 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstaVSR: Taming Diffusion for Efficient and Temporally Consistent Video Super-Resolution
Mar 27, 2026Video super-resolution (VSR) seeks to reconstruct high-resolution frames from low-resolution inputs. While diffusion-based methods have substantially improved perceptual quality, extending them to video remains challenging for two reasons: strong generative priors can introduce temporal instability, and multi-frame diffusion pipelines are often too expensive for practical deployment. To address both challenges simultaneously, we propose InstaVSR, a lightweight diffusion framework for efficient video super-resolution. InstaVSR combines three ingredients: (1) a pruned one-step diffusion backbone that removes several costly components from conventional diffusion-based VSR pipelines, (2) recurrent training with flow-guided temporal regularization to improve frame-to-frame stability, and (3) dual-space adversarial learning in latent and pixel spaces to preserve perceptual quality after backbone simplification. On an NVIDIA RTX 4090, InstaVSR processes a 30-frame video at 2K$\times$2K resolution in under one minute with only 7 GB of memory usage, substantially reducing the computational cost compared to existing diffusion-based methods while maintaining favorable perceptual quality with significantly smoother temporal transitions.
Low-Altitude Agentic Networks for Optical Wireless Communication and Sensing: An Oceanic Scenario
Mar 04, 2026The cross-domain oceanic connectivity ranging from underwater to the sky has become increasingly indispensable for a plethora of data-consuming maritime applications, such as maritime meteorological monitoring and offshore exploration. However, broadband implementations can be severely hindered by the isolation from terrestrial networks, limited satellite resources, and the fundamental inability of radio waves to bridge the water-air interface at high rates. To this end, this paper introduces an optical network bridging underwater, air and near space, which features a number of cooperative low-altitude platforms (LAPs), serving as compute-capable, sensing-aware, and mission-adaptive agents. The network architecture consists of three scenario-specific segments, i.e., water-air direct link, low-altitude mesh network, and the near-space access network. With coordinate sensing and intelligent control, the system tightly couples beam tracking and resource optimization, enabling resilient networking under high mobility and harsh maritime dynamics. Furthermore, we review enabling technologies spanning from water-air channel modeling, adaptive beam alignment under sea-surface perturbations, to swarm-intelligence networking for decentralized control, integrated pose-topology planning, and optical Integrated sensing and communication (ISAC) for near-space target detection and beam alignment. Finally, open issues are also highlighted, constituting a clear roadmap toward scalable, secure, and ultra-broadband oceanic optical networks.
SynEVO: A neuro-inspired spatiotemporal evolutional framework for cross-domain adaptation
May 21, 2025Discovering regularities from spatiotemporal systems can benefit various scientific and social planning. Current spatiotemporal learners usually train an independent model from a specific source data that leads to limited transferability among sources, where even correlated tasks requires new design and training. The key towards increasing cross-domain knowledge is to enable collective intelligence and model evolution. In this paper, inspired by neuroscience theories, we theoretically derive the increased information boundary via learning cross-domain collective intelligence and propose a Synaptic EVOlutional spatiotemporal network, SynEVO, where SynEVO breaks the model independence and enables cross-domain knowledge to be shared and aggregated. Specifically, we first re-order the sample groups to imitate the human curriculum learning, and devise two complementary learners, elastic common container and task-independent extractor to allow model growth and task-wise commonality and personality disentanglement. Then an adaptive dynamic coupler with a new difference metric determines whether the new sample group should be incorporated into common container to achieve model evolution under various domains. Experiments show that SynEVO improves the generalization capacity by at most 42% under cross-domain scenarios and SynEVO provides a paradigm of NeuroAI for knowledge transfer and adaptation.
Beyond Pixels: Text Enhances Generalization in Real-World Image Restoration
Dec 01, 2024



Generalization has long been a central challenge in real-world image restoration. While recent diffusion-based restoration methods, which leverage generative priors from text-to-image models, have made progress in recovering more realistic details, they still encounter "generative capability deactivation" when applied to out-of-distribution real-world data. To address this, we propose using text as an auxiliary invariant representation to reactivate the generative capabilities of these models. We begin by identifying two key properties of text input: richness and relevance, and examine their respective influence on model performance. Building on these insights, we introduce Res-Captioner, a module that generates enhanced textual descriptions tailored to image content and degradation levels, effectively mitigating response failures. Additionally, we present RealIR, a new benchmark designed to capture diverse real-world scenarios. Extensive experiments demonstrate that Res-Captioner significantly enhances the generalization abilities of diffusion-based restoration models, while remaining fully plug-and-play.
SAGA: Surface-Aligned Gaussian Avatar
Dec 01, 2024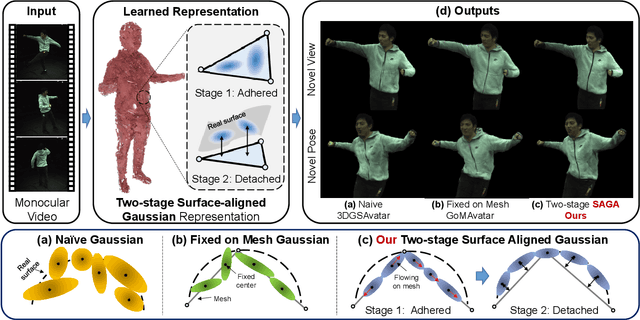

