 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetronome: tracing variation in poetic meters via local sequence alignment
Paper and Code
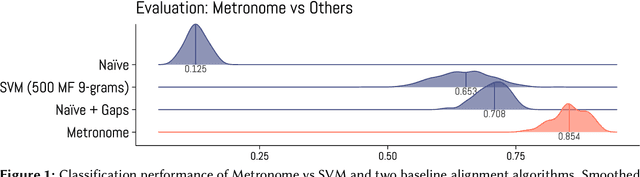
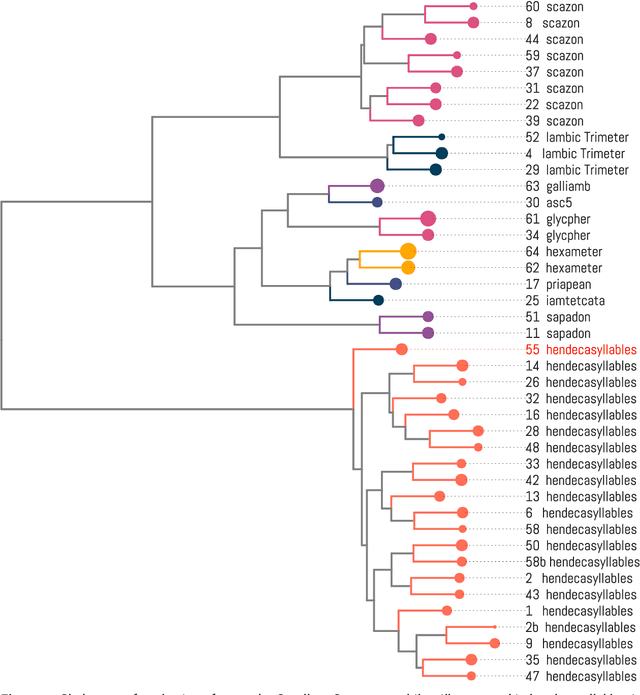

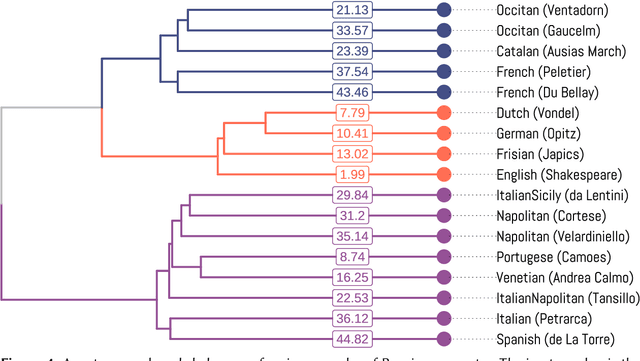
All poetic forms come from somewhere. Prosodic templates can be copied for generations, altered by individuals, imported from foreign traditions, or fundamentally changed under the pressures of language evolution. Yet these relationships are notoriously difficult to trace across languages and times. This paper introduces an unsupervised method for detecting structural similarities in poems using local sequence alignment. The method relies on encoding poetic texts as strings of prosodic features using a four-letter alphabet; these sequences are then aligned to derive a distance measure based on weighted symbol (mis)matches. Local alignment allows poems to be clustered according to emergent properties of their underlying prosodic patterns. We evaluate method performance on a meter recognition tasks against strong baselines and show its potential for cross-lingual and historical research using three short case studies: 1) mutations in quantitative meter in classical Latin, 2) European diffusion of the Renaissance hendecasyllable, and 3) comparative alignment of modern meters in 18--19th century Czech, German and Russian. We release an implementation of the algorithm as a Python package with an open license.