 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Train Your Dragon: Automatic Diffusion-Based Rigging for Characters with Diverse Topologies
Mar 19, 2025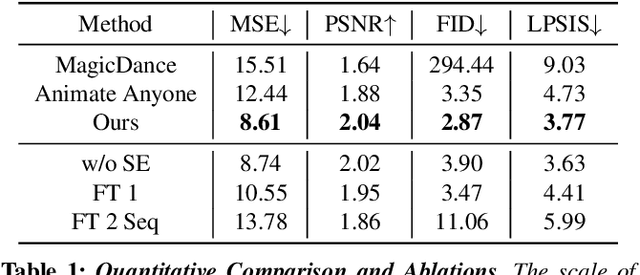
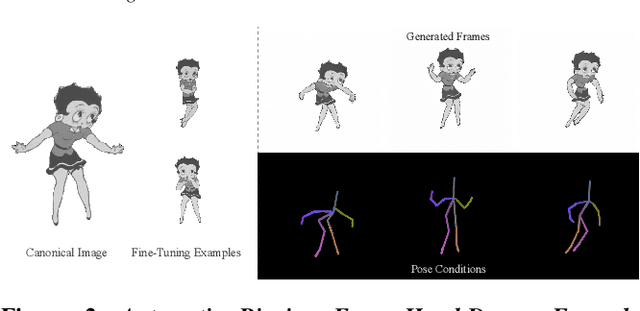
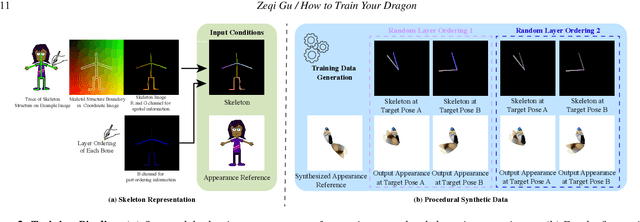
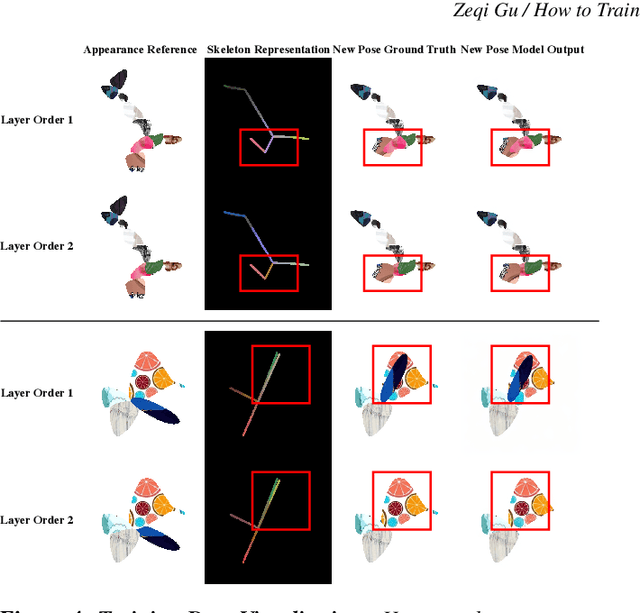
Recent diffusion-based methods have achieved impressive results on animating images of human subjects. However, most of that success has built on human-specific body pose representations and extensive training with labeled real videos. In this work, we extend the ability of such models to animate images of characters with more diverse skeletal topologies. Given a small number (3-5) of example frames showing the character in different poses with corresponding skeletal information, our model quickly infers a rig for that character that can generate images corresponding to new skeleton poses. We propose a procedural data generation pipeline that efficiently samples training data with diverse topologies on the fly. We use it, along with a novel skeleton representation, to train our model on articulated shapes spanning a large space of textures and topologies. Then during fine-tuning, our model rapidly adapts to unseen target characters and generalizes well to rendering new poses, both for realistic and more stylized cartoon appearances. To better evaluate performance on this novel and challenging task, we create the first 2D video dataset that contains both humanoid and non-humanoid subjects with per-frame keypoint annotations. With extensive experiments, we demonstrate the superior quality of our results. Project page: https://traindragondiffusion.github.io/
Filtered-Guided Diffusion: Fast Filter Guidance for Black-Box Diffusion Models
Jun 29, 2023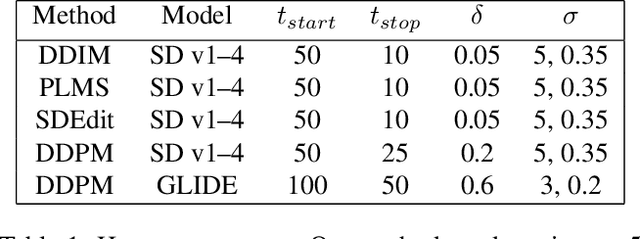


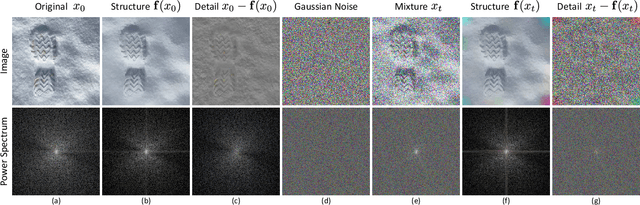
Recent advances in diffusion-based generative models have shown incredible promise for Image-to-Image translation and editing. Most recent work in this space relies on additional training or architecture-specific adjustments to the diffusion process. In this work, we show that much of this low-level control can be achieved without additional training or any access to features of the diffusion model. Our method simply applies a filter to the input of each diffusion step based on the output of the previous step