer open-ended queries, a model must first identify query-relevant objects and regions in a complex scene, and then reason about their spatial and geometric relationships. Recent approaches have demonstrated strong potential for grounded 3D reasoning. However, they often rely on in-domain tuning or hand-crafted reasoning pipelines, which limit their flexibility and zero-shot generalization to novel environments. In this work, we present MAG-3D, a training-free multi-agent framework for grounded 3D reasoning with off-the-shelf VLMs. Instead of relying on task-specific training or fixed reasoning procedures, MAG-3D dynamically coordinates expert agents to address the key challenges of 3D reasoning. Specifically, we propose a planning agent that decomposes the task and orchestrates the overall reasoning process, a grounding agent that performs free-form 3D grounding and relevant frame retrieval from extensive 3D scene observations, and a coding agent that conducts flexible geometric reasoning and explicit verification through executable programs. This multi-agent collaborative design enables flexible training-free 3D grounded reasoning across diverse scenes and achieves state-of-the-art performance on challenging benchmarks.
DenseGrounding: Improving Dense Language-Vision Semantics for Ego-Centric 3D Visual Grounding
May 08, 2025Enabling intelligent agents to comprehend and interact with 3D environments through natural language is crucial for advancing robotics and human-computer interaction. A fundamental task in this field is ego-centric 3D visual grounding, where agents locate target objects in real-world 3D spaces based on verbal descriptions. However, this task faces two significant challenges: (1) loss of fine-grained visual semantics due to sparse fusion of point clouds with ego-centric multi-view images, (2) limited textual semantic context due to arbitrary language descriptions. We propose DenseGrounding, a novel approach designed to address these issues by enhancing both visual and textual semantics. For visual features, we introduce the Hierarchical Scene Semantic Enhancer, which retains dense semantics by capturing fine-grained global scene features and facilitating cross-modal alignment. For text descriptions, we propose a Language Semantic Enhancer that leverages large language models to provide rich context and diverse language descriptions with additional context during model training. Extensive experiments show that DenseGrounding significantly outperforms existing methods in overall accuracy, with improvements of 5.81% and 7.56% when trained on the comprehensive full dataset and smaller mini subset, respectively, further advancing the SOTA in egocentric 3D visual grounding. Our method also achieves 1st place and receives the Innovation Award in the CVPR 2024 Autonomous Grand Challenge Multi-view 3D Visual Grounding Track, validating its effectiveness and robustness.
ProxyTransformation: Preshaping Point Cloud Manifold With Proxy Attention For 3D Visual Grounding
Feb 26, 2025Embodied intelligence requires agents to interact with 3D environments in real time based on language instructions. A foundational task in this domain is ego-centric 3D visual grounding. However, the point clouds rendered from RGB-D images retain a large amount of redundant background data and inherent noise, both of which can interfere with the manifold structure of the target regions. Existing point cloud enhancement methods often require a tedious process to improve the manifold, which is not suitable for real-time tasks. We propose Proxy Transformation suitable for multimodal task to efficiently improve the point cloud manifold. Our method first leverages Deformable Point Clustering to identify the point cloud sub-manifolds in target regions. Then, we propose a Proxy Attention module that utilizes multimodal proxies to guide point cloud transformation. Built upon Proxy Attention, we design a submanifold transformation generation module where textual information globally guides translation vectors for different submanifolds, optimizing relative spatial relationships of target regions. Simultaneously, image information guides linear transformations within each submanifold, refining the local point cloud manifold of target regions. Extensive experiments demonstrate that Proxy Transformation significantly outperforms all existing methods, achieving an impressive improvement of 7.49% on easy targets and 4.60% on hard targets, while reducing the computational overhead of attention blocks by 40.6%. These results establish a new SOTA in ego-centric 3D visual grounding, showcasing the effectiveness and robustness of our approach.
