 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Aware Local-Global Vision Transformer
Paper and Code
Nov 27, 2022
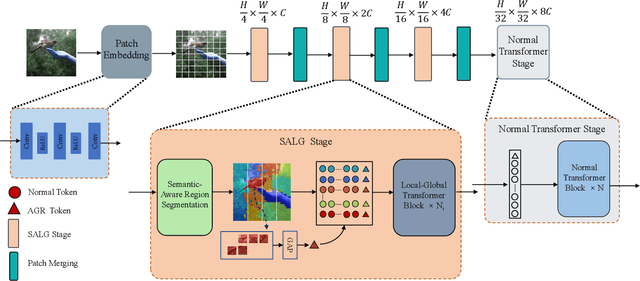
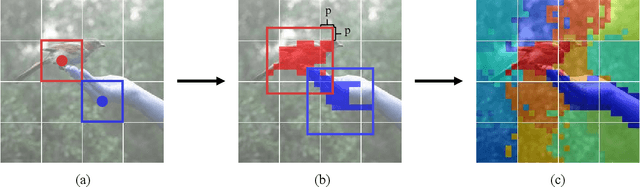

Vision Transformers have achieved remarkable progresses, among which Swin Transformer has demonstrated the tremendous potential of Transformer for vision tasks. It surmounts the key challenge of high computational complexity by performing local self-attention within shifted windows. In this work we propose the Semantic-Aware Local-Global Vision Transformer (SALG), to further investigate two potential improvements towards Swin Transformer. First, unlike Swin Transformer that performs uniform partition to produce equal size of regular windows for local self-attention, our SALG performs semantic segmentation in an unsupervised way to explore the underlying semantic priors in the image. As a result, each segmented region can correspond to a semantically meaningful part in the image, potentially leading to more effective features within each of segmented regions. Second, instead of only performing local self-attention within local windows as Swin Transformer does, the proposed SALG performs both 1) local intra-region self-attention for learning fine-grained features within each region and 2) global inter-region feature propagation for modeling global dependencies among all regions. Consequently, our model is able to obtain the global view when learning features for each token, which is the essential advantage of Transformer. Owing to the explicit modeling of the semantic priors and the proposed local-global modeling mechanism, our SALG is particularly advantageous for small-scale models when the modeling capacity is not sufficient for other models to learn semantics implicitly. Extensive experiments across various vision tasks demonstrates the merit of our model over other vision Transformers, especially in the small-scale modeling scenarios.