in an adaptive manner. Notably, this approach does not depend on any specific architecture or sampler and can be done without access to internal features of the network, making it easy to combine with other techniques, samplers, and diffusion architectures. Furthermore, it has negligible cost to performance, and allows for more continuous adjustment of guidance strength than other approaches. We show FGD offers a fast and strong baseline that is competitive with recent architecture-dependent approaches. Furthermore, FGD can also be used as a simple add-on to enhance the structural guidance of other state-of-the-art I2I methods. Finally, our derivation of this method helps to understand the impact of self attention, a key component of other recent architecture-specific I2I approaches, in a more architecture-independent way. Project page: https://github.com/jaclyngu/FilteredGuidedDiffusion
FactorMatte: Redefining Video Matting for Re-Composition Tasks
Nov 03, 2022We propose "factor matting", an alternative formulation of the video matting problem in terms of counterfactual video synthesis that is better suited for re-composition tasks. The goal of factor matting is to separate the contents of video into independent components, each visualizing a counterfactual version of the scene where contents of other components have been removed. We show that factor matting maps well to a more general Bayesian framing of the matting problem that accounts for complex conditional interactions between layers. Based on this observation, we present a method for solving the factor matting problem that produces useful decompositions even for video with complex cross-layer interactions like splashes, shadows, and reflections. Our method is trained per-video and requires neither pre-training on external large datasets, nor knowledge about the 3D structure of the scene. We conduct extensive experiments, and show that our method not only can disentangle scenes with complex interactions, but also outperforms top methods on existing tasks such as classical video matting and background subtraction. In addition, we demonstrate the benefits of our approach on a range of downstream tasks. Please refer to our project webpage for more details: https://factormatte.github.io
Robotic Dough Shaping
Jul 31, 2022

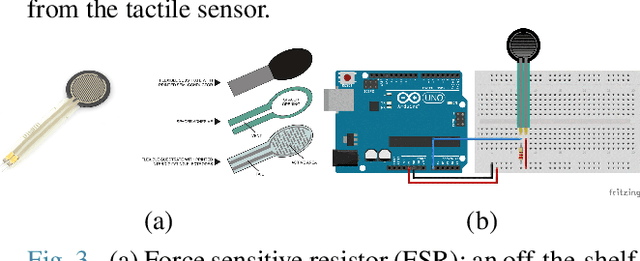
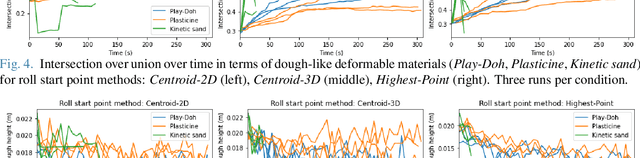
