 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Noisy Supervision Using Synthetic Samples with Soft Labels
Paper and Code
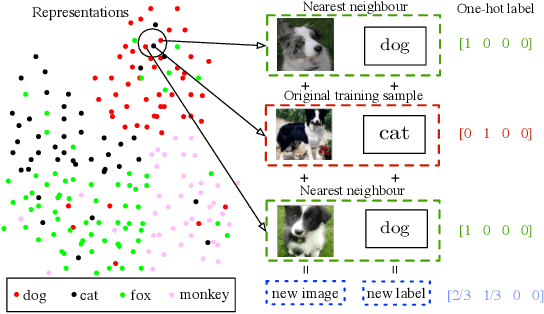
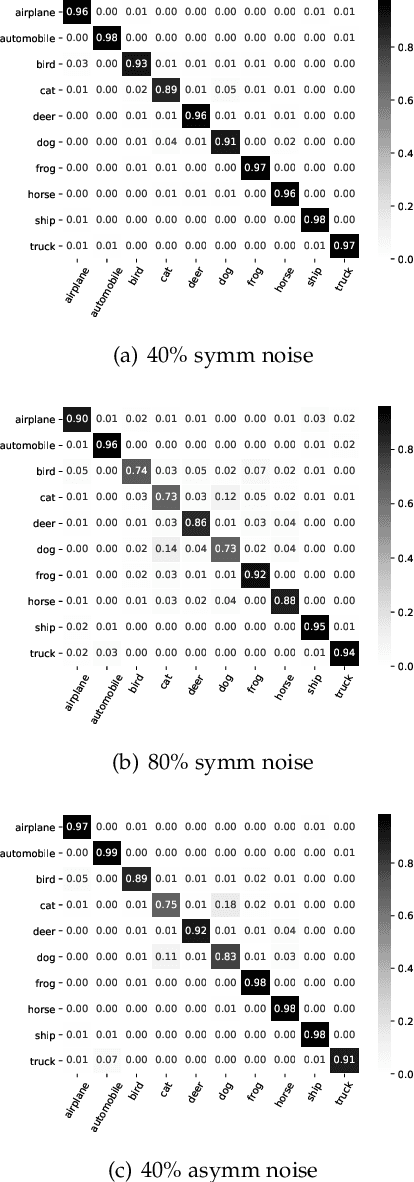

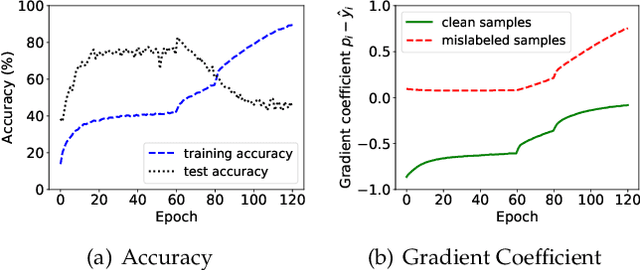
Noisy labels are ubiquitous in real-world datasets, especially in the large-scale ones derived from crowdsourcing and web searching. It is challenging to train deep neural networks with noisy datasets since the networks are prone to overfitting the noisy labels during training, resulting in poor generalization performance. During an early learning phase, deep neural networks have been observed to fit the clean samples before memorizing the mislabeled samples. In this paper, we dig deeper into the representation distributions in the early learning phase and find that, regardless of their noisy labels, learned representations of images from the same category still congregate together. Inspired by it, we propose a framework that trains the model with new synthetic samples to mitigate the impact of noisy labels. Specifically, we propose a mixing strategy to create the synthetic samples by aggregating original samples with their top-K nearest neighbours, wherein the weights are calculated using a mixture model learning from the per-sample loss distribution. To enhance the performance in the presence of extreme label noise, we estimate the soft targets by gradually correcting the noisy labels. Furthermore, we demonstrate that the estimated soft targets yield a more accurate approximation to ground truth labels and the proposed method produces a superior quality of learned representations with more separated and clearly bounded clusters. The extensive experiments in two benchmarks (CIFAR-10 and CIFAR-100) and two larg-scale real-world datasets (Clothing1M and Webvision) demonstrate that our approach outperforms the state-of-the-art methods and robustness of the learned representation.