 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadiometrically Consistent Gaussian Surfels for Inverse Rendering
Mar 02, 2026Inverse rendering with Gaussian Splatting has advanced rapidly, but accurately disentangling material properties from complex global illumination effects, particularly indirect illumination, remains a major challenge. Existing methods often query indirect radiance from Gaussian primitives pre-trained for novel-view synthesis. However, these pre-trained Gaussian primitives are supervised only towards limited training viewpoints, thus lack supervision for modeling indirect radiances from unobserved views. To address this issue, we introduce radiometric consistency, a novel physically-based constraint that provides supervision towards unobserved views by minimizing the residual between each Gaussian primitive's learned radiance and its physically-based rendered counterpart. Minimizing the residual for unobserved views establishes a self-correcting feedback loop that provides supervision from both physically-based rendering and novel-view synthesis, enabling accurate modeling of inter-reflection. We then propose Radiometrically Consistent Gaussian Surfels (RadioGS), an inverse rendering framework built upon our principle by efficiently integrating radiometric consistency by utilizing Gaussian surfels and 2D Gaussian ray tracing. We further propose a finetuning-based relighting strategy that adapts Gaussian surfel radiances to new illuminations within minutes, achieving low rendering cost (<10ms). Extensive experiments on existing inverse rendering benchmarks show that RadioGS outperforms existing Gaussian-based methods in inverse rendering, while retaining the computational efficiency.
Pose-free 3D Gaussian splatting via shape-ray estimation
May 29, 2025



While generalizable 3D Gaussian splatting enables efficient, high-quality rendering of unseen scenes, it heavily depends on precise camera poses for accurate geometry. In real-world scenarios, obtaining accurate poses is challenging, leading to noisy pose estimates and geometric misalignments. To address this, we introduce SHARE, a pose-free, feed-forward Gaussian splatting framework that overcomes these ambiguities by joint shape and camera rays estimation. Instead of relying on explicit 3D transformations, SHARE builds a pose-aware canonical volume representation that seamlessly integrates multi-view information, reducing misalignment caused by inaccurate pose estimates. Additionally, anchor-aligned Gaussian prediction enhances scene reconstruction by refining local geometry around coarse anchors, allowing for more precise Gaussian placement. Extensive experiments on diverse real-world datasets show that our method achieves robust performance in pose-free generalizable Gaussian splatting.
UFORecon: Generalizable Sparse-View Surface Reconstruction from Arbitrary and UnFavOrable Sets
Mar 11, 2024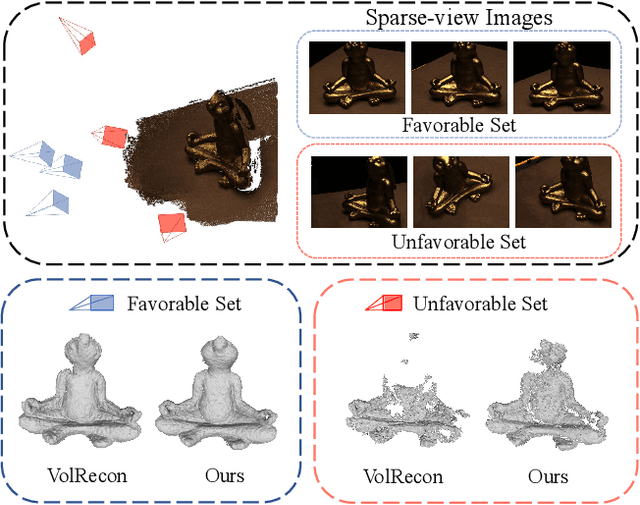
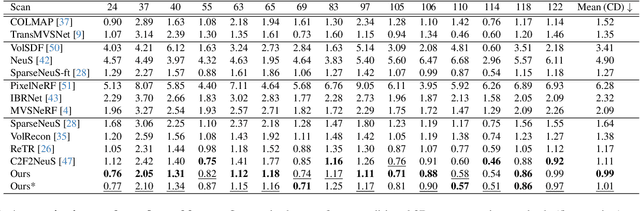
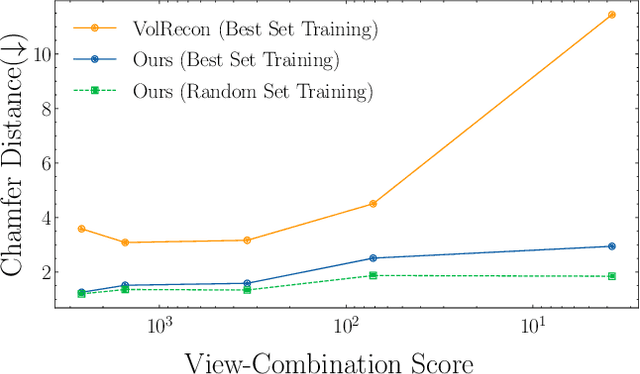