Training an Open-Vocabulary Monocular 3D Object Detection Model without 3D Data
Nov 23, 2024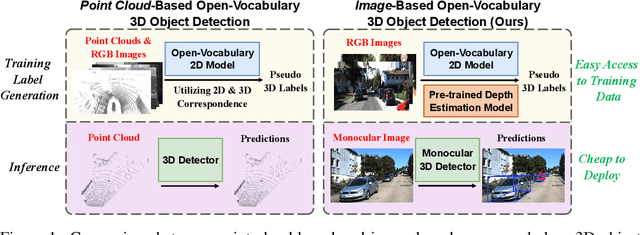
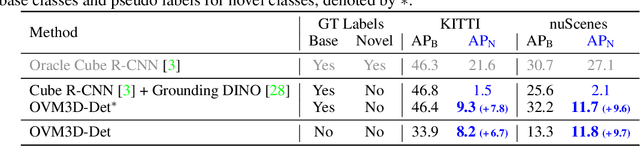
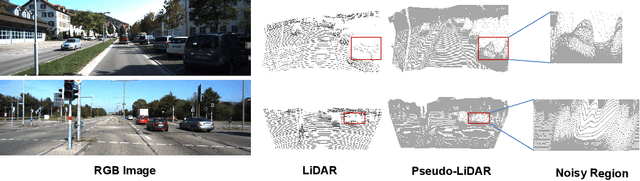
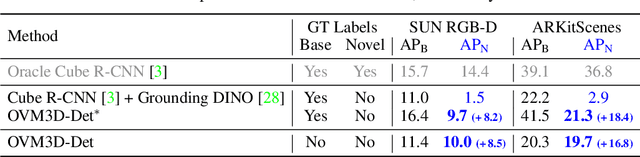
Open-vocabulary 3D object detection has recently attracted considerable attention due to its broad applications in autonomous driving and robotics, which aims to effectively recognize novel classes in previously unseen domains. However, existing point cloud-based open-vocabulary 3D detection models are limited by their high deployment costs. In this work, we propose a novel open-vocabulary monocular 3D object detection framework, dubbed OVM3D-Det, which trains detectors using only RGB images, making it both cost-effective and scalable to publicly available data. Unlike traditional methods, OVM3D-Det does not require high-precision LiDAR or 3D sensor data for either input or generating 3D bounding boxes. Instead, it employs open-vocabulary 2D models and pseudo-LiDAR to automatically label 3D objects in RGB images, fostering the learning of open-vocabulary monocular 3D detectors. However, training 3D models with labels directly derived from pseudo-LiDAR is inadequate due to imprecise boxes estimated from noisy point clouds and severely occluded objects. To address these issues, we introduce two innovative designs: adaptive pseudo-LiDAR erosion and bounding box refinement with prior knowledge from large language models. These techniques effectively calibrate the 3D labels and enable RGB-only training for 3D detectors. Extensive experiments demonstrate the superiority of OVM3D-Det over baselines in both indoor and outdoor scenarios. The code will be released.
