 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Dimensional Constraint Framework for Evaluating and Improving Instruction Following in Large Language Models
May 12, 2025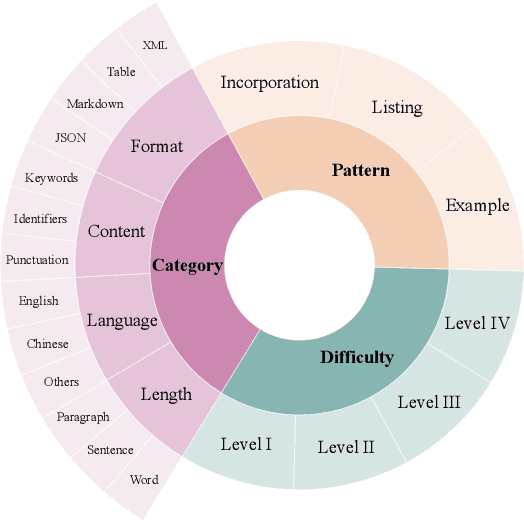

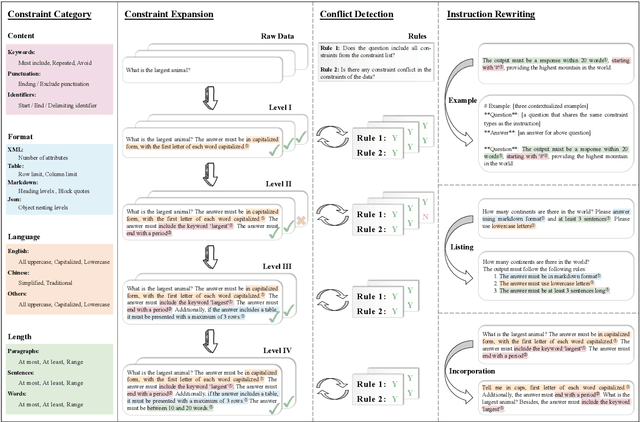
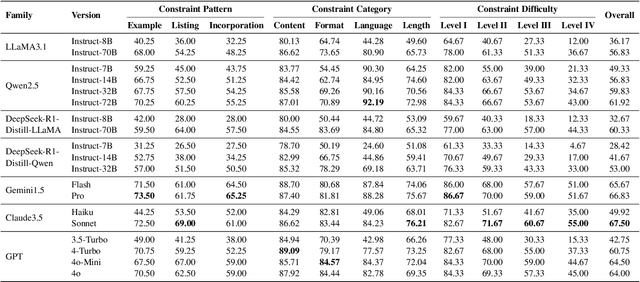
Instruction following evaluates large language models (LLMs) on their ability to generate outputs that adhere to user-defined constraints. However, existing benchmarks often rely on templated constraint prompts, which lack the diversity of real-world usage and limit fine-grained performance assessment. To fill this gap, we propose a multi-dimensional constraint framework encompassing three constraint patterns, four constraint categories, and four difficulty levels. Building on this framework, we develop an automated instruction generation pipeline that performs constraint expansion, conflict detection, and instruction rewriting, yielding 1,200 code-verifiable instruction-following test samples. We evaluate 19 LLMs across seven model families and uncover substantial variation in performance across constraint forms. For instance, average performance drops from 77.67% at Level I to 32.96% at Level IV. Furthermore, we demonstrate the utility of our approach by using it to generate data for reinforcement learning, achieving substantial gains in instruction following without degrading general performance. In-depth analysis indicates that these gains stem primarily from modifications in the model's attention modules parameters, which enhance constraint recognition and adherence. Code and data are available in https://github.com/Junjie-Ye/MulDimIF.
Have the VLMs Lost Confidence? A Study of Sycophancy in VLMs
Oct 15, 2024



In the study of LLMs, sycophancy represents a prevalent hallucination that poses significant challenges to these models. Specifically, LLMs often fail to adhere to original correct responses, instead blindly agreeing with users' opinions, even when those opinions are incorrect or malicious. However, research on sycophancy in visual language models (VLMs) has been scarce. In this work, we extend the exploration of sycophancy from LLMs to VLMs, introducing the MM-SY benchmark to evaluate this phenomenon. We present evaluation results from multiple representative models, addressing the gap in sycophancy research for VLMs. To mitigate sycophancy, we propose a synthetic dataset for training and employ methods based on prompts, supervised fine-tuning, and DPO. Our experiments demonstrate that these methods effectively alleviate sycophancy in VLMs. Additionally, we probe VLMs to assess the semantic impact of sycophancy and analyze the attention distribution of visual tokens. Our findings indicate that the ability to prevent sycophancy is predominantly observed in higher layers of the model. The lack of attention to image knowledge in these higher layers may contribute to sycophancy, and enhancing image attention at high layers proves beneficial in mitigating this issue.