Generalizable neural implicit surface reconstruction aims to obtain an accurate underlying geometry given a limited number of multi-view images from unseen scenes. However, existing methods select only informative and relevant views using predefined scores for training and testing phases. This constraint renders the model impractical in real-world scenarios, where the availability of favorable combinations cannot always be ensured. We introduce and validate a view-combination score to indicate the effectiveness of the input view combination. We observe that previous methods output degenerate solutions under arbitrary and unfavorable sets. Building upon this finding, we propose UFORecon, a robust view-combination generalizable surface reconstruction framework. To achieve this, we apply cross-view matching transformers to model interactions between source images and build correlation frustums to capture global correlations. Additionally, we explicitly encode pairwise feature similarities as view-consistent priors. Our proposed framework significantly outperforms previous methods in terms of view-combination generalizability and also in the conventional generalizable protocol trained with favorable view-combinations. The code is available at https://github.com/Youngju-Na/UFORecon.
Pixel-wise Guidance for Utilizing Auxiliary Features in Monte Carlo Denoising
Apr 11, 2023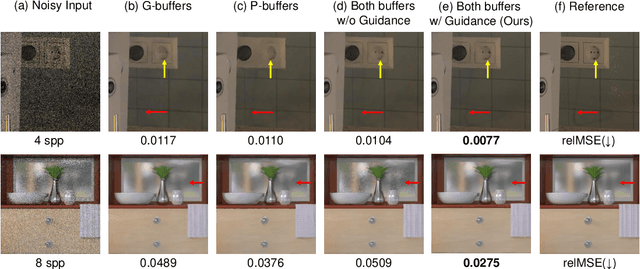

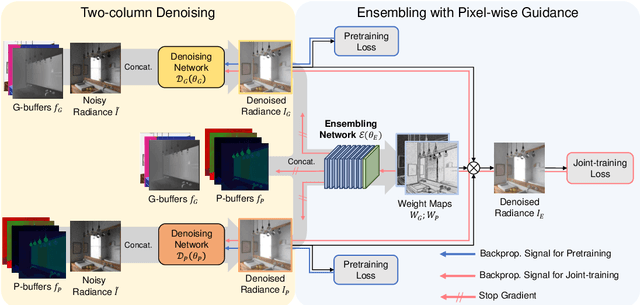

Auxiliary features such as geometric buffers (G-buffers) and path descriptors (P-buffers) have been shown to significantly improve Monte Carlo (MC) denoising. However, recent approaches implicitly learn to exploit auxiliary features for denoising, which could lead to insufficient utilization of each type of auxiliary features. To overcome such an issue, we propose a denoising framework that relies on an explicit pixel-wise guidance for utilizing auxiliary features. First, we train two denoisers, each trained by a different auxiliary feature (i.e., G-buffers or P-buffers). Then we design our ensembling network to obtain per-pixel ensembling weight maps, which represent pixel-wise guidance for which auxiliary feature should be dominant at reconstructing each individual pixel and use them to ensemble the two denoised results of our denosiers. We also propagate our pixel-wise guidance to the denoisers by jointly training the denoisers and the ensembling network, further guiding the denoisers to focus on regions where G-buffers or P-buffers are relatively important for denoising. Our result and show considerable improvement in denoising performance compared to the baseline denoising model using both G-buffers and P-buffers.