 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement-Learning-Enabled Beam Alignment for Water-Air Direct Optical Wireless Communications
Sep 05, 2024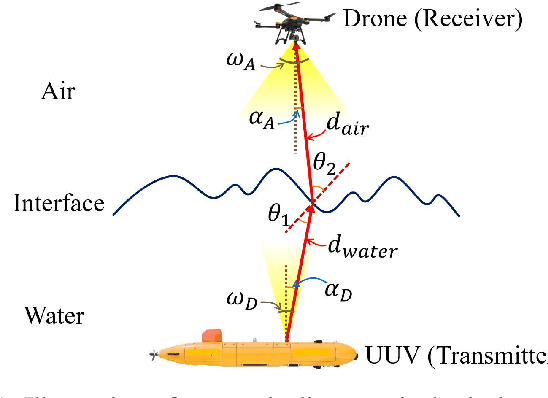
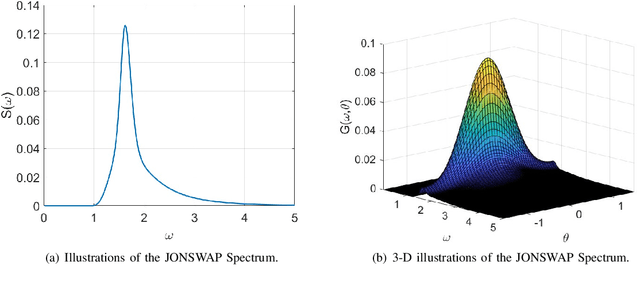
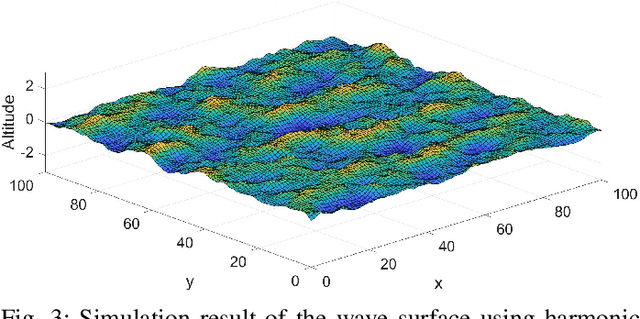
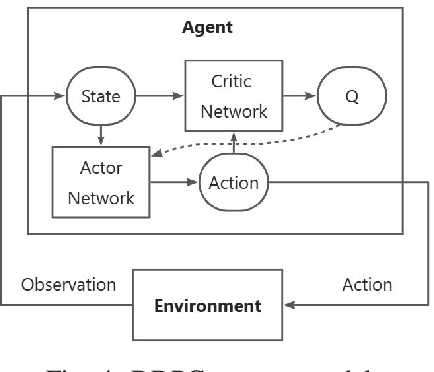
The escalating interests on underwater exploration/reconnaissance applications have motivated high-rate data transmission from underwater to airborne relaying platforms, especially under high-sea scenarios. Thanks to its broad bandwidth and superior confidentiality, Optical wireless communication has become one promising candidate for water-air transmission. However, the optical signals inevitably suffer from deviations when crossing the highly-dynamic water-air interfaces in the absence of relaying ships/buoys. To address the issue, this article proposes one novel beam alignment strategy based on deep reinforcement learning (DRL) for water-air direct optical wireless communications. Specifically, the dynamic water-air interface is mathematically modeled using sea-wave spectrum analysis, followed by characterization of the propagation channel with ray-tracing techniques. Then the deep deterministic policy gradient (DDPG) scheme is introduced for DRL-based transceiving beam alignment. A logarithm-exponential (LE) nonlinear reward function with respect to the received signal strength is designed for high-resolution rewarding between different actions. Simulation results validate the superiority of the proposed DRL-based beam alignment scheme.
Deep Learning Assisted Calibrated Beam Training for Millimeter-Wave Communication Systems
Jan 22, 2021

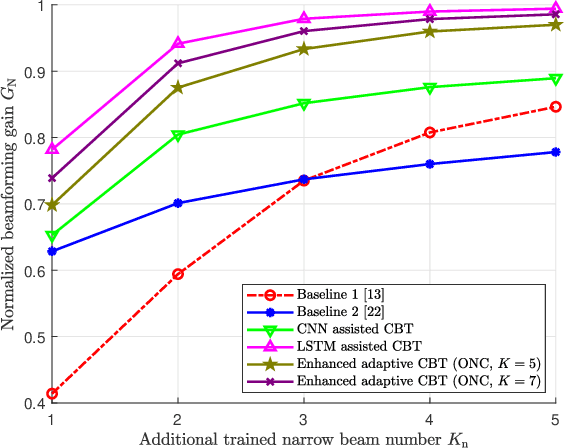

Huge overhead of beam training imposes a significant challenge in millimeter-wave (mmWave) wireless communications. To address this issue, in this paper, we propose a wide beam based training approach to calibrate the narrow beam direction according to the channel power leakage. To handle the complex nonlinear properties of the channel power leakage, deep learning is utilized to predict the optimal narrow beam directly. Specifically, three deep learning assisted calibrated beam training schemes are proposed. The first scheme adopts convolution neural network to implement the prediction based on the instantaneous received signals of wide beam training. We also perform the additional narrow beam training based on the predicted probabilities for further beam direction calibrations. The second scheme adopts long-short term memory (LSTM) network for tracking the movement of users and calibrating the beam direction according to the received signals of prior beam training, in order to enhance the robustness to noise. To further reduce the overhead of wide beam training, our third scheme, an adaptive beam training strategy, selects partial wide beams to be trained based on the prior received signals. Two criteria, namely, optimal neighboring criterion and maximum probability criterion, are designed for the selection. Furthermore, to handle mobile scenarios, auxiliary LSTM is introduced to calibrate the directions of the selected wide beams more precisely. Simulation results demonstrate that our proposed schemes achieve significantly higher beamforming gain with smaller beam training overhead compared with the conventional and existing deep-learning based counterparts.