 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Noisy Ground Truth: From 2D Classification to 3D Reconstruction
Jun 23, 2024



Deep neural networks has been highly successful in data-intense computer vision applications, while such success relies heavily on the massive and clean data. In real-world scenarios, clean data sometimes is difficult to obtain. For example, in image classification and segmentation tasks, precise annotations of millions samples are generally very expensive and time-consuming. In 3D static scene reconstruction task, most NeRF related methods require the foundational assumption of the static scene (e.g. consistent lighting condition and persistent object positions), which is often violated in real-world scenarios. To address these problem, learning with noisy ground truth (LNGT) has emerged as an effective learning method and shows great potential. In this short survey, we propose a formal definition unify the analysis of LNGT LNGT in the context of different machine learning tasks (classification and regression). Based on this definition, we propose a novel taxonomy to classify the existing work according to the error decomposition with the fundamental definition of machine learning. Further, we provide in-depth analysis on memorization effect and insightful discussion about potential future research opportunities from 2D classification to 3D reconstruction, in the hope of providing guidance to follow-up research.
Mitigating Noisy Supervision Using Synthetic Samples with Soft Labels
Jun 22, 2024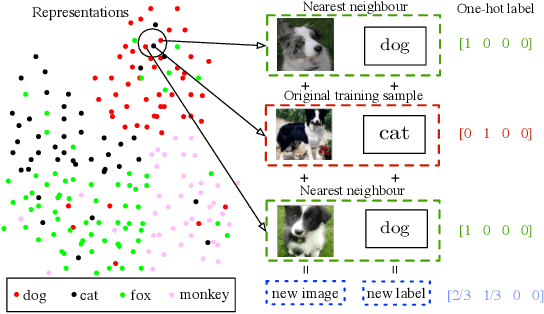
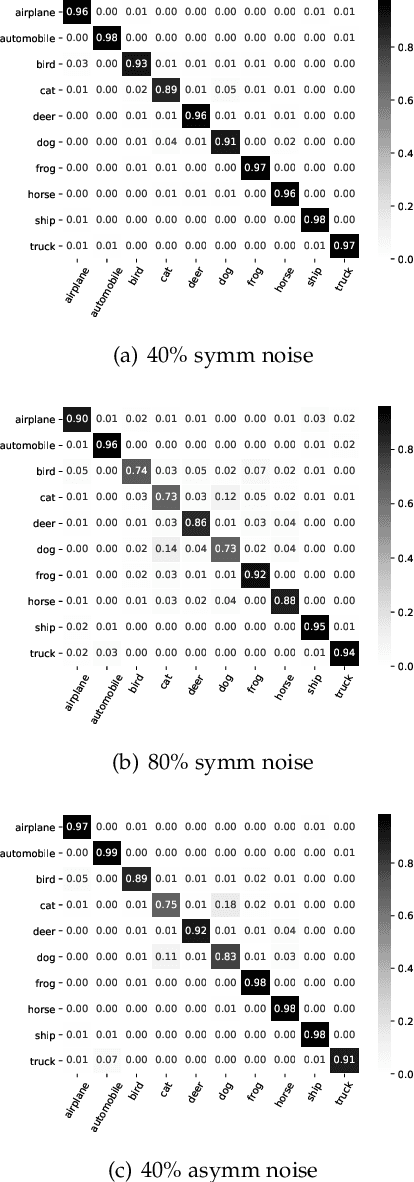