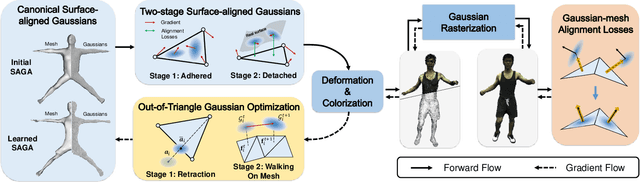
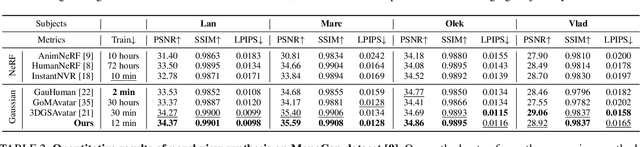
This paper presents a Surface-Aligned Gaussian representation for creating animatable human avatars from monocular videos,aiming at improving the novel view and pose synthesis performance while ensuring fast training and real-time rendering. Recently,3DGS has emerged as a more efficient and expressive alternative to NeRF, and has been used for creating dynamic human avatars. However,when applied to the severely ill-posed task of monocular dynamic reconstruction, the Gaussians tend to overfit the constantly changing regions such as clothes wrinkles or shadows since these regions cannot provide consistent supervision, resulting in noisy geometry and abrupt deformation that typically fail to generalize under novel views and poses.To address these limitations, we present SAGA,i.e.,Surface-Aligned Gaussian Avatar,which aligns the Gaussians with a mesh to enforce well-defined geometry and consistent deformation, thereby improving generalization under novel views and poses. Unlike existing strict alignment methods that suffer from limited expressive power and low realism,SAGA employs a two-stage alignment strategy where the Gaussians are first adhered on while then detached from the mesh, thus facilitating both good geometry and high expressivity. In the Adhered Stage, we improve the flexibility of Adhered-on-Mesh Gaussians by allowing them to flow on the mesh, in contrast to existing methods that rigidly bind Gaussians to fixed location. In the second Detached Stage, we introduce a Gaussian-Mesh Alignment regularization, which allows us to unleash the expressivity by detaching the Gaussians but maintain the geometric alignment by minimizing their location and orientation offsets from the bound triangles. Finally, since the Gaussians may drift outside the bound triangles during optimization, an efficient Walking-on-Mesh strategy is proposed to dynamically update the bound triangles.
Reinforcement-Learning-Enabled Beam Alignment for Water-Air Direct Optical Wireless Communications
Sep 05, 2024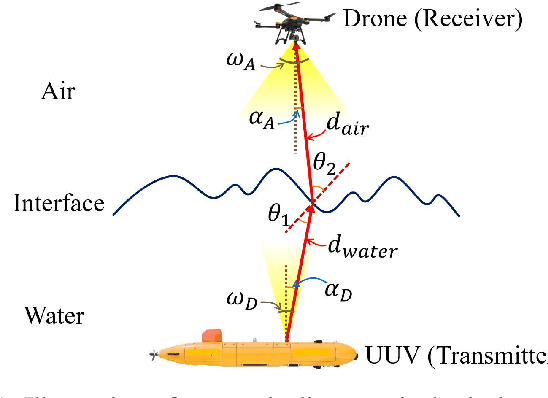
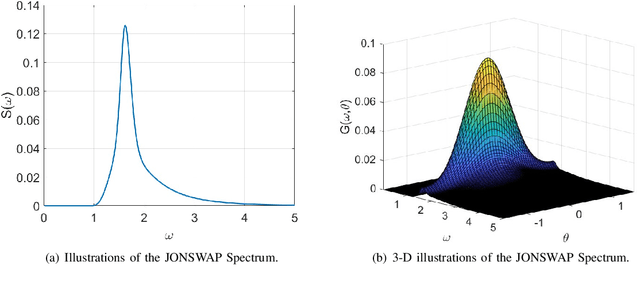
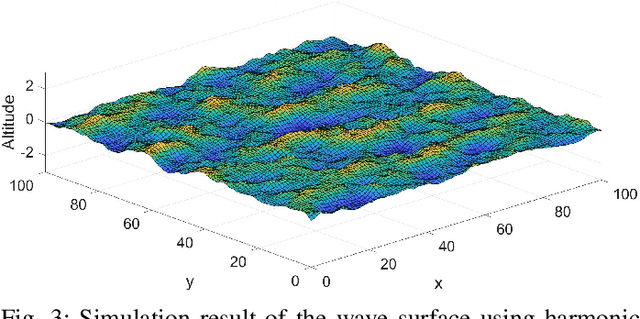
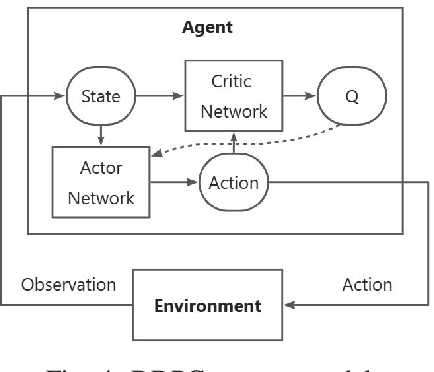
The escalating interests on underwater exploration/reconnaissance applications have motivated high-rate data transmission from underwater to airborne relaying platforms, especially under high-sea scenarios. Thanks to its broad bandwidth and superior confidentiality, Optical wireless communication has become one promising candidate for water-air transmission. However, the optical signals inevitably suffer from deviations when crossing the highly-dynamic water-air interfaces in the absence of relaying ships/buoys. To address the issue, this article proposes one novel beam alignment strategy based on deep reinforcement learning (DRL) for water-air direct optical wireless communications. Specifically, the dynamic water-air interface is mathematically modeled using sea-wave spectrum analysis, followed by characterization of the propagation channel with ray-tracing techniques. Then the deep deterministic policy gradient (DDPG) scheme is introduced for DRL-based transceiving beam alignment. A logarithm-exponential (LE) nonlinear reward function with respect to the received signal strength is designed for high-resolution rewarding between different actions. Simulation results validate the superiority of the proposed DRL-based beam alignment scheme.
MirrorGaussian: Reflecting 3D Gaussians for Reconstructing Mirror Reflections
May 20, 2024