Reducing Overtreatment of Indeterminate Thyroid Nodules Using a Multimodal Deep Learning Model
Sep 27, 2024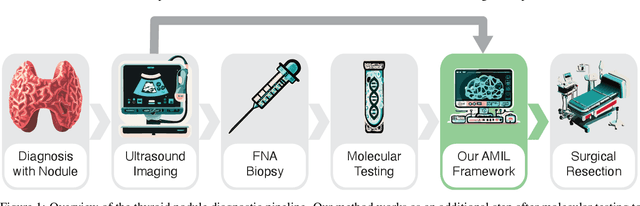
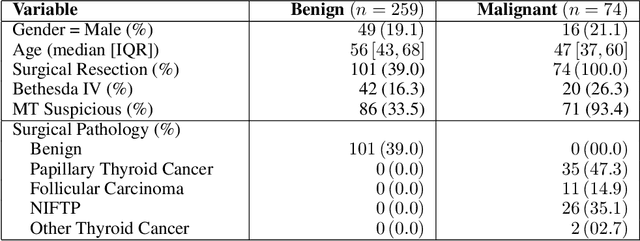
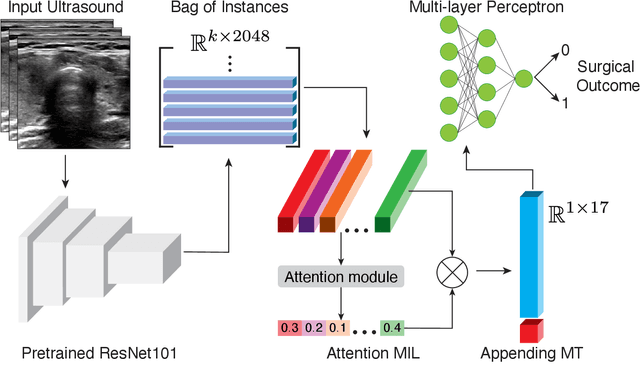
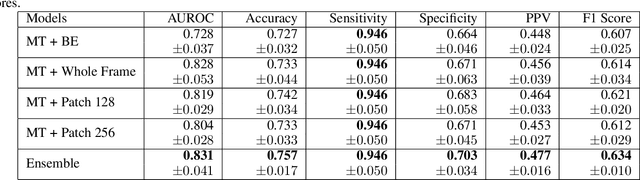
Objective: Molecular testing (MT) classifies cytologically indeterminate thyroid nodules as benign or malignant with high sensitivity but low positive predictive value (PPV), only using molecular profiles, ignoring ultrasound (US) imaging and biopsy. We address this limitation by applying attention multiple instance learning (AMIL) to US images. Methods: We retrospectively reviewed 333 patients with indeterminate thyroid nodules at UCLA medical center (259 benign, 74 malignant). A multi-modal deep learning AMIL model was developed, combining US images and MT to classify the nodules as benign or malignant and enhance the malignancy risk stratification of MT. Results: The final AMIL model matched MT sensitivity (0.946) while significantly improving PPV (0.477 vs 0.448 for MT alone), indicating fewer false positives while maintaining high sensitivity. Conclusion: Our approach reduces false positives compared to MT while maintaining the same ability to identify positive cases, potentially reducing unnecessary benign thyroid resections in patients with indeterminate nodules.
Mask Grounding for Referring Image Segmentation
Dec 19, 2023
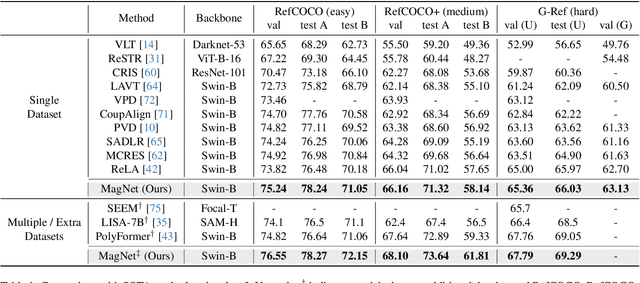
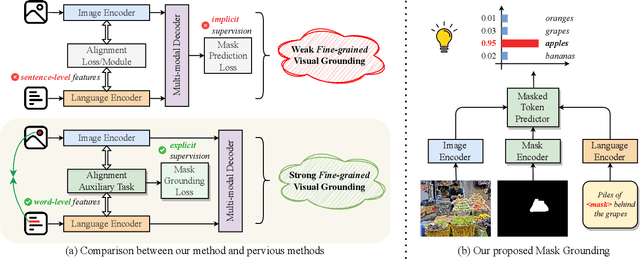
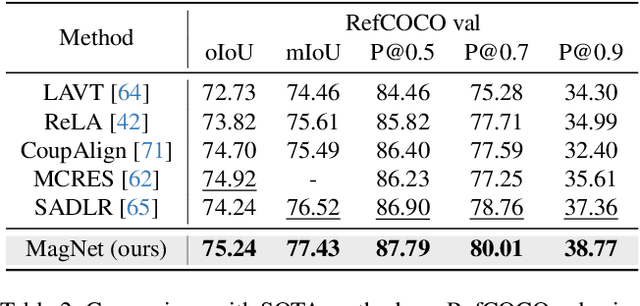
Referring Image Segmentation (RIS) is a challenging task that requires an algorithm to segment objects referred by free-form language expressions. Despite significant progress in recent years, most state-of-the-art (SOTA) methods still suffer from considerable language-image modality gap at the pixel and word level. These methods generally 1) rely on sentence-level language features for language-image alignment and 2) lack explicit training supervision for fine-grained visual grounding. Consequently, they exhibit weak object-level correspondence between