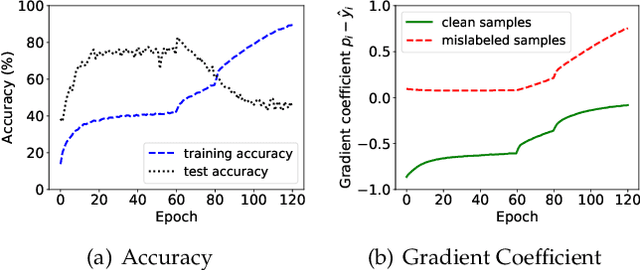
Noisy labels are ubiquitous in real-world datasets, especially in the large-scale ones derived from crowdsourcing and web searching. It is challenging to train deep neural networks with noisy datasets since the networks are prone to overfitting the noisy labels during training, resulting in poor generalization performance. During an early learning phase, deep neural networks have been observed to fit the clean samples before memorizing the mislabeled samples. In this paper, we dig deeper into the representation distributions in the early learning phase and find that, regardless of their noisy labels, learned representations of images from the same category still congregate together. Inspired by it, we propose a framework that trains the model with new synthetic samples to mitigate the impact of noisy labels. Specifically, we propose a mixing strategy to create the synthetic samples by aggregating original samples with their top-K nearest neighbours, wherein the weights are calculated using a mixture model learning from the per-sample loss distribution. To enhance the performance in the presence of extreme label noise, we estimate the soft targets by gradually correcting the noisy labels. Furthermore, we demonstrate that the estimated soft targets yield a more accurate approximation to ground truth labels and the proposed method produces a superior quality of learned representations with more separated and clearly bounded clusters. The extensive experiments in two benchmarks (CIFAR-10 and CIFAR-100) and two larg-scale real-world datasets (Clothing1M and Webvision) demonstrate that our approach outperforms the state-of-the-art methods and robustness of the learned representation.
VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction
Feb 27, 2024Existing NeRF-based methods for large scene reconstruction often have limitations in visual quality and rendering speed. While the recent 3D Gaussian Splatting works well on small-scale and object-centric scenes, scaling it up to large scenes poses challenges due to limited video memory, long optimization time, and noticeable appearance variations. To address these challenges, we present VastGaussian, the first method for high-quality reconstruction and real-time rendering on large scenes based on 3D Gaussian Splatting. We propose a progressive partitioning strategy to divide a large scene into multiple cells, where the training cameras and point cloud are properly distributed with an airspace-aware visibility criterion. These cells are merged into a complete scene after parallel optimization. We also introduce decoupled appearance modeling into the optimization process to reduce appearance variations in the rendered images. Our approach outperforms existing NeRF-based methods and achieves state-of-the-art results on multiple large scene datasets, enabling fast optimization and high-fidelity real-time rendering.
SELC: Self-Ensemble Label Correction Improves Learning with Noisy Labels
May 02, 2022
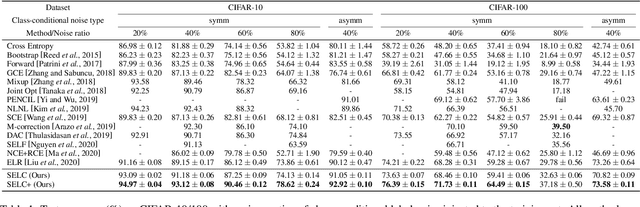
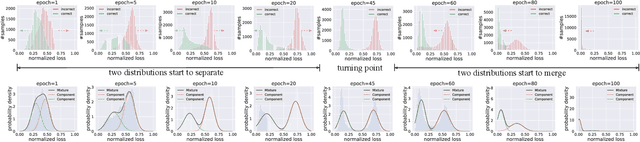
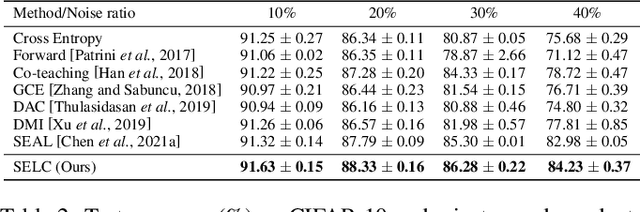
Deep neural networks are prone to overfitting noisy labels, resulting in poor generalization performance. To overcome this problem, we present a simple and effective method self-ensemble label correction (SELC) to progressively correct noisy labels and refine the model. We look deeper into the memorization behavior in training with noisy labels and observe that the network outputs are reliable in the early stage. To retain this reliable knowledge, SELC uses ensemble predictions formed by an exponential moving average of network outputs to update the original noisy labels. We show that training with SELC refines the model by gradually reducing supervision from noisy labels and increasing supervision from ensemble predictions. Despite its simplicity, compared with many state-of-the-art methods, SELC obtains more promising and stable results in the presence of class-conditional, instance-dependent, and real-world label noise. The code is available at https://github.com/MacLLL/SELC.
Confidence Adaptive Regularization for Deep Learning with Noisy Labels
Sep 05, 2021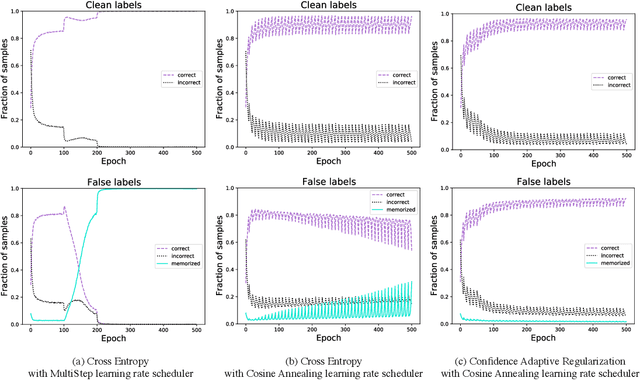