We address the problem of shaping a piece of dough-like deformable material into a 2D target shape presented upfront. We use a 6 degree-of-freedom WidowX-250 Robot Arm equipped with a rolling pin and information collected from an RGB-D camera and a tactile sensor. We present and compare several control policies, including a dough shrinking action, in extensive experiments across three kinds of deformable materials and across three target dough shape sizes, achieving the intersection over union (IoU) of 0.90. Our results show that: i) rolling dough from the highest dough point is more efficient than from the 2D/3D dough centroid; ii) it might be better to stop the roll movement at the current dough boundary as opposed to the target shape outline; iii) the shrink action might be beneficial only if properly tuned with respect to the exapand action; and iv) the Play-Doh material is easier to shape to a target shape as compared to Plasticine or Kinetic sand. Video demonstrations of our work are available at https://youtu.be/ZzLMxuITdt4
Measuring Dataset Granularity
Dec 21, 2019
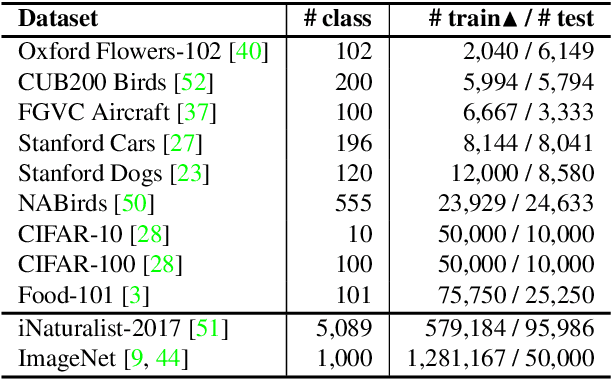
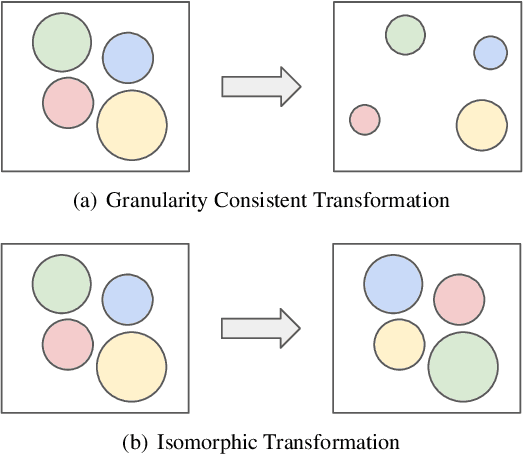

Despite the increasing visibility of fine-grained recognition in our field, "fine-grained'' has thus far lacked a precise definition. In this work, building upon clustering theory, we pursue a framework for measuring dataset granularity. We argue that dataset granularity should depend not only on the data samples and their labels, but also on the distance function we choose. We propose an axiomatic framework to capture desired properties for a dataset granularity measure and provide examples of measures that satisfy these properties. We assess each measure via experiments on datasets with hierarchical labels of varying granularity. When measuring granularity in commonly used datasets with our measure, we find that certain datasets that are widely considered fine-grained in fact contain subsets of considerable size that are substantially more coarse-grained than datasets generally regarded as coarse-grained. We also investigate the interplay between dataset granularity with a variety of factors and find that fine-grained datasets are more difficult to learn from, more difficult to transfer to, more difficult to perform few-shot learning with, and more vulnerable to adversarial attacks.