3D Gaussian Splatting showcases notable advancements in photo-realistic and real-time novel view synthesis. However, it faces challenges in modeling mirror reflections, which exhibit substantial appearance variations from different viewpoints. To tackle this problem, we present MirrorGaussian, the first method for mirror scene reconstruction with real-time rendering based on 3D Gaussian Splatting. The key insight is grounded on the mirror symmetry between the real-world space and the virtual mirror space. We introduce an intuitive dual-rendering strategy that enables differentiable rasterization of both the real-world 3D Gaussians and the mirrored counterpart obtained by reflecting the former about the mirror plane. All 3D Gaussians are jointly optimized with the mirror plane in an end-to-end framework. MirrorGaussian achieves high-quality and real-time rendering in scenes with mirrors, empowering scene editing like adding new mirrors and objects. Comprehensive experiments on multiple datasets demonstrate that our approach significantly outperforms existing methods, achieving state-of-the-art results. Project page: https://mirror-gaussian.github.io/.
VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction
Feb 27, 2024



Existing NeRF-based methods for large scene reconstruction often have limitations in visual quality and rendering speed. While the recent 3D Gaussian Splatting works well on small-scale and object-centric scenes, scaling it up to large scenes poses challenges due to limited video memory, long optimization time, and noticeable appearance variations. To address these challenges, we present VastGaussian, the first method for high-quality reconstruction and real-time rendering on large scenes based on 3D Gaussian Splatting. We propose a progressive partitioning strategy to divide a large scene into multiple cells, where the training cameras and point cloud are properly distributed with an airspace-aware visibility criterion. These cells are merged into a complete scene after parallel optimization. We also introduce decoupled appearance modeling into the optimization process to reduce appearance variations in the rendered images. Our approach outperforms existing NeRF-based methods and achieves state-of-the-art results on multiple large scene datasets, enabling fast optimization and high-fidelity real-time rendering.
ITstyler: Image-optimized Text-based Style Transfer
Jan 26, 2023



Text-based style transfer is a newly-emerging research topic that uses text information instead of style image to guide the transfer process, significantly extending the application scenario of style transfer. However, previous methods require extra time for optimization or text-image paired data, leading to limited effectiveness. In this work, we achieve a data-efficient text-based style transfer method that does not require optimization at the inference stage. Specifically, we convert text input to the style space of the pre-trained VGG network to realize a more effective style swap. We also leverage CLIP's multi-modal embedding space to learn the text-to-style mapping with the image dataset only. Our method can transfer arbitrary new styles of text input in real-time and synthesize high-quality artistic images.