visual and language features. Without well-grounded features, prior methods struggle to understand complex expressions that require strong reasoning over relationships among multiple objects, especially when dealing with rarely used or ambiguous clauses. To tackle this challenge, we introduce a novel Mask Grounding auxiliary task that significantly improves visual grounding within language features, by explicitly teaching the model to learn fine-grained correspondence between masked textual tokens and their matching visual objects. Mask Grounding can be directly used on prior RIS methods and consistently bring improvements. Furthermore, to holistically address the modality gap, we also design a cross-modal alignment loss and an accompanying alignment module. These additions work synergistically with Mask Grounding. With all these techniques, our comprehensive approach culminates in MagNet Mask-grounded Network), an architecture that significantly outperforms prior arts on three key benchmarks (RefCOCO, RefCOCO+ and G-Ref), demonstrating our method's effectiveness in addressing current limitations of RIS algorithms. Our code and pre-trained weights will be released.
Joint Representation Learning for Text and 3D Point Cloud
Jan 18, 2023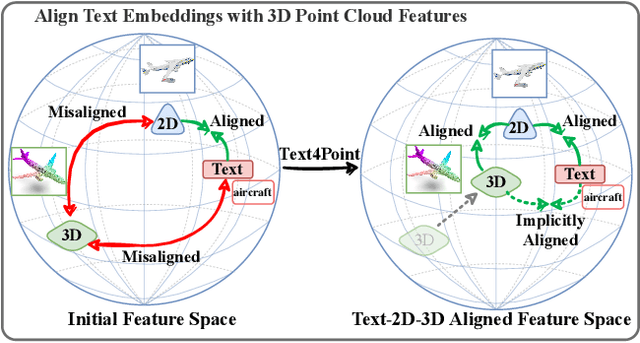
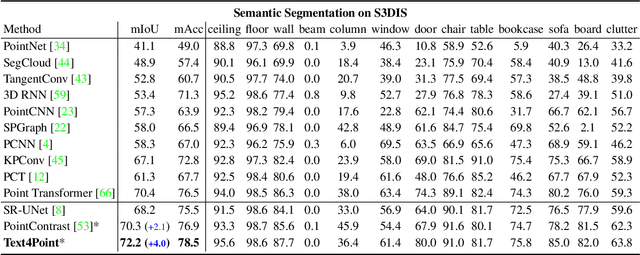
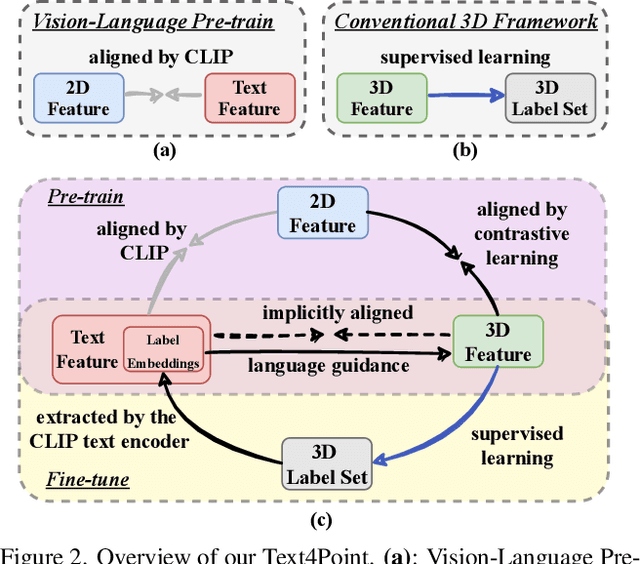
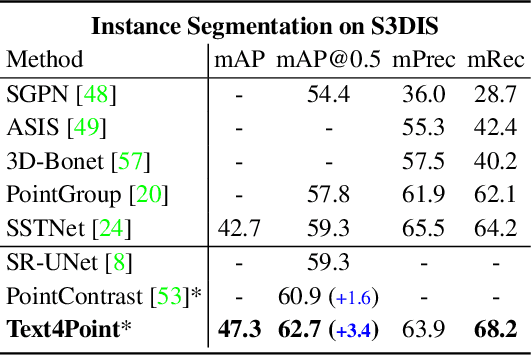
Recent advancements in vision-language pre-training (e.g. CLIP) have shown that vision models can benefit from language supervision. While many models using language modality have achieved great success on 2D vision tasks, the joint representation learning of 3D point cloud with text remains under-explored due to the difficulty of 3D-Text data pair acquisition and the irregularity of 3D data structure. In this paper, we propose a novel Text4Point framework to construct language-guided 3D point cloud models. The key idea is utilizing 2D images as a bridge to connect the point cloud and the language modalities. The proposed Text4Point follows the pre-training and fine-tuning