Enhancing Adversarial Example Transferability with an Intermediate Level Attack
Jul 23, 2019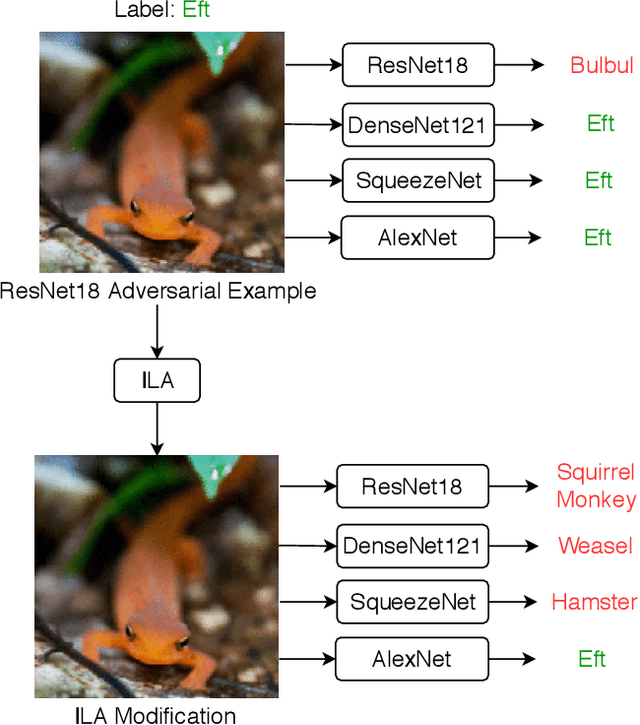
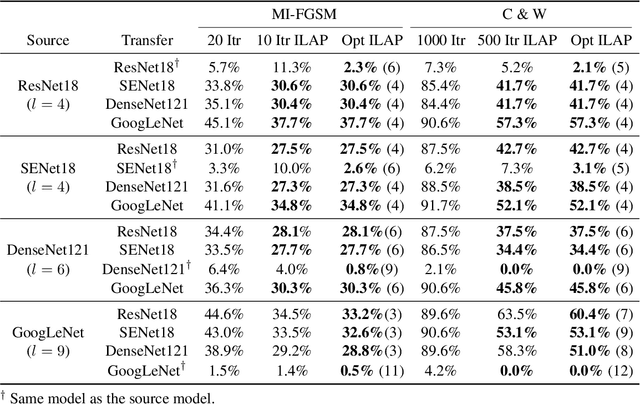

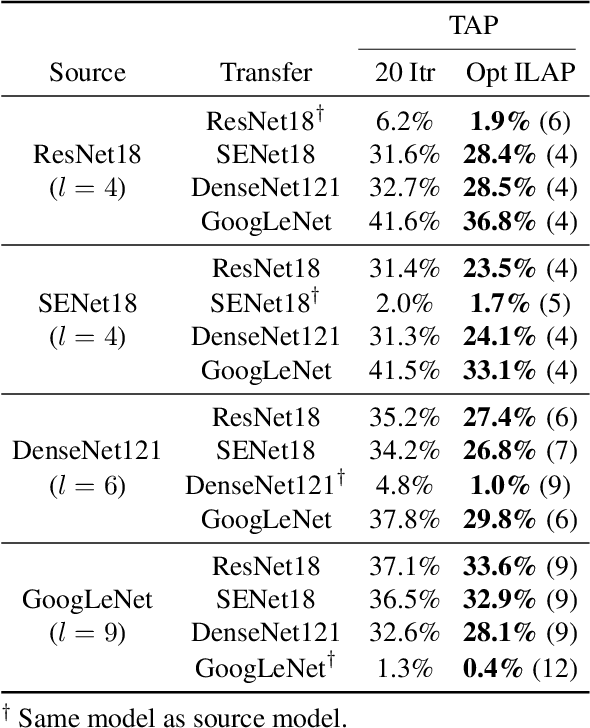
Neural networks are vulnerable to adversarial examples, malicious inputs crafted to fool trained models. Adversarial examples often exhibit black-box transfer, meaning that adversarial examples for one model can fool another model. However, adversarial examples are typically overfit to exploit the particular architecture and feature representation of a source model, resulting in sub-optimal black-box transfer attacks to other target models. We introduce the Intermediate Level Attack (ILA), which attempts to fine-tune an existing adversarial example for greater black-box transferability by increasing its perturbation on a pre-specified layer of the source model, improving upon state-of-the-art methods. We show that we can select a layer of the source model to perturb without any knowledge of the target models while achieving high transferability. Additionally, we provide some explanatory insights regarding our method and the effect of optimizing for adversarial examples in intermediate feature maps.