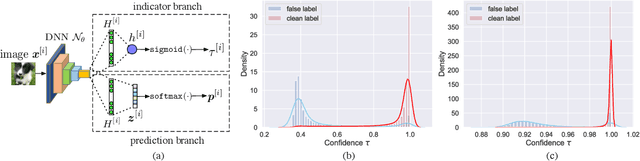
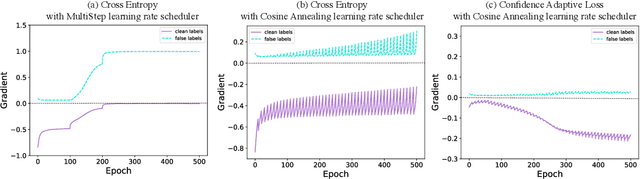
Recent studies on the memorization effects of deep neural networks on noisy labels show that the networks first fit the correctly-labeled training samples before memorizing the mislabeled samples. Motivated by this early-learning phenomenon, we propose a novel method to prevent memorization of the mislabeled samples. Unlike the existing approaches which use the model output to identify or ignore the mislabeled samples, we introduce an indicator branch to the original model and enable the model to produce a confidence value for each sample. The confidence values are incorporated in our loss function which is learned to assign large confidence values to correctly-labeled samples and small confidence values to mislabeled samples. We also propose an auxiliary regularization term to further improve the robustness of the model. To improve the performance, we gradually correct the noisy labels with a well-designed target estimation strategy. We provide the theoretical analysis and conduct the experiments on synthetic and real-world datasets, demonstrating that our approach achieves comparable results to the state-of-the-art methods.
Co-matching: Combating Noisy Labels by Augmentation Anchoring
Mar 23, 2021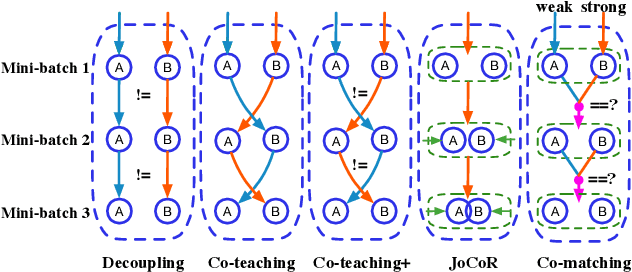
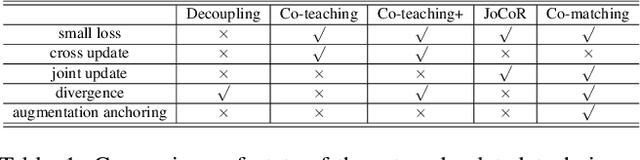
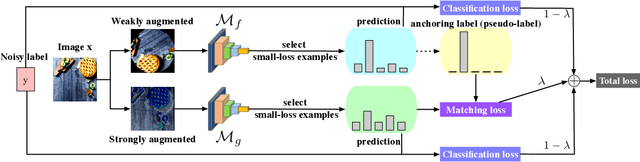

Deep learning with noisy labels is challenging as deep neural networks have the high capacity to memorize the noisy labels. In this paper, we propose a learning algorithm called Co-matching, which balances the consistency and divergence between two networks by augmentation anchoring. Specifically, we have one network generate anchoring label from its prediction on a weakly-augmented image. Meanwhile, we force its peer network, taking the strongly-augmented version of the same image as input, to generate prediction close to the anchoring label. We then update two networks simultaneously by selecting small-loss instances to minimize both unsupervised matching loss (i.e., measure the consistency of the two networks) and supervised classification loss (i.e. measure the classification performance). Besides, the unsupervised matching loss makes our method not heavily rely on noisy labels, which prevents memorization of noisy labels. Experiments on three benchmark datasets demonstrate that Co-matching achieves results comparable to the state-of-the-art methods.
CLTA: Contents and Length-based Temporal Attention for Few-shot Action Recognition
Mar 18, 2021
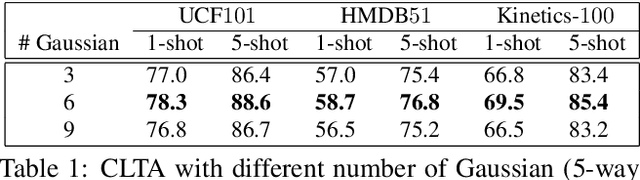


Few-shot action recognition has attracted increasing attention due to the difficulty in acquiring the properly labelled training samples. Current works have shown that preserving spatial information and comparing video descriptors are crucial for few-shot action recognition. However, the importance of preserving temporal information is not well discussed. In this paper, we propose a Contents and Length-based Temporal Attention (CLTA) model, which learns customized temporal attention for the individual video to tackle the few-shot action recognition problem. CLTA utilizes the Gaussian likelihood function as the template to generate temporal attention and trains the learning matrices to study the mean and standard deviation based on both frame contents and length. We show that even a not fine-tuned backbone with an ordinary softmax classifier can still achieve similar or better results compared to the state-of-the-art few-shot action recognition with precisely captured temporal attention.