 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating Generative Recommendation via Simple Categorical User Sequence Compression
Jan 27, 2026Although generative recommenders demonstrate improved performance with longer sequences, their real-time deployment is hindered by substantial computational costs. To address this challenge, we propose a simple yet effective method for compressing long-term user histories by leveraging inherent item categorical features, thereby preserving user interests while enhancing efficiency. Experiments on two large-scale datasets demonstrate that, compared to the influential HSTU model, our approach achieves up to a 6x reduction in computational cost and up to 39% higher accuracy at comparable cost (i.e., similar sequence length).
PFAvatar: Pose-Fusion 3D Personalized Avatar Reconstruction from Real-World Outfit-of-the-Day Photos
Nov 18, 2025We propose PFAvatar (Pose-Fusion Avatar), a new method that reconstructs high-quality 3D avatars from Outfit of the Day(OOTD) photos, which exhibit diverse poses, occlusions, and complex backgrounds. Our method consists of two stages: (1) fine-tuning a pose-aware diffusion model from few-shot OOTD examples and (2) distilling a 3D avatar represented by a neural radiance field (NeRF). In the first stage, unlike previous methods that segment images into assets (e.g., garments, accessories) for 3D assembly, which is prone to inconsistency, we avoid decomposition and directly model the full-body appearance. By integrating a pre-trained ControlNet for pose estimation and a novel Condition Prior Preservation Loss (CPPL), our method enables end-to-end learning of fine details while mitigating language drift in few-shot training. Our method completes personalization in just 5 minutes, achieving a 48x speed-up compared to previous approaches. In the second stage, we introduce a NeRF-based avatar representation optimized by canonical SMPL-X space sampling and Multi-Resolution 3D-SDS. Compared to mesh-based representations that suffer from resolution-dependent discretization and erroneous occluded geometry, our continuous radiance field can preserve high-frequency textures (e.g., hair) and handle occlusions correctly through transmittance. Experiments demonstrate that PFAvatar outperforms state-of-the-art methods in terms of reconstruction fidelity, detail preservation, and robustness to occlusions/truncations, advancing practical 3D avatar generation from real-world OOTD albums. In addition, the reconstructed 3D avatar supports downstream applications such as virtual try-on, animation, and human video reenactment, further demonstrating the versatility and practical value of our approach.
OpenSlot: Mixed Open-set Recognition with Object-centric Learning
Jul 02, 2024



Existing open-set recognition (OSR) studies typically assume that each image contains only one class label, and the unknown test set (negative) has a disjoint label space from the known test set (positive), a scenario termed full-label shift. This paper introduces the mixed OSR problem, where test images contain multiple class semantics, with known and unknown classes co-occurring in negatives, leading to a more challenging super-label shift. Addressing the mixed OSR requires classification models to accurately distinguish different class semantics within images and measure their "knowness". In this study, we propose the OpenSlot framework, built upon object-centric learning. OpenSlot utilizes slot features to represent diverse class semantics and produce class predictions. Through our proposed anti-noise-slot (ANS) technique, we mitigate the impact of noise (invalid and background) slots during classification training, effectively addressing the semantic misalignment between class predictions and the ground truth. We conduct extensive experiments with OpenSlot on mixed & conventional OSR benchmarks. Without elaborate designs, OpenSlot not only exceeds existing OSR studies in detecting super-label shifts across single & multi-label mixed OSR tasks but also achieves state-of-the-art performance on conventional benchmarks. Remarkably, our method can localize class objects without using bounding boxes during training. The competitive performance in open-set object detection demonstrates OpenSlot's ability to explicitly explain label shifts and benefits in computational efficiency and generalization.
Accurate and Fast Pixel Retrieval with Spatial and Uncertainty Aware Hypergraph Diffusion
Jun 17, 2024This paper presents a novel method designed to enhance the efficiency and accuracy of both image retrieval and pixel retrieval. Traditional diffusion methods struggle to propagate spatial information effectively in conventional graphs due to their reliance on scalar edge weights. To overcome this limitation, we introduce a hypergraph-based framework, uniquely capable of efficiently propagating spatial information using local features during query time, thereby accurately retrieving and localizing objects within a database. Additionally, we innovatively utilize the structural information of the image graph through a technique we term "community selection". This approach allows for the assessment of the initial search result's uncertainty and facilitates an optimal balance between accuracy and speed. This is particularly crucial in real-world applications where such trade-offs are often necessary. Our experimental results, conducted on the (P)ROxford and (P)RParis datasets, demonstrate the significant superiority of our method over existing diffusion techniques. We achieve state-of-the-art (SOTA) accuracy in both image-level and pixel-level retrieval, while also maintaining impressive processing speed. This dual achievement underscores the effectiveness of our hypergraph-based framework and community selection technique, marking a notable advancement in the field of content-based image retrieval.