Intermediate Level Adversarial Attack for Enhanced Transferability
Nov 20, 2018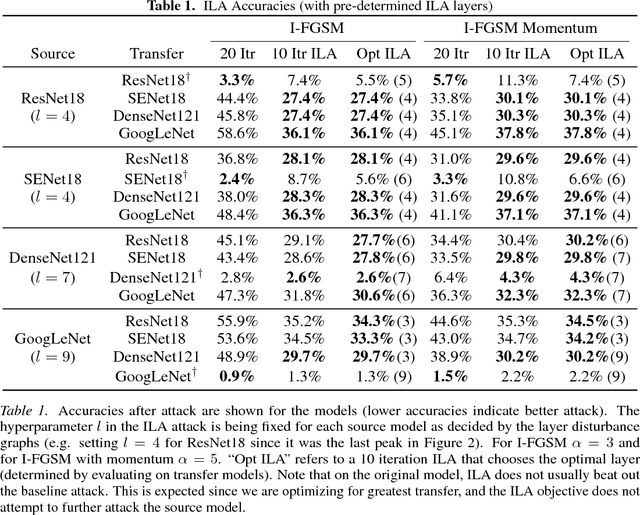
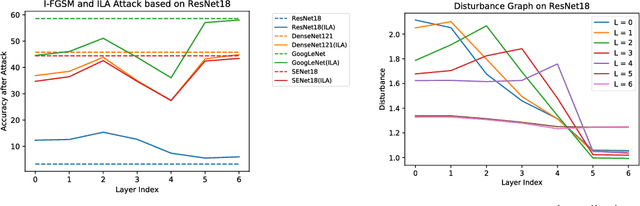
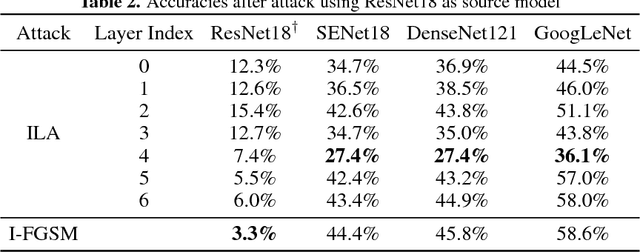
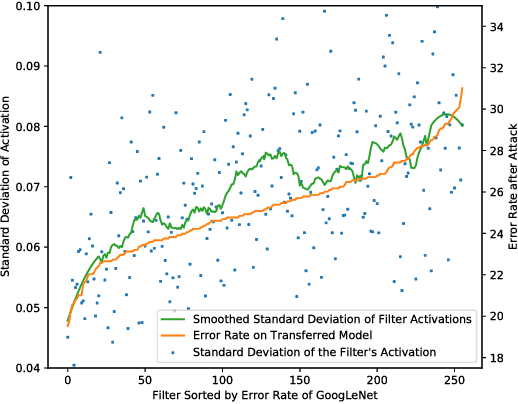
Neural networks are vulnerable to adversarial examples, malicious inputs crafted to fool trained models. Adversarial examples often exhibit black-box transfer, meaning that adversarial examples for one model can fool another model. However, adversarial examples may be overfit to exploit the particular architecture and feature representation of a source model, resulting in sub-optimal black-box transfer attacks to other target models. This leads us to introduce the Intermediate Level Attack (ILA), which attempts to fine-tune an existing adversarial example for greater black-box transferability by increasing its perturbation on a pre-specified layer of the source model. We show that our method can effectively achieve this goal and that we can decide a nearly-optimal layer of the source model to perturb without any knowledge of the target models.