paradigm. During the pre-training stage, we establish the correspondence of images and point clouds based on the readily available RGB-D data and use contrastive learning to align the image and point cloud representations. Together with the well-aligned image and text features achieved by CLIP, the point cloud features are implicitly aligned with the text embeddings. Further, we propose a Text Querying Module to integrate language information into 3D representation learning by querying text embeddings with point cloud features. For fine-tuning, the model learns task-specific 3D representations under informative language guidance from the label set without 2D images. Extensive experiments demonstrate that our model shows consistent improvement on various downstream tasks, such as point cloud semantic segmentation, instance segmentation, and object detection. The code will be available here: https://github.com/LeapLabTHU/Text4Point
Robotic Dough Shaping
Jul 31, 2022

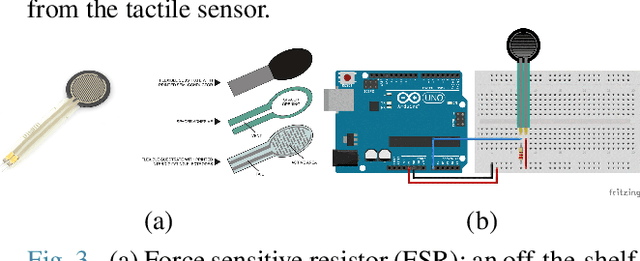
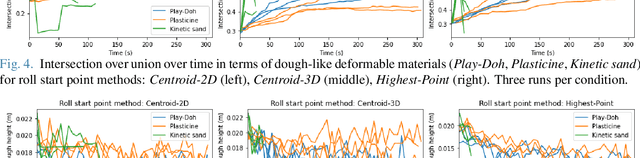
We address the problem of shaping a piece of dough-like deformable material into a 2D target shape presented upfront. We use a 6 degree-of-freedom WidowX-250 Robot Arm equipped with a rolling pin and information collected from an RGB-D camera and a tactile sensor. We present and compare several control policies, including a dough shrinking action, in extensive experiments across three kinds of deformable materials and across three target dough shape sizes, achieving the intersection over union (IoU) of 0.90. Our results show that: i) rolling dough from the highest dough point is more efficient than from the 2D/3D dough centroid; ii) it might be better to stop the roll movement at the current dough boundary as opposed to the target shape outline; iii) the shrink action might be beneficial only if properly tuned with respect to the exapand action; and iv) the Play-Doh material is easier to shape to a target shape as compared to Plasticine or Kinetic sand. Video demonstrations of our work are available at https://youtu.be/ZzLMxuITdt4