Topological RANSAC for instance verification and retrieval without fine-tuning
Oct 10, 2023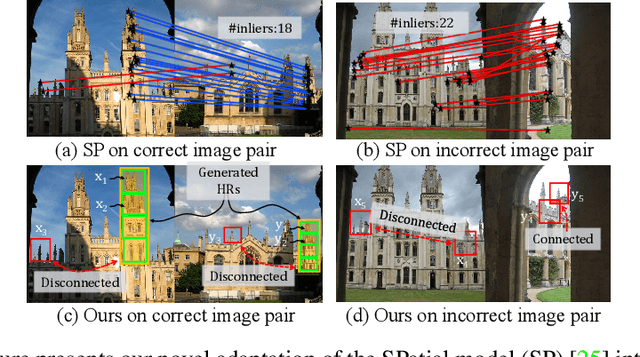
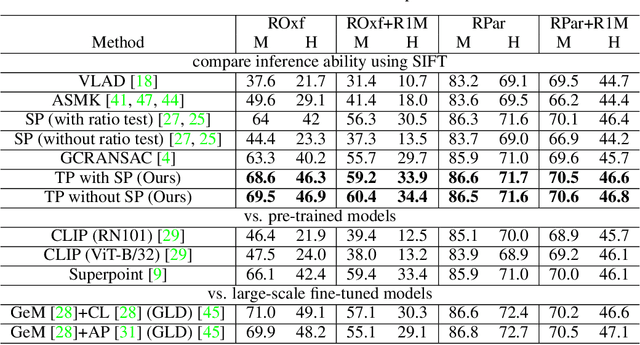
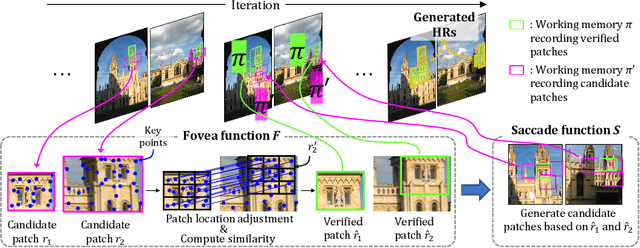

This paper presents an innovative approach to enhancing explainable image retrieval, particularly in situations where a fine-tuning set is unavailable. The widely-used SPatial verification (SP) method, despite its efficacy, relies on a spatial model and the hypothesis-testing strategy for instance recognition, leading to inherent limitations, including the assumption of planar structures and neglect of topological relations among features. To address these shortcomings, we introduce a pioneering technique that replaces the spatial model with a topological one within the RANSAC process. We propose bio-inspired saccade and fovea functions to verify the topological consistency among features, effectively circumventing the issues associated with SP's spatial model. Our experimental results demonstrate that our method significantly outperforms SP, achieving state-of-the-art performance in non-fine-tuning retrieval. Furthermore, our approach can enhance performance when used in conjunction with fine-tuned features. Importantly, our method retains high explainability and is lightweight, offering a practical and adaptable solution for a variety of real-world applications.
Towards Content-based Pixel Retrieval in Revisited Oxford and Paris
Sep 11, 2023This paper introduces the first two pixel retrieval benchmarks. Pixel retrieval is segmented instance retrieval. Like semantic segmentation extends classification to the pixel level, pixel retrieval is an extension of image retrieval and offers information about which pixels are related to the query object. In addition to retrieving images for the given query, it helps users quickly identify the query object in true positive images and exclude false positive images by denoting the correlated pixels. Our user study results show pixel-level annotation can significantly improve the user experience. Compared with semantic and instance segmentation, pixel retrieval requires a fine-grained recognition capability for variable-granularity targets. To this end, we propose pixel retrieval benchmarks named PROxford and PRParis, which are based on the widely used image retrieval datasets, ROxford and RParis. Three professional annotators label 5,942 images with two rounds of double-checking and refinement. Furthermore, we conduct extensive experiments and analysis on the SOTA methods in image search, image matching, detection, segmentation, and dense matching using our pixel retrieval benchmarks. Results show that the pixel retrieval task is challenging to these approaches and distinctive from existing problems, suggesting that further research can advance the content-based pixel-retrieval and thus user search experience. The datasets can be downloaded from \href{https://github.com/anguoyuan/Pixel_retrieval-Segmented_instance_retrieval}{this link}.